基于Python+ResNet实现的不良图片识别模型
目录
基于 ResNet 的不良图片识别模型 1
摘要 1
介绍 1
研究背景 1
相关研究 2
实验方案 3
数据预处理 3
分类模型 – ResNet 4
网页展示 12
实验 12
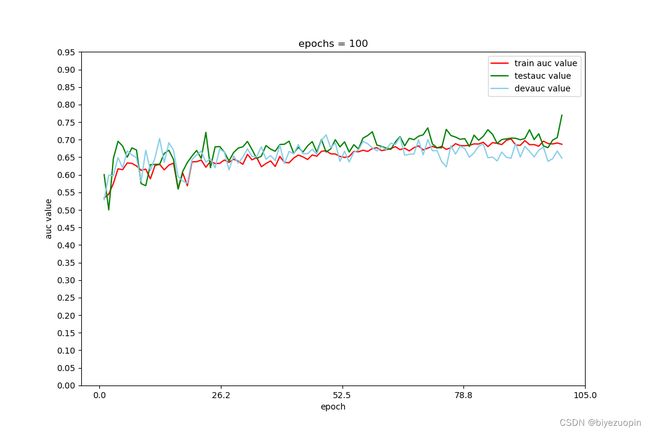
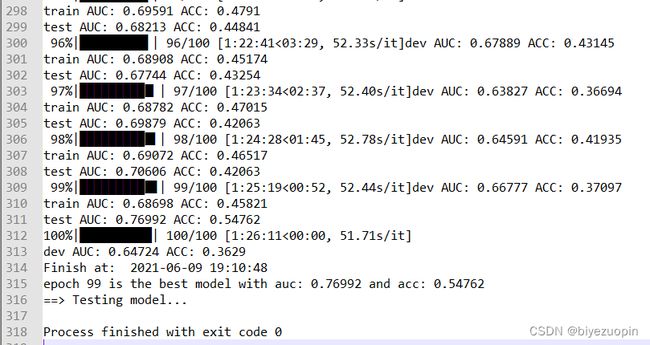
训练情况 13
模型结果分析 18
前端展示 20
总结 26
对项目的理解 26
承担的工作 27
体会 28
参考文献 28
实验方案
数据获取及标注
由于目前网络上缺少一个公开的、具有一定标准的不良图片数据集,故本次实验采用自行获取数据并构建数据集并进行标注的方式。数据获取将结合python opencv库,将收集到的不良视频运用分帧的形式剪切为图片数据集。为保证数据的差异性,选图的决策为每个视频间隔固定时间选取 1 张的方式获取50张图片,即用总帧数除以 50作为选取图片的时间间隔。将得到的图片数据保存到本地,然后以打分的形式人工对所有图片进行标注,所选分值为 0、1、2、3。其中 0代表正常图片,1、2、3代表色情图片,并根据图片色情程度确定图片最终分值,程度越重分值越高。
数据预处理
根据我们的设计,模型有 2分类检测模型和 4分类评级模型,其中 2分类检测模型用于检测输入图片是否含有不良信息,4分类评级模型将用于对图片内容的不良程度进行评估。
根据检测模型与评级模型的区别设计了两种数据集:2 分类检测数据集和 4分类评级数据集。本文转载自http://www.biyezuopin.vip/onews.asp?id=16708其中 2分类检测数据集有两个标签:0表示图像不是不良图像,1表示图像可能含有不良内容;4分类评级数据集有 4个标签,其中 0表示不是不良图像,从 1开始,数字越高表示不良内容越严重。因此,针对 2分类检测数据集的数据标注比较好标,但是针对 4分类评级数据集的数据标注会不可避免地受到人工判断的影响导致标注界限较为模糊,进而影响模型性能,这点我们会在结果分析中进行详细说明。
import torchvision.transforms as transforms
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
import os
import pickle
def prepare_data(in_dir='./data', out_dir='./dataset', batch_size=128):
labels = os.listdir(in_dir)
splited = ['train', 'test', 'dev']
filenums = 0
s1 = 0
s2 = 0
if not os.path.exists(out_dir):
os.mkdir(out_dir)
for kind in splited:
dir_name = os.path.join(out_dir, kind)
if not os.path.exists(dir_name):
os.mkdir(dir_name)
for label in labels:
path = os.path.join(in_dir, label)
files = os.listdir(path)
filenums += len(files)
s1_ = round(0.8 * len(files))
s1 += s1_
s2_ = round(0.1 * len(files))
s2 += s2_
s2_ += s1_
# 训练集 : 测试集 : 验证集 = 8 : 1 : 1
tar = os.path.join(out_dir, splited[0])
tar = os.path.join(tar, label)
tar = os.path.abspath(tar)
os.mkdir(tar)
for file in files[:s1_]: # 训练集
ori = os.path.join(path, file)
ori = os.path.abspath(ori)
tmp = os.popen('copy {0} {1}'.format(ori, tar))
tar = os.path.join(out_dir, splited[1])
tar = os.path.join(tar, label)
tar = os.path.abspath(tar)
os.mkdir(tar)
for file in files[s1_:s2_]: # 测试集
ori = os.path.join(path, file)
ori = os.path.abspath(ori)
tmp = os.popen('copy {0} {1}'.format(ori, tar))
tar = os.path.join(out_dir, splited[2])
tar = os.path.join(tar, label)
tar = os.path.abspath(tar)
os.mkdir(tar)
for file in files[s2_:]: # 验证集
ori = os.path.join(path, file)
ori = os.path.abspath(ori)
tmp = os.popen('copy {0} {1}'.format(ori, tar))
print('Make data sets successfully!')
print('kinds: {0}\ndata nums: {4}\ntrain nums: {1}\ntest nums: {2}\ndev nums: {3}'
.format(len(labels), s1, s2, filenums-s1 - s2, filenums))
make_data_loader(root_dir=out_dir, batch_size=batch_size)
# for item in splited:
# to_del = os.path.join(out_dir, item)
# to_del = os.path.abspath(to_del)
# tmp = os.popen('rd /s/q {0}'.format(to_del))
print('Make dataloader successfully!')
def make_data_loader(root_dir='./dataset', batch_size=128):
mode = ['train', 'test', 'dev']
h = 56
w = 56
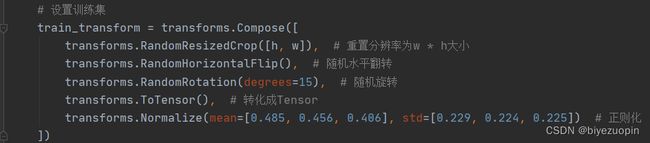
# 设置训练集
train_transform = transforms.Compose([
transforms.RandomResizedCrop([h, w]), # 重置分辨率为w * h大小
transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.RandomRotation(degrees=15), # 随机旋转
transforms.ToTensor(), # 转化成Tensor
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 正则化
])
train_dataset = ImageFolder(os.path.join(root_dir, mode[0]), transform=train_transform) # 训练集数据
train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True, num_workers=0) # 加载数据
to_save = os.path.join(root_dir, 'train_loader.pkl')
with open(to_save, 'wb') as f:
pickle.dump(train_loader, f)
# 设置测试集
test_transform = transforms.Compose([
transforms.Resize([h, w]), # resize到w * h大小
transforms.ToTensor(), # 转化成Tensor
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 正则化
])
test_dataset = ImageFolder(os.path.join(root_dir, mode[1]), transform=test_transform) # 测试集数据
test_loader = DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False, num_workers=0)
to_save = os.path.join(root_dir, 'test_loader.pkl')
with open(to_save, 'wb') as f:
pickle.dump(test_loader, f)
# 设置验证集
dev_transform = transforms.Compose([
transforms.Resize([h, w]), # resize到w * h大小
transforms.ToTensor(), # 转化成Tensor
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 正则化
])
dev_dataset = ImageFolder(os.path.join(root_dir, mode[2]), transform=dev_transform) # 验证集数据
dev_loader = DataLoader(dataset=dev_dataset, batch_size=batch_size, shuffle=False, num_workers=0)
to_save = os.path.join(root_dir, 'dev_loader.pkl')
with open(to_save, 'wb') as f:
pickle.dump(dev_loader, f)
def get_data_loader(in_dir='./data', out_dir='./dataset', batch_size=128):
if not os.path.exists('./dataset/train_loader.pkl'):
prepare_data(in_dir=in_dir, out_dir=out_dir, batch_size=batch_size)
to_load = os.path.join(out_dir, 'train_loader.pkl')
with open(to_load, 'rb') as f:
train_loader = pickle.load(f)
to_load = os.path.join(out_dir, 'test_loader.pkl')
with open(to_load, 'rb') as f:
test_loader = pickle.load(f)
to_load = os.path.join(out_dir, 'dev_loader.pkl')
with open(to_load, 'rb') as f:
dev_loader = pickle.load(f)
return train_loader, test_loader, dev_loader
if __name__ == '__main__':
prepare_data(in_dir='./data', out_dir='./dataset', batch_size=4)