【开源】Transformer 在CV领域全面开花:新出跟踪、分割、配准等总结
本文收录 5 月 以来值得关注的 Transformer 相关开源论文,包括基于 Transformer 的自监督学习方法在 CV 任务中应用、视觉跟踪、视频预测、语义分割、图像配准,以及 1 篇针对 Transformer 风格的网络中,“attention layer”是否是必要的技术报告。
01
Self-Supervised Learning with Swin Transformers
来自清华&西安交通大学&微软亚洲研究
提出以 Vision Transformers 作为骨干架构的自监督学习方法:MoBY,是 MoCo v2 和 BYOL 的结合,经过调整,在 ImageNet-1K 的线性评估上达到了合理的高准确率。通过 300 个周期的训练,使用 DeiT-S 和 Swin-T,分别达到 72.8% 和 75.0% 的 top-1 精度。其性能略优于近期采用 DeiT 为骨干的 MoCo v3 和 DINO 的作品,但其技巧更轻便。
更值得注意是,多功能的 Swin Transformer 骨干可以在下游任务(如目标检测和语义分割)上评估所学到的表征,与最近一些建立在 ViT/DeiT 上的方法相反,由于 ViT/DeiT 没有被驯服用于这些密集的预测任务,因此只能在ImageNet-1K 上报告线性评估结果。
作者称希望该结果可以促进对为 Transformer 架构设计的自监督学习方法进行更全面的评估。
论文链接:https://arxiv.org/abs/2105.04553
项目链接:https://github.com/SwinTransformer/Transformer-SSL

标签:Transformer+自监督学习
02
TrTr: Visual Tracking with Transformer
来自东京大学
东京大学学者提出一种基于强大注意力机制的新型跟踪器网络:Transformer 编码器-解码器架构,以获得全局和丰富的上下文相互依赖关系。在新的架构中,template image(模板图像)的特征由编码器部分的自注意模块处理,可以学习到强大的上下文信息,然后将其发送到解码器部分,以计算与另一个自注意模块处理的搜索图像特征的交叉注意。
此外,设计了分类和回归头,使用 Transformer 的输出,基于状无关的锚进行定位目标。在 VOT2018、VOT2019、OTB-100、UAV、NfS、TrackingNet 和 LaSOT基准上广泛评估了该追踪器 TrTr,与最先进的算法相比表现良好。
论文链接:https://arxiv.org/abs/2105.03817
项目链接:https://github.com/tongtybj/TrTr

标签:Transformer+视觉跟踪
03
Attention for Image Registration (AiR): an unsupervised Transformer approach
来自 Inria&Universit´e Cˆote d’Azur
为了探索图像配准问题的先进学习方法以解决实际问题,作者在本文中提出一种在可变形图像配准问题中引入注意力机制的方法。所提出的方法是基于用 Transformer 框架(AiR)学习变形场,不依赖于CNN,但也可以在GPGPU 设备上有效地训练。或者说将图像配准问题视为与语言翻译任务相同,并引入一个 Transformer 来解决这个问题。所提出方法学习了一个无监督生成的变形图,并在两个基准数据集上进行了测试。
论文链接:https://arxiv.org/abs/2105.02282
项目链接:https://gitlab.inria.fr/zihwang/transformer-for-image-registration

标签:Transformer+图像识别+图像配准
04
Local Frequency Domain Transformer Networks for Video Prediction
来自波恩大学
文章提出 Local Frequency Transformer Networks,完全可解释和轻量级可微模块,用于视频预测任务。并证明该方法很容易扩展到执行运动分割和说明场景的组成,并且通过观察未标记的视频数据,学会以完全可解释的方式产生可靠的预测。
论文链接:https://arxiv.org/abs/2105.04637
项目链接:https://github.com/AIS-Bonn/Local_Freq_Transformer_Net

标签:Transformer+视频预测
05
Segmenter: Transformer for Semantic Segmentation
来自 Inria
提出一个基于 Vision Transformer(ViT)的新的语义分割方法,无需卷积,通过设计捕获上下文信息,并优于基于 FCN 的方法。一系列具有不同分辨率的模型,从具有最先进的性能到具有快速推理和良好性能的模型,使其在精度和运行时间之间进行权衡。
所提出的基于 transformer 的生成类掩码的解码器,其性能优于线性基线,并可以扩展到执行更普遍的图像分割任务。实验结果也表明所提出方法在具有挑战性的ADE20K数据集上产生了最先进的结果,并在 Pascal Context 和 Cityscapes基准上结果也不差。
论文链接:https://arxiv.org/abs/2105.05633
项目链接:https://github.com/rstrudel/segmenter

标签:Transformer+语义分割
06
Do You Even Need Attention? A Stack of Feed-Forward Layers Does Surprisingly Well on ImageNet
来自牛津大学
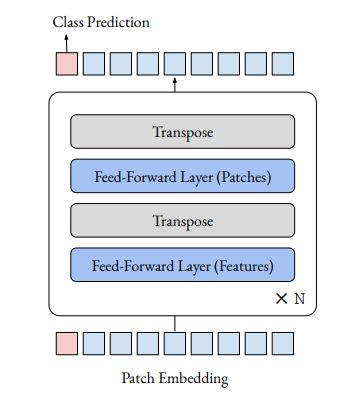
vision transformers 在图像分类和其他视觉任务上的强大性能常常被归因于其多头 attention(注意力)层的设计。然而,注意力在多大程度上负责这种强大的性能仍然不清楚。
在本篇简短报告中,针对“注意力层到底有没有必要”这一问题进行讨论研究。具体来说,用应用在补丁维度上的前馈层取代了 vision transformer 中的注意层。由此产生的架构只是一系列以交替方式应用于补丁和特征维度的前馈层。在 ImageNet 的实验中,该架构的表现出乎意料的好:一个以 ViT/DeiT 为基础的模型获得了 74.9% 的top-1 精度,而 ViT 和 DeiT 的精度分别为 77.9% 和 79.9%。
结果表明,除注意力外,vision transformer 的其他方面,如 patch embedding(斑块嵌入),可能比以前认为的要对其强大的性能有效。作者希望这些结果能促使社会各界花更多的时间去了解为什么当前模型会有如此的效果。
论文链接:https://arxiv.org/abs/2105.02723
项目链接:https://github.com/lukemelas/do-you-even-need-attention
标签:attention+transformer
- END -
编译:CV君
转载请联系本公众号授权

备注:TFM

Transformer交流群
Transformer等最新资讯,若已为CV君其他账号好友请直接私信。
在看,让更多人看到 