Meanshift学习(1)
哎,不想学习,就炒炒冷饭,写写博客,总结一下!
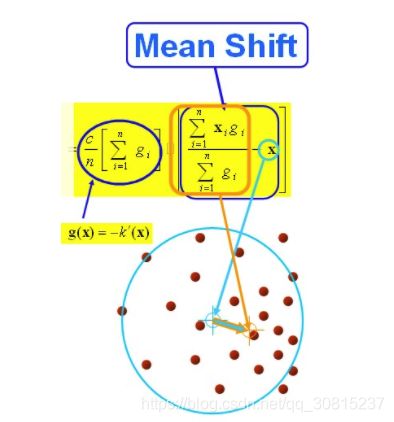
Mean Shift算法,一般是指一个迭代的步骤,即先算出当前点的偏移均值,移动该点到其偏移均值,然后以此为新的起始点,继续移动,直到满足一定的条件结束。Mean shift 算法是基于核密度估计的爬山算法,可用于聚类、图像分割、跟踪等。
1. Meanshift推导
给定d维空间的n个数据点集X,那么对于空间中的任意点x的mean shift向量基本形式可以表示为:
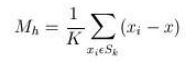
这个向量就是漂移向量,其中Sk表示的是数据集的点到x的距离小于球半径h的数据点,实质上,Sk是一个半径为h的高维球区域,满足以下关系的y点的集合:
![]()
通俗的将就是:在d维空间中,任选一个点,然后以这个点为圆心,h为半径做一个高维球,因为有d维,d可能大于2,所以是高维球。落在这个球内的所有点和圆心都会产生一个向量,向量是以圆心为起点落在球内的点位终点。然后把这些向量都相加。相加的结果就是Meanshift向量。而漂移的过程,说的简单一点,就是通过计算得Meanshift漂移向量,然后把球圆心x的位置更新一下,更新公式为:
![]()
使得圆心的位置一直处于力的平衡位置。

再以meanshift向量的终点为圆心,再做一个高维的球。如下图所以,重复以上步骤,就可得到一个meanshift向量。如此重复下去,meanshift算法可以收敛到概率密度最大得地方。也就是最稠密的地方。

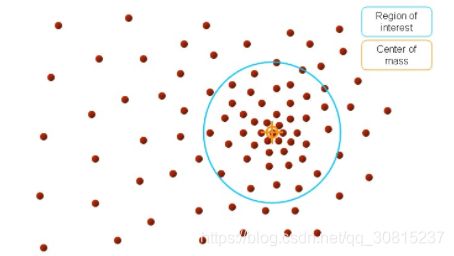
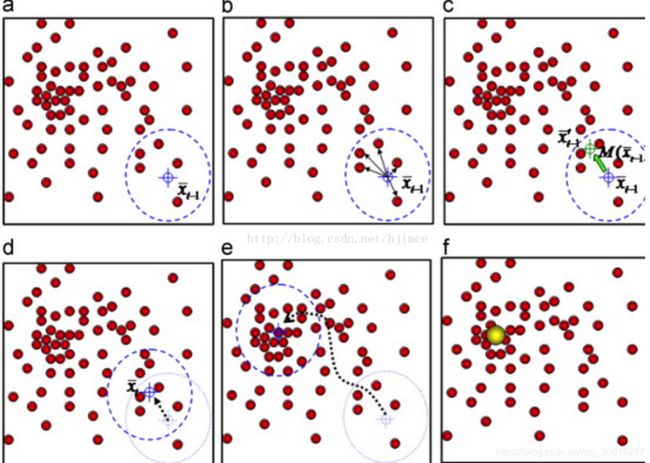
总结为一句话就是:求解一个向量,使得圆心一直往数据集密度最大的方向移动。说的再简单一点,就是每次迭代的时候,都是找到圆里面点的平均位置作为新的圆心位置。
为漂移向量加入核函数
把基本的meanshift向量加入核函数,核函数的性质在这篇博客介绍:http://www.cnblogs.com/liqizhou/archive/2012/05/11/2495788.html
这个说的简单一点就是加入一个高斯权重,能够使距离中心点更近的点具有更大的权值。最后的漂移向量计算公式为:

因此每次更新的圆心坐标为:
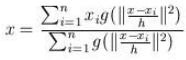
推导:
下面具体给出它的算法流程。
1.选择空间中x为圆心,以h为半径为半径,做一个高维球,落在所有球内的所有点xi
2. 计算![]() ,如果
,如果![]() <ε(人工设定),推出程序。如果
<ε(人工设定),推出程序。如果![]() >ε, 则计算新圆心坐标x,重复执行1。
>ε, 则计算新圆心坐标x,重复执行1。
meanshift在图像上的聚类:
一般一个图像就是个矩阵,像素点均匀的分布在图像上,就没有点的稠密性。怎样来定义点的概率密度,这才是最关键的。点x的概率密度,采用的方法如下:以x为圆心,以h为半径。落在球内的点位xi 定义二个模式规则。
(1)x像素点的颜色与xi像素点颜色越相近,我们定义概率密度越高。
(2)离x的位置越近的像素点xi,定义概率密度越高。
所以定义总的概率密度,是二个规则概率密度乘积的结果:
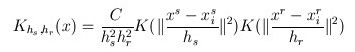
其中:![]() 代表空间位置的信息,离远点越近,其值就越大,
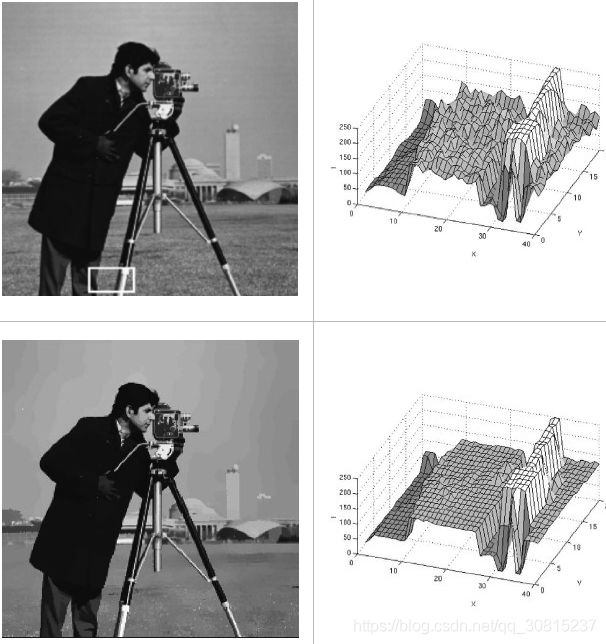
代表空间位置的信息,离远点越近,其值就越大,![]() 表示颜色信息,颜色越相似,其值越大。如图左上角图片,计算的概率密度如图右上。利用meanshift对其聚类,可得到左下角的图。
表示颜色信息,颜色越相似,其值越大。如图左上角图片,计算的概率密度如图右上。利用meanshift对其聚类,可得到左下角的图。
from:http://www.cnblogs.com/liqizhou/archive/2012/05/12/2497220.html
mean shift 聚类流程:
假设在一个多维空间中有很多数据点需要进行聚类,Mean Shift的过程如下:
1、在未被标记的数据点中随机选择一个点作为中心center;
2、找出离center距离在bandwidth之内的所有点,记做集合M,认为这些点属于簇c。同时,把这些求内点属于这个类的概率加1,这个参数将用于最后步骤的分类
3、以center为中心点,计算从center开始到集合M中每个元素的向量,将这些向量相加,得到向量shift。
4、center = center+shift。即center沿着shift的方向移动,移动距离是||shift||。
5、重复步骤2、3、4,直到shift的大小很小(就是迭代到收敛),记住此时的center。注意,这个迭代过程中遇到的点都应该归类到簇c。
6、如果收敛时当前簇c的center与其它已经存在的簇c2中心的距离小于阈值,那么把c2和c合并。否则,把c作为新的聚类,增加1类。
6、重复1、2、3、4、5直到所有的点都被标记访问。
7、分类:根据每个类,对每个点的访问频率,取访问频率最大的那个类,作为当前点集的所属类。
简单的说,mean shift就是沿着密度上升的方向寻找同属一个簇的数据点。
meanshift 聚类实现
Mean shift 算法不需要指定聚类个数,贴一下用matlab实现的聚类结果:
clc
close all;
clear
profile on
%生成随机数据点集
nPtsPerClust = 250;
nClust = 3;
totalNumPts = nPtsPerClust*nClust;
m(:,1) = [1 1]';
m(:,2) = [-1 -1]';
m(:,3) = [1 -1]';
var = .6;
bandwidth = .75;
clustMed = [];
x = var*randn(2,nPtsPerClust*nClust);
for i = 1:nClust
x(:,1+(i-1)*nPtsPerClust:(i)*nPtsPerClust) = x(:,1+(i-1)*nPtsPerClust:(i)*nPtsPerClust) + repmat(m(:,i),1,nPtsPerClust);
end
data=x';
% plot(data(:,1),data(:,2),'.')
%mean shift 算法
[m,n]=size(data);
index=1:m;
radius=0.75;
stopthresh=1e-3*radius;
visitflag=zeros(m,1);%标记是否被访问
count=[];
clustern=0;
clustercenter=[];
hold on;
while length(index)>0
cn=ceil((length(index)-1e-6)*rand);%随机选择一个未被标记的点,作为圆心,进行均值漂移迭代
center=data(index(cn),:);
this_class=zeros(m,1);%统计漂移过程中,每个点的访问频率
%步骤2、3、4、5
while 1
%计算球半径内的点集
dis=sum((repmat(center,m,1)-data).^2,2);
radius2=radius*radius;
innerS=find(dis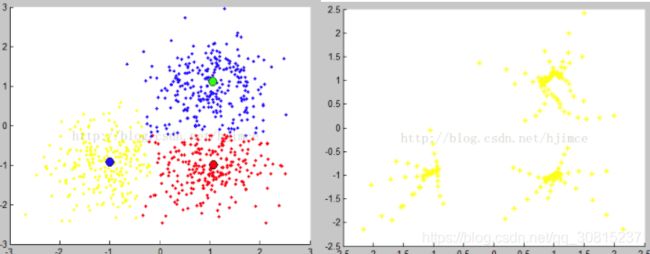
from:https://blog.csdn.net/hjimce/article/details/45718593