神经网络常用层快速理解
本文会先对几个常见的层进行介绍,最后通过一个神经网络进行实现
1.卷积层
卷积层的作用主要是大大降低网络参数,保证网络的稀疏性,防止过拟合,至于为什么会有这些作用,看下面的卷积操作:
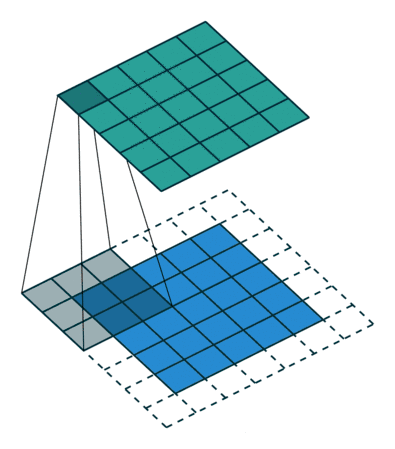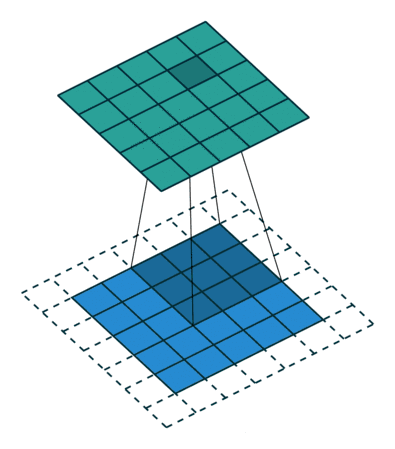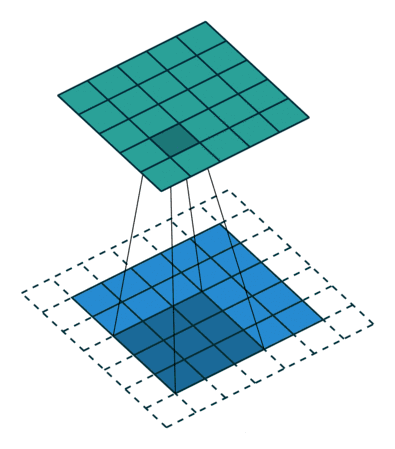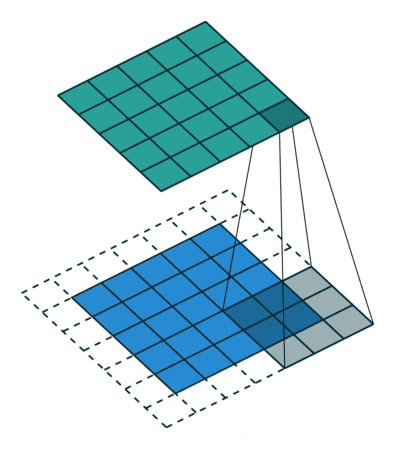
蓝色区域为原始的数据(比如图像数据),虚线部分为进行额外添加的数据(默认情况下添加的都是0),蓝色区域上的灰色部分是卷积核(3×3矩阵)。卷积核从左上到右下依次扫描整个蓝色的数据,扫到一个地方时用蓝色区域的值分别乘卷积核对应的值,最后相加, 得到绿色区域上灰色的部分。显然,卷积操作使得样本局部相关,从而有上面提到的特性。代码如下(可跳过):
import torch
import torch.nn.functional as F
# 创建两个二维张量
input = torch.tensor([[1, 2, 3, 4, 5],
[1, 2, 3, 4, 5],
[1, 2, 3, 4, 5],
[1, 2, 3, 4, 5],
[1, 2, 3, 4, 5]])
kernel = torch.tensor([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
# conv2d对input有shape的要求,因此先进行shape的变化
input = torch.reshape(input, (1, 1, 5, 5)) # channel, batchsize, height, weith
kernel = torch.reshape(kernel, (1, 1, 3, 3))
output = F.conv2d(input, kernel, stride=1)
# conv2d有很多的参数,例如:
# stride:每一步需要跨过的步长
# padding:当为1时,在源图像的上下左右填充0;当为0时,就不进行填充
# dilation:空洞卷积,默认为1即正常没有间隔
# ceil_model:True时,保留不足卷积核大小的数据进行操作
print(output)上述代码使用的卷积操作是conv2d,是专门对2D的数据进行卷积处理的,pytorch还提供了很多卷积操作的函数,具体可见torch.nn.functional — PyTorch 1.11.0 documentation
2.池化层
池化层的主要作用就是减小数据量,使计算更加简单。不难理解,对图像进行池化操作的结果,就像是对图像打了马赛克一样。池化操作有很多类型,常见的MaxPool的操作如下:
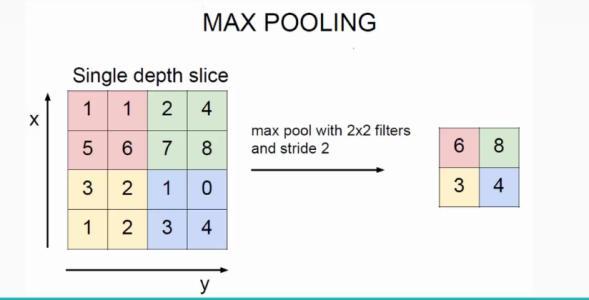
上图中,操作核的大小为2×2,对每2×2的地方都会取最大值,从而实现最大池化。pytorch还提供了最小池化,均值池化等操作,可以见网站torch.nn.functional — PyTorch 1.11.0 documentation
简单实现的代码如下(可跳过):
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 这两行是加载数据集并进行loader的操作,没有基础的同学可以不管看下面
dataset = torchvision.datasets.CIFAR10("../data", False, download=True, transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)
# input是一个张量,并进行reshape使得其大小5×5,通道数channel为1,batch_size自行调整(-1)
input1 = torch.tensor([[1, 2, 3, 4, 5],
[1, 2, 3, 4, 5],
[1, 2, 3, 4, 5],
[1, 2, 3, 4, 5],
[1, 2, 3, 4, 5]], dtype=torch.float32)
input1 = torch.reshape(input1, (-1, 1, 5, 5))
# 定义神经网络,里面进行的是最大池化
class Bao(nn.Module):
def __init__(self):
super(Bao, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=True)
def forward(self, input):
output = self.maxpool1(input)
return output
bao = Bao()
# 对上面的图像进行神经网络的处理,处理后的图像可以在tensorboard中查看,没有基础的同学依然可以和上面dataset一样直接跳过
step = 0
writer = SummaryWriter("logs_maxpool")
for data in dataloader:
imgs, targets = data
output = bao(imgs)
writer.add_images("output", output, step)
step = step + 1
writer.close()
# 将input放入神经网络处理,并输出
output1 = bao(input1)
print(output1)3.非线性变换
非线性变换可以给图像引入非线性的特征,更利于学习出特点。
非线性变换就是将输入进行非线性处理,常见的非线性变换函数是ReLU,Sigmoid等
ReLU:
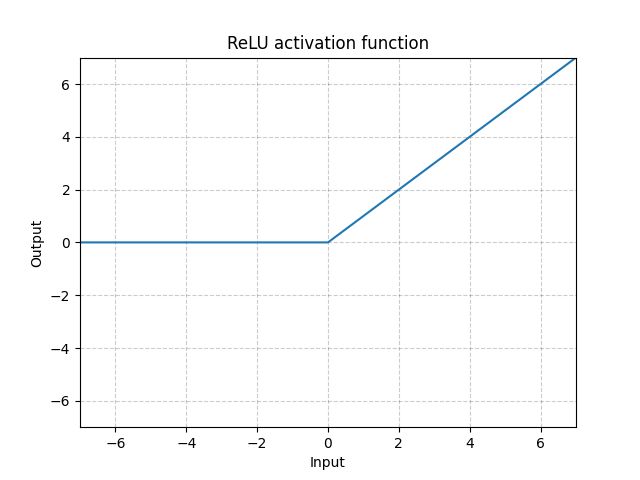
例如,输入为-1,结果就是0,输入为1,结果就是1.
Sigmoid:
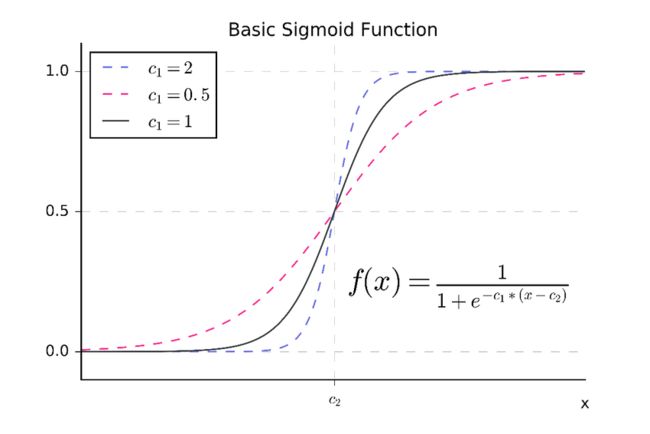
代码实现(也很简单可以不看):
import torch
from torch import nn
# 定义张量,并改变shape便于放在ReLU函数中
input = torch.tensor([[1, -0.5], [-1, 3]])
input = torch.reshape(input, (-1, 1, 2, 2))
# 定义神经网络
class Bao(nn.Module):
def __init__(self):
super(Bao, self).__init__()
self.relu = nn.ReLU()
# 参数inplace:当为True时,直接将运算结果替换输入的数,会丢失原来的数。当为Flase,则需要进行赋值,默认为False
def forward(self, input):
output = self.relu(input)
return output
bao = Bao()
output = bao(input)
print(output)4.线性变换
线性变换就是对n个数据x,通过y = kx + b的操作得到m个数据y,得到多少个数据y可以在线性变换函数的参数中自己设定,假设只需要得到一个y(m=1),那么这个y就等于Σi=1~n(kixi+bi)
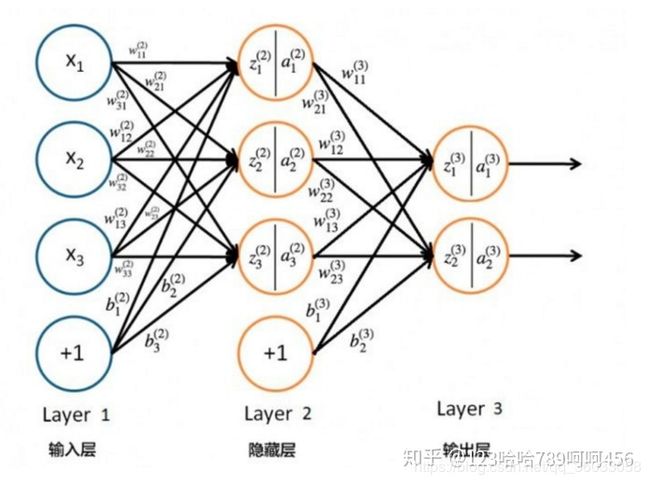
上图中,输入层通过一次线性变换得到隐藏层,隐藏层再通过一次线性变换就可以得到输出层。
代码实现(选看):
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("../data", train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Bao(nn.Module):
def __init__(self):
super(Bao, self).__init__()
self.linear = nn.Linear(196608, 10) # 196608是输入经过flatten之后的维度
def forward(self, input):
output = self.linear(input)
return output
bao = Bao()
for data in dataloader:
imgs, targets = data
input = torch.flatten(imgs) # 变为1行
output = bao(input)
print(output.shape)总结至此,我们已经将几个常见的层全部介绍完了,可以看看下面的实现:
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.tensorboard import SummaryWriter
class Bao(nn.Module):
def __init__(self):
super(Bao, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, kernel_size=(5, 5), padding=2), # 卷积,变为32个channel
MaxPool2d(2), # 池化,尺寸缩小一倍
Conv2d(32, 32, 5, padding=2), # 卷积,channel和尺寸不变
MaxPool2d(2), # 池化, 尺寸缩小一倍
Conv2d(32, 64, 5, padding=2), #卷积, channel变为64
MaxPool2d(2), # 池化,尺寸缩小一倍
Flatten(), # 展平,方便线性变换
Linear(1024, 64), # 线性变换,将1024个x变为64个y
Linear(64, 10) # 线性变换,将64个x变为10个y
)
def forward(self, x):
x = self.model1(x)
return x
bao = Bao()
input = torch.ones((64, 3, 32, 32))
output = bao(input)
print(output)
writer = SummaryWriter("12-logs")
writer.add_graph(bao, input)
writer.close()