Transformer原理及代码注释(Attention is all you need)
Transformer是谷歌针对NLP的机器翻译问题,2017年发表了一篇名为Attention Is All You Need 的论文中提出的模型。Transformer采用了机器翻译中通用的encoder-decoder模型,但摒弃了以往模块内部的RNN模型,只是完全依赖注意力机制来构建模型。其优点有以下几点:
- 结构简单,抛弃RNN模型的优点在于没有了时序的限制,RNN限制了数据必须按照输入的顺序处理前后有依赖性,所以在面对数据量大的时候,耗时会很长。但Transformer的self-attention机制使得其可以进行并行计算来加速
- 每个单词会考虑句子中所有词对其的影响,一定程度上改善了RNN中由于句子过长带来的误差,Transformer的翻译结果要比RNN好很多
下面会从原理和代码来解读Transformer模型:
1 Transformer 原理
首先按惯例上模型图(

显然其可以分成左右两部分,为了方便理解,我们把左边叫做Encoders,右边叫做Decoders。上图只是模型的示意图,实际上这两个部分分别由六个图示这样的基本结构堆叠起来,像这样:

为了更好的理解,我们按照数据输入之后在模型中的行走路线解释模型的原理。
0 位置编码
由于机器翻译需要考虑词序之间的关系,而且attention机制并没有考虑词序关系,所以我们要提前为单词加上位置编码,使得模型可以利用输入序列的顺序信息。位置编码的编码规则如下所示:
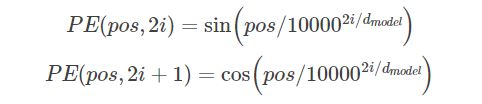
如果我们emdedding的维度为4,那么示例可以像下图(

1.1 Encoder

Encoder的作用是将输入经过注意力机制和前馈神经网络转变成编码,后期作为输入传入Decoder解码成另一种语言。输入的字符串已经预先变成了词嵌入矩阵形式(论文中使用的词向量维数是512维),词嵌入矩阵被输入最底层的Encoder,然后将其拆分成向量输入attention层进行计算,Attention层会输出同样是512维的向量列表,这两个矩阵经过多头Attention机制的整合,再进入前馈神经网络,前馈神经网络也输出一个为512维度的列表,然后将输出传到下一个Encoder。注意,每个Encoder模块的前馈神经网络都是独立且结构相同的。(给并行创造条件)
1.1.1 Transformer的Attention机制
首先我们先来看Attention部分,模型的attention其实由两部分组成:

1.1.1.1 Scaled Dot-Product Attention
首先是朴素的一看就不是并行的部分:D
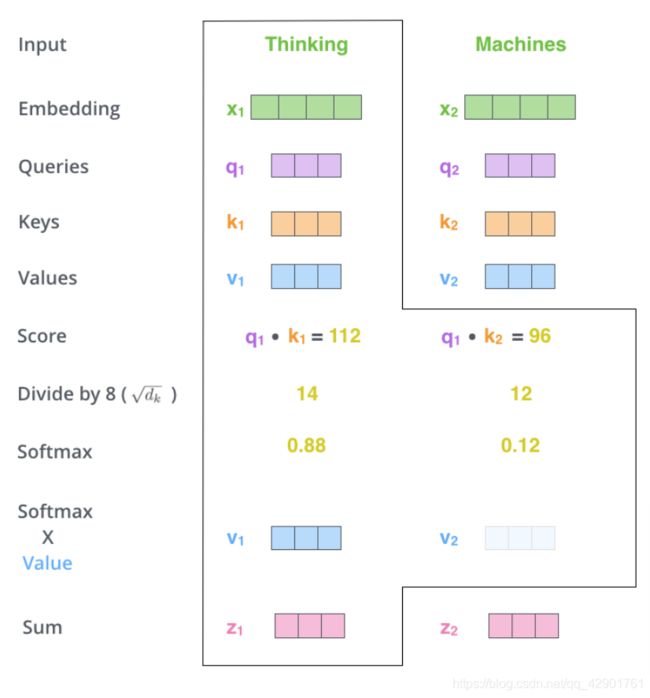
计算self-attention首先从计算三个向量开始,对于每一个单词,我们都需要三个向量:Query, Key, Value。这些向量是通过当前单词与分别的训练矩阵相乘得到的,维度自拟(这里是64维)。另外,训练矩阵在这里假设是已经训练好给定的,具体来源我们下一节再解释。
然后有了材料我们就可以套公式了(雾):

首先我们用Q,K相乘得到的结果来相应单词的得分,举例如上上图,然后将得分除以8,也就是 s q r t ( d k ) sqrt(d_k) sqrt(dk),使得训练过程中具有更稳定的梯度(论文中说:对于 d k d_k dk很大的时候,点积得到的结果维度很大,使得结果处于softmax函数梯度很小的区域,这造成梯度很小,对反向传播不利。为了克服这个负面影响,除以一个缩放因子,可以一定程度上减缓这种情况???)。接下来再将输出乘V过softmax,得到权值的向量,然后将其累加到词向量中,产生此Attention层的输出。通俗来讲,公式大意是通过确定Q和K之间的相似程度来选择V
1.1.1.2 Multi-Head Attention
通过论文的图示,你一定看到了恍若虚影的东西,对,这就是玄学 可以并行计算的部分了。
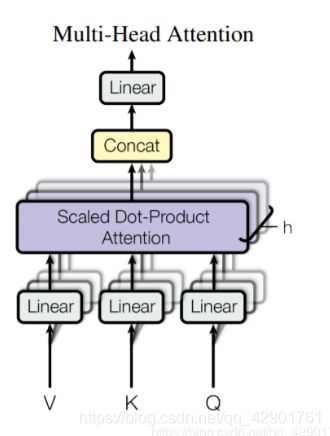
公式如下:

多头Attention提供并训练了多个Q,K,V的训练矩阵,他们用于将词嵌入投影到不同的表示子空间(representation subspaces)中。通过此Attention层,我们为每一个header都独立维护了一套QKV训练矩阵,在经过上一节的attention层处理之后,因为我们有多个并行的attention,所以肯定会得到多个不同的Z矩阵,然后我们通过concat函数(将这几个矩阵简单相拼接)组合成一个大矩阵,之后与 W O W^O WO相乘,过线性模型得到的结果就可以进入前馈神经网络了。
下面是Attention过程的总结:

1.1.2 前馈神经网络
这是一个Position-wise的前馈神经网络,激活函数的顺序是线性模型-RELU-线性模型:

1.1.3 layer-normalization

可以看到,词向量除了喂入attention模型之外,还另外在喂入前馈神经网络中与Z进行了整合。
1.2 Decoder
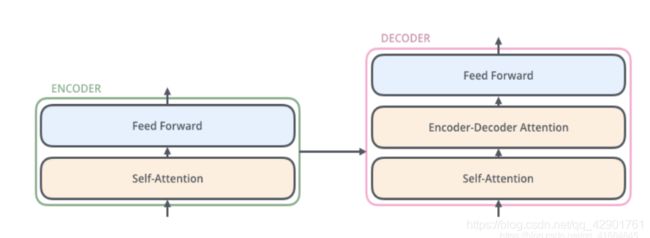
Decoder的结构与Encoder其实是非常像的,只是多了一层E-D Attention机制,为了让decoder捕获输入序列的位置信息。但是与Encoder不同,Decoder的每一次输出都作为下一次的时序的输入,进入最底层的decoder:

另外,decoder的attention机制是按照输出序列中出现比较早的位置来排序的,与乱序的encoder不同。
1.3 输出
Decoder的输出是一个浮点数的向量列表,我们需要再将其通过线性层和softmax才可以将其变成输出的单词:

2 代码注释
'''
code by Tae Hwan Jung(Jeff Jung) @graykode, Derek Miller @dmmiller612
Reference : https://github.com/jadore801120/attention-is-all-you-need-pytorch
https://github.com/JayParks/transformer
'''
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable
import matplotlib.pyplot as plt
dtype = torch.FloatTensor
# S: Symbol that shows starting of decoding input
# E: Symbol that shows starting of decoding output
# P: Symbol that will fill in blank sequence if current batch data size is short than time steps
sentences = ['ich mochte ein bier P', 'S i want a beer', 'i want a beer E']
# Transformer Parameters
# Padding Should be Zero index
src_vocab = {'P' : 0, 'ich' : 1, 'mochte' : 2, 'ein' : 3, 'bier' : 4}
src_vocab_size = len(src_vocab)
tgt_vocab = {'P' : 0, 'i' : 1, 'want' : 2, 'a' : 3, 'beer' : 4, 'S' : 5, 'E' : 6}
number_dict = {i: w for i, w in enumerate(tgt_vocab)}
tgt_vocab_size = len(tgt_vocab)
src_len = 5
tgt_len = 5
d_model = 512 # Embedding Size
d_ff = 2048 # FeedForward dimension
d_k = d_v = 64 # dimension of K(=Q), V
n_layers = 6 # number of Encoder of Decoder Layer
n_heads = 8 # number of heads in Multi-Head Attention
def make_batch(sentences):
input_batch = [[src_vocab[n] for n in sentences[0].split()]]
output_batch = [[tgt_vocab[n] for n in sentences[1].split()]]
target_batch = [[tgt_vocab[n] for n in sentences[2].split()]]
return Variable(torch.LongTensor(input_batch)), Variable(torch.LongTensor(output_batch)), Variable(torch.LongTensor(target_batch))
def get_sinusoid_encoding_table(n_position, d_model):
def cal_angle(position, hid_idx):
return position / np.power(10000, 2 * (hid_idx // 2) / d_model)
def get_posi_angle_vec(position):
return [cal_angle(position, hid_j) for hid_j in range(d_model)]
sinusoid_table = np.array([get_posi_angle_vec(pos_i) for pos_i in range(n_position)])
sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) # dim 2i
sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2]) # dim 2i+1
return torch.FloatTensor(sinusoid_table)
def get_attn_pad_mask(seq_q, seq_k):
# print(seq_q)
batch_size, len_q = seq_q.size()
batch_size, len_k = seq_k.size()
# eq(zero) is PAD token
pad_attn_mask = seq_k.data.eq(0).unsqueeze(1) # batch_size x 1 x len_k(=len_q), one is masking
return pad_attn_mask.expand(batch_size, len_q, len_k) # batch_size x len_q x len_k
def get_attn_subsequent_mask(seq):
attn_shape = [seq.size(0), seq.size(1), seq.size(1)]
subsequent_mask = np.triu(np.ones(attn_shape), k=1)
subsequent_mask = torch.from_numpy(subsequent_mask).byte()
return subsequent_mask
##Encoder attention-1
class ScaledDotProductAttention(nn.Module):
def __init__(self):
super(ScaledDotProductAttention, self).__init__()
def forward(self, Q, K, V, attn_mask):
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k)
# scores : [batch_size x n_heads x len_q(=len_k) x len_k(=len_q)]
scores.masked_fill_(attn_mask, -1e9)
# Fills elements of self tensor with value where mask is one.
attn = nn.Softmax(dim=-1)(scores)
context = torch.matmul(attn, V)
return context, attn
##Encoder attention-2
class MultiHeadAttention(nn.Module):
def __init__(self):
super(MultiHeadAttention, self).__init__()
self.W_Q = nn.Linear(d_model, d_k * n_heads)
self.W_K = nn.Linear(d_model, d_k * n_heads)
self.W_V = nn.Linear(d_model, d_v * n_heads)
def forward(self, Q, K, V, attn_mask):
# q: [batch_size x len_q x d_model], k: [batch_size x len_k x d_model], v: [batch_size x len_k x d_model]
residual, batch_size = Q, Q.size(0)
# (B, S, D) -proj-> (B, S, D) -split-> (B, S, H, W) -trans-> (B, H, S, W)
q_s = self.W_Q(Q).view(batch_size, -1, n_heads, d_k).transpose(1,2) # q_s: [batch_size x n_heads x len_q x d_k]
k_s = self.W_K(K).view(batch_size, -1, n_heads, d_k).transpose(1,2) # k_s: [batch_size x n_heads x len_k x d_k]
v_s = self.W_V(V).view(batch_size, -1, n_heads, d_v).transpose(1,2) # v_s: [batch_size x n_heads x len_k x d_v]
attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1) # attn_mask : [batch_size x n_heads x len_q x len_k]
# context: [batch_size x n_heads x len_q x d_v], attn: [batch_size x n_heads x len_q(=len_k) x len_k(=len_q)]
context, attn = ScaledDotProductAttention()(q_s, k_s, v_s, attn_mask)
context = context.transpose(1, 2).contiguous().view(batch_size, -1, n_heads * d_v) # context: [batch_size x len_q x n_heads * d_v]
output = nn.Linear(n_heads * d_v, d_model)(context)
return nn.LayerNorm(d_model)(output + residual), attn # output: [batch_size x len_q x d_model]
##前馈神经网络 Position-wise版
class PoswiseFeedForwardNet(nn.Module):
def __init__(self):
super(PoswiseFeedForwardNet, self).__init__()
self.conv1 = nn.Conv1d(in_channels=d_model, out_channels=d_ff, kernel_size=1)
self.conv2 = nn.Conv1d(in_channels=d_ff, out_channels=d_model, kernel_size=1)
def forward(self, inputs):
residual = inputs # inputs : [batch_size, len_q, d_model]
output = nn.ReLU()(self.conv1(inputs.transpose(1, 2)))
output = self.conv2(output).transpose(1, 2)
return nn.LayerNorm(d_model)(output + residual)
#Encoder 基本模块
class EncoderLayer(nn.Module):
def __init__(self):
super(EncoderLayer, self).__init__()
self.enc_self_attn = MultiHeadAttention()
self.pos_ffn = PoswiseFeedForwardNet()
def forward(self, enc_inputs, enc_self_attn_mask):
enc_outputs, attn = self.enc_self_attn(enc_inputs, enc_inputs, enc_inputs, enc_self_attn_mask) # enc_inputs to same Q,K,V
enc_outputs = self.pos_ffn(enc_outputs) # enc_outputs: [batch_size x len_q x d_model]
return enc_outputs, attn
#Decoder 基本模块
class DecoderLayer(nn.Module):
def __init__(self):
super(DecoderLayer, self).__init__()
self.dec_self_attn = MultiHeadAttention()
self.dec_enc_attn = MultiHeadAttention()
self.pos_ffn = PoswiseFeedForwardNet()
def forward(self, dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask):
dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs, dec_inputs, dec_self_attn_mask)
dec_outputs, dec_enc_attn = self.dec_enc_attn(dec_outputs, enc_outputs, enc_outputs, dec_enc_attn_mask)
dec_outputs = self.pos_ffn(dec_outputs)
return dec_outputs, dec_self_attn, dec_enc_attn
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.src_emb = nn.Embedding(src_vocab_size, d_model)
self.pos_emb = nn.Embedding.from_pretrained(get_sinusoid_encoding_table(src_vocab_size, d_model),freeze=True)
self.layers = nn.ModuleList([EncoderLayer() for _ in range(n_layers)])
def forward(self, enc_inputs): # enc_inputs : [batch_size x source_len]
enc_outputs = self.src_emb(enc_inputs) + self.pos_emb(torch.LongTensor([[1,2,3,4,0]]))
enc_self_attn_mask = get_attn_pad_mask(enc_inputs, enc_inputs)
enc_self_attns = []
for layer in self.layers:
enc_outputs, enc_self_attn = layer(enc_outputs, enc_self_attn_mask)
enc_self_attns.append(enc_self_attn)
return enc_outputs, enc_self_attns
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.tgt_emb = nn.Embedding(tgt_vocab_size, d_model)
self.pos_emb = nn.Embedding.from_pretrained(get_sinusoid_encoding_table(tgt_vocab_size, d_model),freeze=True)
self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)])
def forward(self, dec_inputs, enc_inputs, enc_outputs): # dec_inputs : [batch_size x target_len]
dec_outputs = self.tgt_emb(dec_inputs) + self.pos_emb(torch.LongTensor([[5,1,2,3,4]]))
dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs)
dec_self_attn_subsequent_mask = get_attn_subsequent_mask(dec_inputs)
dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequent_mask), 0)
dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs)
dec_self_attns, dec_enc_attns = [], []
for layer in self.layers:
dec_outputs, dec_self_attn, dec_enc_attn = layer(dec_outputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask)
dec_self_attns.append(dec_self_attn)
dec_enc_attns.append(dec_enc_attn)
return dec_outputs, dec_self_attns, dec_enc_attns
##主模型
class Transformer(nn.Module):
def __init__(self):
super(Transformer, self).__init__()
self.encoder = Encoder()
self.decoder = Decoder()
self.projection = nn.Linear(d_model, tgt_vocab_size, bias=False)
def forward(self, enc_inputs, dec_inputs):
enc_outputs, enc_self_attns = self.encoder(enc_inputs)
dec_outputs, dec_self_attns, dec_enc_attns = self.decoder(dec_inputs, enc_inputs, enc_outputs)
dec_logits = self.projection(dec_outputs) # dec_logits : [batch_size x src_vocab_size x tgt_vocab_size]
return dec_logits.view(-1, dec_logits.size(-1)), enc_self_attns, dec_self_attns, dec_enc_attns
## 贪婪算法 模型损失函数和翻译矩阵的训练
###https://blog.csdn.net/qq_41664845/article/details/84969266
def greedy_decoder(model, enc_input, start_symbol):
"""
For simplicity, a Greedy Decoder is Beam search when K=1. This is necessary for inference as we don't know the
target sequence input. Therefore we try to generate the target input word by word, then feed it into the transformer.
Starting Reference: http://nlp.seas.harvard.edu/2018/04/03/attention.html#greedy-decoding
:param model: Transformer Model
:param enc_input: The encoder input
:param start_symbol: The start symbol. In this example it is 'S' which corresponds to index 4
:return: The target input
"""
enc_outputs, enc_self_attns = model.encoder(enc_input)
dec_input = torch.zeros(1, 5).type_as(enc_input.data)
next_symbol = start_symbol
for i in range(0, 5):
dec_input[0][i] = next_symbol
dec_outputs, _, _ = model.decoder(dec_input, enc_input, enc_outputs)
projected = model.projection(dec_outputs)
prob = projected.squeeze(0).max(dim=-1, keepdim=False)[1]
next_word = prob.data[i]
next_symbol = next_word.item()
return dec_input
def showgraph(attn):
attn = attn[-1].squeeze(0)[0]
attn = attn.squeeze(0).data.numpy()
fig = plt.figure(figsize=(n_heads, n_heads)) # [n_heads, n_heads]
ax = fig.add_subplot(1, 1, 1)
ax.matshow(attn, cmap='viridis')
ax.set_xticklabels(['']+sentences[0].split(), fontdict={'fontsize': 14}, rotation=90)
ax.set_yticklabels(['']+sentences[2].split(), fontdict={'fontsize': 14})
plt.show()
model = Transformer()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
for epoch in range(20):
optimizer.zero_grad()
enc_inputs, dec_inputs, target_batch = make_batch(sentences)
outputs, enc_self_attns, dec_self_attns, dec_enc_attns = model(enc_inputs, dec_inputs)
loss = criterion(outputs, target_batch.contiguous().view(-1))
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))
loss.backward()
optimizer.step()
# Test
greedy_dec_input = greedy_decoder(model, enc_inputs, start_symbol=tgt_vocab["S"])
predict, _, _, _ = model(enc_inputs, greedy_dec_input)
predict = predict.data.max(1, keepdim=True)[1]
print(sentences[0], '->', [number_dict[n.item()] for n in predict.squeeze()])
print('first head of last state enc_self_attns')
showgraph(enc_self_attns)
print('first head of last state dec_self_attns')
showgraph(dec_self_attns)
print('first head of last state dec_enc_attns')
showgraph(dec_enc_attns)