Keypoint NeRF 笔记
Keypoint NeRF 笔记
《KeypointNeRF: Generalizing Image-based Volumetric Avatars using Relative Spatial Encoding of Keypoints》
主页:https://markomih.github.io/KeypointNeRF/
论文:https://arxiv.org/abs/2205.04992
看这篇主要是想看他是怎么用关键点建立坐标系,怎么用关键点产生位置编码的
他的关键点是用的现有的人脸(人体)关键点检测器找的,而不是自监督或者端到端找的
似乎仍然需要相机外参来确定观察方向(不过关键点都有了,估计反解出外参也不是问题吧)(等等,他是可以用野外图片来重建的,那说明他确实可以自己反解出外参)
用了一个很难理解的,基于当前视角下,采样点与关键点之间的相对深度的位置编码。
这种位置编码着重强调了相对深度(做了傅里叶编码,能靠相对深度产生高频细节),但是弱化了相对距离(只用来加权,这样相对距离的信息就只能产生低频细节),为什么要这样做?
没有做相关的消融实验,可能是作者单纯的没想过这个问题吧?也可能是在模仿某种经典的算法,只是我还不知道。
我觉得一般来说都会先想到对每个关键点配一个可学习编码,然后对相对距离做傅里叶编码,然后把两个编码拼在一起作为位置编码这样的方案吧?
也可能只是我单纯的这方面的论文看少了。
用了 IBRNet 的技术,来融合多视角特征。
用了卷积网络来抽取局部像素特征。
还需要看的论文:PIFu (PIFuHD) , PVA , IBRNet , pixelNeRF
看 IBRNet :方差-均值池化是啥?看了,这个用于融合多视角pixle-aligned特征,把方差和均值和特征向量一起输到一个网络里,输出权重,然后对特征向量做加权和。
看 PIFu (PIFuHD) :camera z encoding 是怎么编码的?看了,他们是单视图,所以只用 z (和pixel-aligned特征)就够了,不需要外参,而且他们的 z 压根就不编码吧
看 PVA :canonical xyz encoding 是怎么编码的?看了,就是直接傅里叶编码
看 [21] (李飞飞的感知损失):这篇好像挺重要的不仅 Keypoint NeRF 用了,PIFuHD 也用了。看了,就是很简单的VGG感知损失。
准备知识:NeRF
按理说这部分我应该跳过,但是他着实讲了一些我很需要的东西。
实际上相关工作里面也有不少值得看一下(不过还没看)。
Pixel-aligned NeRF
NeRF的一个重大限制就是需要对每个场景单独做优化,而且在输入视角极其稀疏的情况下(比如只有两张图片)工作得不太好。
为了解决这一点,一些最近的方法 [41,54,60] 提出,用 pixel-aligned的图像特征 做为 NeRF 的条件(应该就是指监督信息),不需要 重新训练 就能推广到新视角。
空间编码
为了避免 ray-depth 二义性,pixel-aligned 神经场 [41,44,45,60] 将空间编码附着到 pixel-aligned的特征 上。PIFu [44] 和相关方法 [45,60] 使用相机坐标空间中的 深度值 作为空间编码,而 PVA [41] 使用相对于头部位置的坐标。
我们认为,这种空间编码是全局性的,对于学习 可推广的立体人体 不是最优的。相比之下,我们提出了一种相对空间编码,提供局部的上下文,可以学得更好,而且对人类姿势变化更鲁棒。
方法
I n I_n In 表示第 n 张图片, P n P_n Pn 表示第 n 个视角的相机外参
相对空间关键点编码
先找到关键点
用一个现成的关键点回归器 [8] ,从至少两张图中,提取出 K 个 2D 关键点。然后用 direct linear transformation 算法 [14] ,将 2D 关键点提升到三维 P = { p k ∈ R 3 } k = 1 K \mathcal{P}=\left\{p_{k} \in \mathbb{R}^{3}\right\}_{k=1}^{K} P={pk∈R3}k=1K 。
对查询点 X 进行空间编码
先定义 深度值 z ( p k ∣ P n ) z\left(p_{k} \mid P_{n}\right) z(pk∣Pn) ,表示 关键点 p k p_k pk 在 视角 P n P_n Pn 下的深度值。
定义 相对深度差 δ n ( p k , X ) = z ( p k ∣ P n ) − z ( X ∣ P n ) \delta_{n}\left(p_{k}, X\right)=z\left(p_{k} \mid P_{n}\right)-z\left(X \mid P_{n}\right) δn(pk,X)=z(pk∣Pn)−z(X∣Pn) ,表示 关键点 p k p_k pk 与 查询点 X 之间的的深度值之差。
定义 γ ( ⋅ ) \gamma(\cdot) γ(⋅) 为 NeRF 原文中使用的位置编码函数(就是傅里叶编码)。
最终的 相对空间编码 计算如下:
s n ( X ∣ P ) = [ exp ( − l 2 ( p k , X ) 2 2 α 2 ) γ ( δ n ( p k , X ) ) ] k = 1 K s_{n}(X \mid \mathcal{P})=\left[\exp \left(\frac{-l_{2}\left(p_{k}, X\right)^{2}}{2 \alpha^{2}}\right) \gamma\left(\delta_{n}\left(p_{k}, X\right)\right)\right]_{k=1}^{K} sn(X∣P)=[exp(2α2−l2(pk,X)2)γ(δn(pk,X))]k=1K
其中 l 2 ( p k , X ) l_2(p_k,X) l2(pk,X) 应该是在算 L2距离(注意是不开方的,就是单纯的平方和),可以看到这个L2距离过了一遍高斯核,然后和位置编码相乘。
其中 α \alpha α 是一个超参,用于控制关键点之间的紧凑程度,对人脸关键点用的是 5cm ,对人体骨骼用的是 10cm
也就是说,傅里叶编码只编码相对深度差。与关键点的距离只会影响对编码的加权(或者说振幅),对每个关键点,如果离得越近,权重就越大。
卷积 Pixel-aligned 特征
图像编码器
有两个图像编码器,
- 一个 HourGlass 网络 [37] ,提取两个编码,一个深层低分辨率的编码 F n g l ∈ R H / 8 × W / 8 × 64 F_{n}^{g l} \in \mathbb{R}^{H / 8 \times W / 8 \times 64} Fngl∈RH/8×W/8×64 ,一个浅层高分辨率的编码 F n g h ∈ R H / 2 × W / 2 × 8 F_{n}^{g h} \in \mathbb{R}^{H / 2 \times W / 2 \times 8} Fngh∈RH/2×W/2×8 。该网络学习人的几何先验,其输出用来 condition 密度估计网络。
- 一个有残差连接的卷积网络 [21] ,将输入图像编码为 F n a ∈ R H / 4 × W / 4 × 8 F_{n}^{a} \in \mathbb{R}^{H / 4 \times W / 4 \times 8} Fna∈RH/4×W/4×8 。该网络本着 DoubleField [46] 的精神,为外观信息提供一条可选的通路,这个通路与密度估计无关。
Pixel-aligned 特征
为了计算 Pixel-aligned 特征,将查询点投影到特征平面上 x = π ( X ∣ P n ) ∈ R 2 x=\pi\left(X \mid P_{n}\right) \in \mathbb{R}^{2} x=π(X∣Pn)∈R2 ,然后在特征平面上进行双线性插值,得到查询点的特征。
我们将这个操作定义为 Φ n ( X ∣ F ) \Phi_{n}(X \mid F) Φn(X∣F) ,其中 F F F 可以为 F n g l , F n g h , F n a , I n F_{n}^{g l}, F_{n}^{g h}, F_{n}^{a}, I_{n} Fngl,Fngh,Fna,In 。
多视角特征融合
为了建立一个多视角下具有一致性的辐射场,我们需要融合不同视角的空间编码 s n s_n sn 和 pixel-aligned 特征 Φ n \Phi_n Φn 。
先把 s n s_n sn 过一个单层感知机,得到一个特征。然后把该特征和 Φ n ( X ∣ F n g l ) \Phi_n(X \mid F_n^{gl}) Φn(X∣Fngl) 用一个双层感知机混合
,然后把输出和 Φ n ( X ∣ F n g h ) \Phi_n(X \mid F_n^{gh}) Φn(X∣Fngh) 连接到一起,过一个另外的双层感知机,得到单个视角下的64维特征,这样我们就融合了空间编码和 pixel-aligned 特征。
然后我们用均值和方差池化操作 [54] (来自 IBRNet 的技术,感觉很重要,去看看),将多个视角下的特征融合为一个特征 G X ∈ R 128 G_{X} \in \mathbb{R}^{128} GX∈R128 。
这个 G X G_X GX 作为位置编码,融合了多个视角下的 关键点相对位置信息 和 局部像素信息。
建立辐射场
将密度 σ \sigma σ 和颜色 c c c 分开建模
密度场
一个四层的 MLP ,输入 G X G_X GX ,输出 σ \sigma σ
视角相关的颜色场
类似 IBRNet [54] ,使用一个额外的 MLP ,通过混合图片像素值 { Φ n ( X ∣ I n ) } n = 1 N \left\{\Phi_n\left(X \mid I_{n}\right)\right\}_{n=1}^{N} {Φn(X∣In)}n=1N ,为查询点 X 和 视图方向 d d d 输出一致的颜色值 c c c
输入有四部分:
- 位置编码 G X G_X GX
- pixel-aligned特征 Φ n ( X ∣ F n a ) \Phi_{n}\left(X \mid F_{n}^{a}\right) Φn(X∣Fna) (唯一用到了第二个图像编码器的地方)
- 对应像素 Φ n ( X ∣ I n ) \Phi_n(X \mid I_n) Φn(X∣In)
- 视图方向(编码为视图方向和相机方向之间的差和点积)(不太懂,估计相机方向就是当前查询方向,视图方向就是输入图片的方向)
这些输入被连接起来,并通过 多视图pixel-aligned特征 计算出的均值和方差向量进行增强,然后通过一个 带有残差连接的 九层感知机 为 每一个视图 预测 混合权重 { w n } n = 1 N \left\{w_{n}\right\}_{n=1}^{N} {wn}n=1N 。
最终输出的颜色计算方法如下:
c = ∑ n = 1 N exp ( w n ) Φ n ( X ∣ I n ) ∑ i = 1 N exp ( w i ) c=\sum_{n=1}^{N} \frac{\exp \left(w_{n}\right) \Phi_{n}\left(X \mid I_{n}\right)}{\sum_{i=1}^{N} \exp \left(w_{i}\right)} c=n=1∑N∑i=1Nexp(wi)exp(wn)Φn(X∣In)
看起来这个混合权重还过了一个 softmax ,这么看来,这个式子有点像是从所有视图的颜色中选了一个颜色。
(感觉讲的不太清楚,他到底是怎么增强输入的?怎么用均值方差做增强的?可能还得再看看 IBRNet)
合成新视角
和 NeRF 原文很像,使用了一个 coarse-to-fine 的渲染策略,不过我们对两个层次都使用同一个网络。
训练和实现
为了训练,每次渲染 H ′ × W ′ H^{\prime}\times W^{\prime} H′×W′ 的 patch 。对 coarse 渲染每条射线采样 64 个点,对 fine 渲染每条射线采样 128 个点。
使用 L1损失 和 VGG感知损失
L = L R G B + L V G G \mathcal{L}=\mathcal{L}_{\mathrm{RGB}}+\mathcal{L}_{\mathrm{VGG}} L=LRGB+LVGG
使用 Adam 优化器,学习率 1 e − 4 1e^{-4} 1e−4 ,batch size 为 1 。其他参数保持默认。
所有训练集和测试集都使用 现有的抠图算法 [22] 移除了背景。
为了在渲染新视角时具有更好的时间一致性,在补充视频中,当输入视角只有两个时,我们将 计算颜色场时引入的 点积 的最大值 限制为 0.8 (不确定当输入视角超过2时还会不会限制)
实验
主要是想看他对空间编码的消融实验,为啥要这么设计空间编码,有没有试过别的方案
不同编码方案的对比 ⭐
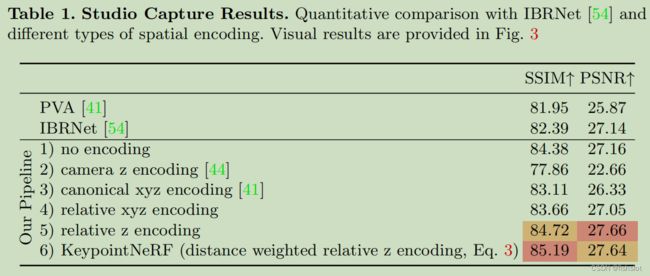
1 表示不编码(什么鬼,为啥不编码都比 PVA 和 IBRNet 高啊?)
2 就是 PIFu 和 PIFuHD 的方案
3 是 PVA 的方案
4 是与关键点的相对距离的 xyz 编码
5 是只使用与关键点的相对深度差编码,而不使用相对距离进行加权(几何上好像确实可以只靠 关键点的相对深度 就确定空间中的唯一点?)
使用野外图片重建人脸
使用 iPhone 采集图片,相机内参直接用厂家给的,相机外参用 多视角RGB-D 拟合出来。
重建人体
参与对比的方法有: pixelNeRF [60] , PVA [41] ,当前的 SOTA 模型 Neural Human Performer (NHP) [25] ,以及 不使用加权的 相对空间编码 的本方法。
使用 ZJU-MoCap 数据集。
缺陷和未来工作
渲染颜色的时候,将颜色预测参数化为可选像素的混合,这在推理时提供了很好的颜色泛化性,但是这让该方法对遮挡很敏感。
该方法在重建薄物体(比如眼镜)的时候有困难。在重建很拧巴的人体姿势、以及训练集中没有出现过的姿势 时,鲁棒性不足。
(对没见过的姿势泛化性不强,我认为很可能是因为空间编码方式不行,导致主要是卷积特征在carry,所以当出现没见过的姿势时就没法合成)
我们考虑将可学习的三维提升算法 [16,20] 与我们提出的 相对空间编码 相结合,以实现更优的端到端训练。
可以在补充材料中看到更多失败案例。
补充材料
多视角融合
用于多视角融合的四层网络,使用 Soft plus 激活 ,每层神经元是128,136,120,64,其输出经过一个 均值-方差池化 [54] 才能得到 G X ∈ R 128 G_{X} \in \mathbb{R}^{128} GX∈R128
密度场
一个四层的 MLP ,输入 G X G_X GX ,输出 σ \sigma σ
该四层MLP,使用 64 神经元,soft plus 激活。
视角相关的颜色场
用了一个单独的MLP,而且只用来预测混合权重。
与 IBRNet 一样,使用 均值-方差池化 来沟通不同视角的特征之间的信息。
先把 G X G_X GX 附加到 pixel-aligned特征 Φ ( X ∣ F n a ) \Phi(X | F_n^a) Φ(X∣Fna) 上,然后通过一个九层的带残差连接的 MLP 和一个ELU激活,来预测混合权重。
额外结果
IBRNet 的结果有很多模糊和絮状伪影。
PVA 的结果具有一致性,但是过于光滑。
MVSNeRF 对于分布较宽的输入视图效果不好。