论文翻译(13)--CASME II: An Improved Spontaneous Micro-Expression Database and the Baseline Evaluation
CASME II: An Improved Spontaneous Micro-Expression Database and the Baseline Evaluation
CASME II:一个改进的自发微表达数据库及基线评估
论文地址:链接:https://pan.baidu.com/s/1k6AY4W2zU1aENtTo5BZ3Mg
提取码:a042
摘要
一个健壮的自动微表情识别系统将在国家安全、警察讯问和临床诊断中有广泛的应用。开发这样一个系统需要高质量的数据库和足够的训练样本,而目前还没有。我们回顾了以前开发的微表情数据库,并建立了一个改进的(CASME II),具有更高的时间分辨率(200 fps)和空间分辨率(面部区域约2806340像素)。我们在一个控制良好的实验室环境和适当的照明(如消除灯光闪烁)下诱导参与者的面部表情。在近3000个面部动作中,247个微表情被选入数据库,并标注了动作单位(AUs)和情绪。对于基线评估,LBP-TOP和SVM分别用于特征提取和分类器,采用留下一个主题的交叉验证方法。5分类性能最好,为63.41%。
Introduction
微表情是一种短暂的面部动作,它揭示了一个人试图隐藏的真实情感[1–3]。此外,微表情对于行为者来说可能是不知道和/或不可控的,因此可以提供有效的线索来检测谎言。因此,微表情识别具有许多潜在的应用,如临床诊断和询问。在临床领域,微表情可用于理解患者的真实情绪和促进更好的治疗。例如,埃克曼[4]分析了一个抑郁症患者的采访视频,该患者表现出绝望的微表情,这可能预示着自杀。在询问或采访过程中,微表情揭示了受访者的真实感受,从而有助于进一步调查。例如,在辛普森一案的审判中,加藤高岭土的微言轻语暴露了他的真实情感[5]。
微表情的特点是持续时间短。公认的持续时间上限为1/2 s [3,6]。据观察,这些短暂的面部表情通常强度较低——面部肌肉因抑制而变得完全收缩可能是如此短暂。由于持续时间短、强度低,通常肉眼无法察觉或忽略[1]。为了更好地分析微表情,帮助揭示人们的情感,微表情自动识别系统是非常必要的
自动面部表情识别正在蓬勃发展。研究人员已经开发了许多算法,六种基本面部表情(愤怒、厌恶、恐惧、快乐、悲伤和惊讶)的准确率已经达到90%以上。相反,对自动微表情识别的研究最近才开始,只有几项工作。Shreve等人[7]将面部分成子区域(嘴、脸颊、前额和眼睛),并计算每个子区域的面部应变。然后分析每个子区域中的应变模式,以从视频剪辑中检测微表达。Pfister等人[8]提出了一个使用时间插值模型和多核学习来识别微表情的框架。波利科夫斯基等人[9]使用3D梯度描述符进行微表情识别。吴等[10]利用Gabor特征和温和SVM作为分类器,开发了一个微表情自动识别系统。王等[11]将灰度微表情视频片段作为三阶张量,利用判别张量子空间分析和极限学习机对微表情进行识别。RuizHernandez和Pietika inen [12]提出使用二阶局部高斯射流的重新参数化来编码局部二进制模式(LBP),以生成用于微观表达表示的更鲁棒和可靠的直方图。
常规面部表情识别的成功在很大程度上依赖于充足的面部表情数据库,例如普遍使用的CK+[13],MUG [14],MMI [15],JAFFE [16],Multi-PIE [17],以及几个三维面部表情数据库[18,19]。相比之下,很少有发展完善的微表情数据库,这阻碍了微表情识别研究的发展。引发微观表达很困难,因为它只出现在个人试图抑制情感但失败的特定情况下。根据埃克曼的说法,当一个人试图隐藏他或她的感情时,真实的情绪会很快泄露,并可能表现为微表情(埃克曼&弗里森,1969)。早些年,研究人员构建了highstakes情境来引出微观表达,例如通过要求人们对他们在视频片段中看到的内容撒谎[20],以及通过构建犯罪场景(模拟盗窃)和观点场景(对自己的观点撒谎)[21]。在这些研究中引发的微表情通常会被其他面部动作(如会话面部动作)混淆,这些动作与情绪无关,可能会“污染”当前不稳定的微表情分析算法的性能。一些研究人员开发了微型表情的小型数据库,要求参与者快速摆出面部表情[7,9]。然而,这些摆出的“微表情”不同于自发的[2,3]。因此,自发微表达数据库是学术研究和实际应用所必需的。研究发现,在中和面部表情的同时观看情感视频集是一种有效的方法,可以在没有许多无关面部动作的情况下引发自发的微表情[3,22]。到目前为止,只有四个微表达数据库,其中只有两个包含自发微表达,如表1所示。
 第二个原因是目前微表情数据库的视频质量不能满足微表情分析的需要。微表达持续时间短,强度低,难以检测和识别。更高的空间和时间分辨率可能有助于训练算法(这仍然不清楚)。与SMIC的100帧/秒和CASME的60帧/秒相比,CASME II的采样率为200帧/秒,旨在提供更详细的面部肌肉运动信息。此外,与SMIC约190像素6230像素和CASME约150像素6190像素的人脸尺寸相比,CASME II中的样本具有约280像素6340像素的较大人脸尺寸。
第二个原因是目前微表情数据库的视频质量不能满足微表情分析的需要。微表达持续时间短,强度低,难以检测和识别。更高的空间和时间分辨率可能有助于训练算法(这仍然不清楚)。与SMIC的100帧/秒和CASME的60帧/秒相比,CASME II的采样率为200帧/秒,旨在提供更详细的面部肌肉运动信息。此外,与SMIC约190像素6230像素和CASME约150像素6190像素的人脸尺寸相比,CASME II中的样本具有约280像素6340像素的较大人脸尺寸。
第三,我们调整了启发教学,以增加微观表达的多样性。埃克曼(1969)提到了两种可能泄露个人真实感受的微显示:“时间缩减的全影响微显示(即微表情)很可能是自我意识不到的,而静噪的微显示可能是自我在表演中途感觉到并中断的。李等人[22]和严等人[23]使用的启发范式只关注前者,即要求参与者完全抑制面部动作。另一种类型的微表情启发范式,即要求参与者在有自我意识时抑制面部运动,并不用于收集微表情。有可能这两种类型的微表情具有不同的动态特征。我们的目标是给参与者不同的指令来引出两种类型的微表情,以增加我们数据的多样性。
本文由两部分组成。在第一部分中,我们介绍了CASME的开发过程,包括获取微表达式的方法以及如何为数据库选择样本。在第二部分中,我们使用来自三个正交平面的局部二进制模式(LBP-TOP)对该数据库进行特征提取和支持向量机(SVM)进行分类。
Methods: Elicitation and analysis
微表情启发法
道德声明该实验程序得到了中国科学院心理研究所国际研究委员会的批准。参与者签署知情同意书,有权随时退出实验。如PLOS同意书所述,照片的拍摄对象已书面同意公布他们的照片
参与者本研究招募了35名参与者,平均年龄为22.03岁(标准差= 1.60)。都签了知情同意书,有权随时退出实验。
仪器伞状反射器(将光线聚焦在参与者的脸上)下放置四个严格选择的LED灯(以避免交流电(50 Hz)可能导致的闪烁光),以提供稳定和高强度的照明。我们之所以设计这样一个装置,是因为闪烁的灯光通常出现在高速录像中(比如SMIC的录像),而录像通常是黑暗和嘈杂的。“我们使用点灰色GRAS-03K2C相机捕捉参与者的面部,分辨率为6406480像素,”原始8 ’ '模式用于达到200 fps。我们将录像保存为MJPEG格式,没有任何帧间压缩。
材料情感效价高的视频集被证明是引发微表情的有效材料[3,22,23]。视频剧集具有相对较高的生态效度(Gross & Robert,1995),在情感效价方面通常优于图片。此外,本文由两部分组成视频片段是持久且动态的情绪刺激,使得抑制更加困难(严等人,2013)。我们在CASME中使用了类似于那些引发微表情的视频片段,但是删除了几个无效的片段,并添加了几个新的片段。20名参与者通过从列表中选择一个或两个情感关键词,并在7分李克特量表上对强度进行评分(0分为最低,6分为最高)。如果某个基本表达(例如快乐)被三分之一或更多的参与者选择用于一个视频集,则该情绪将被假定为该视频集的主要情绪。同一视频集的主观感受存在个体差异。同时,一集可能引发几种情绪,第12集和第17集就是明显的例子。表2列出了所选视频集的详细信息及其相应的评分。
 程序
程序
为了引出这样的面部表情,我们诱导参与者体验高度兴奋,并促进伪装的动机。类似的程序被用于建造SMIC和中国海洋工程总公司(见图1)。不同之处在于给参与者的指示:18名参与者被要求在观看视频剪辑时保持中立的面孔,而17名参与者只有在意识到有面部表情时才试图抑制面部运动。这个设计是为了引发两种类型的微表达[1],如上文引言中所述。参与者被要求在屏幕前观看视频剪辑,并避免任何身体运动。实验者从另一个监视器在线监视参与者的脸。这个设置帮助实验者预先定义一些习惯性动作,这些动作将在每次视频播放结束后由参与者验证。

样本选择和类别标签
两名编码员参与了微表达的分析。我们按照以下步骤处理原始视频记录,以选择微表情:
第一步。去掉无关的面部动作。录音中有大量面部动作,但许多明显无关紧要,如头部动作、吞咽唾液时按压嘴唇或其他习惯性动作(如擤鼻涕)。所有不带感情色彩的动作都被排除了。
**第二步。**通过限制待分析的样品,预先选择微表达候选物。编码者浏览并发现每个情绪运动片段的开始和偏移帧,只有那些持续时间不到一秒的片段被保存为微表情候选,用于进一步编码。过于细微而无法精确编码的表达式也被排除在外。
**第三步。**候选微表达片段被转换成帧序列,以便于精确标记起始帧和偏移帧。通过采用逐帧方法,确定每个序列起始和偏移的精确帧数,并且只有那些满足选择标准(总持续时间小于500毫秒或起始持续时间小于250毫秒)的序列被选择作为最终微表达样本。
选择微表情后,由两个编码员对每个微表情进行情感标记。可靠性为0.846,计算方法如下:

其中#AU(C1C2)是编码器1和编码器2同意的AU数,#All_AU是由两个编码器评分的微表达式中的AU总数。之后,两位编码员讨论并仲裁了分歧。
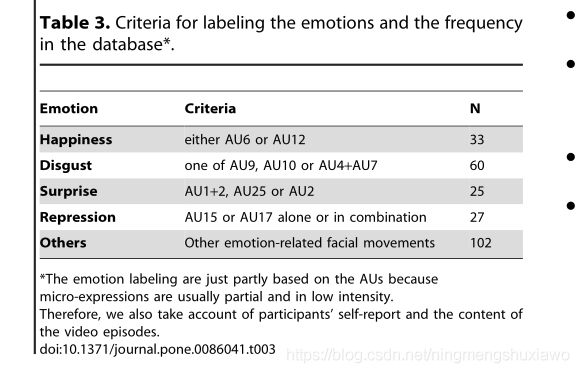
FACS [10]是一种客观的方法,用于根据组件动作来标记面部运动。不同的组可能有不同的微表达类,但可能有相同的AU编码系统。与要求人们产生几个预设面部动作的姿势面部表情不同,这个数据库中的自发微表情是由强烈的情感刺激引起的。因此,将这些微表情强行归类为与普通面部表情相同的六类是不合适的。例如,AU4(皱眉)可能表示厌恶、愤怒、关注或紧张[3]。在CASME II数据库中,微表情是基于AUs、参与者的自我报告和视频片段的内容来标记的。我们提供了五个主要类别(如表3所示)。
数据库简介
这个名为CASME II的数据库包含来自26名参与者的247个微表达样本。它们是从近3000个引发的面部动作中选出的。这些样本用起始帧和偏移帧编码,标记动作单位(AUs),标记情绪,并提供五个主要类别,如表3所示。用于标记情感类别的标准也显示在表3中,微表情剪辑的一个例子显示在图2中。非常微妙的微表情被删除,因为它们几乎无法编码开始和偏移(由于几乎察觉不到的变化,很难检测到转折点)。CASME II数据库具有以下特征:
 样本是自发的、动态的微观表现。基线(通常是中性)帧保留在每个微表达的前后,使得评估不同的检测算法成为可能。
样本是自发的、动态的微观表现。基线(通常是中性)帧保留在每个微表达的前后,使得评估不同的检测算法成为可能。
这些记录具有高时间分辨率(200 fps)和相对较高的面部分辨率(2806340像素)。
微表达标记基于FACS研究者指南[24]和严等人的发现[3]。标签标准不同于传统的普通面部表情的6个类别。
录音具有适当的照明,没有闪烁的光线,面部高光区域减少。
翻译:
某些类型的面部表情在实验室环境下很难引出,因此不同类别的样本分布不均匀,例如,有60个厌恶样本,但只有7个悲伤样本。在CASME II中,我们提供了5类微表情。
数据库评估
预处理

 实验
实验
我们对通过上一节描述的步骤预处理的样本进行了微表情识别实验。从时空的角度提取特征描述微表情,并使用SVM作为分类器为微表情提供基线性能。我们数据库的未来评估(图3)。详情如下。
 作为LBP基本思想的扩展,赵等人[28]提出了三正交平面上的局部二值模式(LBP-TOP),用于时空域的动态纹理分析。
作为LBP基本思想的扩展,赵等人[28]提出了三正交平面上的局部二值模式(LBP-TOP),用于时空域的动态纹理分析。
给定时间长度为T的视频序列,通常可以将其视为沿时间轴T的XY平面堆栈,但也可以将其视为Y轴上的XT平面堆栈,或x轴上的YT平面堆栈。XT和YT平面提供了关于时空转换的信息。以微观表达为例,XT和YT平面包含一行或一列像素的灰度值如何沿时间维度变化的信息;如果输入数据体是嘴角,它们相应地将嘴部运动描述为XT或YT平面中的动态纹理(见图5(a))。
LBP-TOP的基本思想与LBP相似,它是通过将其灰度值与其邻居的灰度值进行比较(和阈值化)来使用索引代码来表示每个像素的局部模式。为了包含来自3D时空域的信息,分别从每个像素的XY、XT和YT平面提取LBP代码。然后通过使用等式(3)和(4)形成每个平面的一个直方图,然后连接成单个直方图作为最终的LBP-TOP特征向量。注意我们可以把X,Y,T轴的半径设置不同的值为RX,RY,RT,所以最后我们可以有椭圆采样而不是圆形采样。提取LBP-TOP特征直方图的过程如图5(b)所示。


结果
X轴和Y轴的半径从1到4不等。T的半径从2到4不等(我们不考虑T = 1,因为样本在200 fps,两个相邻帧的变化很小)。XY平面、XT平面和YT平面中相邻点的数量设置为4。SVM被用作分类器。对于这个基线评估,我们选择了5类微表情——快乐、惊讶、厌恶、压抑和其他——进行训练和测试。考虑到样本不均匀分布在五个选定的类别,留一个主题-出交叉验证适用。在565个块中提取了LBP-TOP特征。性能如表4所示。当XY、YT和XT平面的半径分别为1、1和4时,最佳性能为63.41%。
Discussions and Limitations
关于诱导微表达和这个数据库仍然有一些限制:首先,这些自发微表达的标记不是很令人满意。引发微表情的材料是视频片段,它们是复杂的刺激,对不同的人有不同的意义。例如,咀嚼蠕虫的场景并不总是令人恶心——一些参与者实际上报告说“有趣”或“有趣”。仅仅根据AU对微表达进行分类(特别是对于尚未定义的AU组合)需要进一步深入研究。参与者被要求控制和抑制他们的面部表情,这通常会使自发的微表情显得部分,有时只有一个AU(另见波特,2008;严等,2013)。尽管我们考虑了非盟组合、视频片段的内容和参与者的报告,但这些微表情的情感标签仍有争议。
第二,这个数据库中的微表达式是在一个特定的实验室情况下得出的,可能不包含微表达式在其他情况下引发。当人们被警察审问或对老板撒谎时,微观表达可能与我们在实验室观察到的不同。到目前为止,很少有研究对不同情境下的微表情进行研究。未来的研究应该探索微表情在不同情况下的变化。
第三,不清楚哪种方法最适合微表情分类。微表情具有以下不同于普通面部表情的特征:(1)低强度面部动作,(2)部分面部表情(碎片)。因此,以前适用于普通面部表情分类的方法可能不适用于微表情。我们提供了这个数据库和基线评估,所以未来的研究可能会与我们的初步结果进行比较。
第四,参与者来自有限的年龄范围。参加启发环节的都是年轻人。大部分都是大学生。那就更好了如果数据库包含不同年龄模型的样本会更好。
Conclusions
本文回顾了以前开发的微表达数据库,并提出了一个新的和改进的微表达数据库。这个新的自发微表达数据库CASME II包括247个微表达样本,比以前的微表达数据库要大。微表达是在一个控制良好的实验室环境中获得的,并由高速摄像机(200帧/秒)记录下来,因此时间分辨率比以前的自发微表达数据库高得多。对于空间分辨率来说,人脸的大小要大于之前自发的微表情样本;因为更大规模的图像有助于揭示微小的变化,这将有利于特征提取和进一步更好的分类。这些录像在没有闪光的情况下具有适当的照明,并且面部的高光区域减少。这些样本用起始帧和偏移帧以及AUs和情感标签进行编码。我们还报告了使用LBP-TOP和SVM相结合的基线评估结果。
微表达分析是一个新的研究领域。从受控的实验室环境开始,可以使数据库很好地关注细微的表达,排除无关的因素。我们提供CASME II数据库作为未来探索潜在微表情分析算法的基准,这些算法适用于检测细微的面部肌肉运动以进行情绪状态识别。未来,我们将把我们的研究扩展到更自然的环境中,用于自然对话和交互中的表情和微表情分析。CASME II数据库现在是在线公共的,可以进行测试(详见http://fu.psych.ac.cn/CASME/casme2-en.php)。