Python-Level5-day11:Tensorboard可视化与线性回归实现;模型保存加载;数据读取:文件读取/图片读取


# 01_reshape_demo.py # 张量形状改变 # 静态形状:主要用于存储,一旦设置就不能改变 # 动态形状:主要用于计算,要求能够灵活变维 import tensorflow as tf pld = tf.placeholder(tf.float32, [None, 3]) # N行3列 print(pld) pld.set_shape([4, 3]) # 设置静态形状(一旦设置就不能改变) print(pld) # pld.set_shape([3,3]) # 报错,静态形状一旦设置就不能改变 new_pld = tf.reshape(pld, [3, 4]) # 动态形状设置 print(new_pld) new_pld2 = tf.reshape(pld, [2, 6])#不报错,元素个数匹配 print(new_pld2) # new_pld2 = tf.reshape(pld, [2, 4])#报错,元素个数不匹配 # print(new_pld2)

 其中最重要tf.matul()表示矩阵相乘哦
其中最重要tf.matul()表示矩阵相乘哦
 编辑 tensflow的文档写的非常好。CV文档写的不行。
编辑 tensflow的文档写的非常好。CV文档写的不行。
# 02_math_oper.py # 张量数学计算示例 import tensorflow as tf x = tf.constant([[1, 2, 3], [3, 4, 2]], dtype=tf.float32) y = tf.constant([[4, 3, 1], [3, 2, 1], [1, 1, 1]], dtype=tf.float32) x_mul_y = tf.matmul(x, y) # 矩阵规则相乘 log_x = tf.log(x) # 求对数 x_sum = tf.reduce_sum(x, axis=0) # 0-列方向 1-行方向 # 按片段操作 data = tf.constant([1, 2, 3, 4, 5, 6, 7, 8, 9, 10], dtype=tf.float32) segment_ids = tf.constant([0, 0, 0, 1, 1, 2, 2, 2, 2, 2], dtype=tf.int32) x_seg_sum = tf.segment_sum(data, segment_ids) # [6, 9, 40] with tf.Session() as sess: print(x_mul_y.eval()) # 执行操作并打印结果 print(log_x.eval()) print(x_sum.eval()) print(x_seg_sum.eval())

 编辑
编辑
 编辑
编辑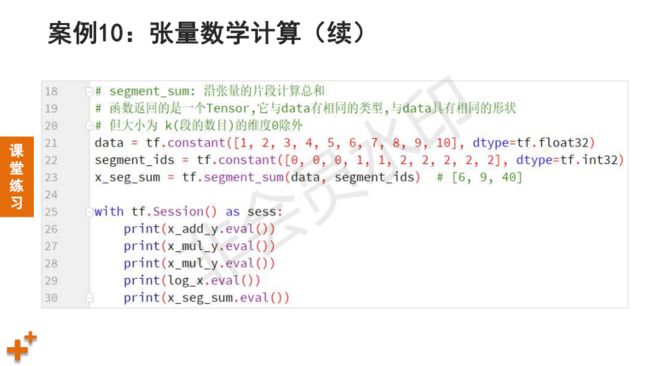
 编辑
编辑
 编辑
编辑
# 03_var_demo.py # 变量使用示例 """ 变量: 1)内容可变的张量(特殊的张量) 2)变量主要用于模型参数(如wx+b中的w和b) 3)变量中的值可以持久化保存 4)变量使用之前必须进行初始化 """ import tensorflow as tf a = tf.constant([1, 2, 3, 4, 5]) # 变量 var1 = tf.Variable( tf.random_normal([2, 3],mean=0.0,stddev=1.0),#初始值 name="var1") # 变量名称 # 定义初始化操作(此处并未执行) init_op = tf.global_variables_initializer() with tf.Session() as sess: sess.run(init_op) # 执行初始化 print(sess.run([a, var1])) # 执行a,var1操作

 编辑
编辑
 编辑
编辑
 编辑
编辑
 编辑
编辑

# 04_tb_demo.py
# tensorboard示例
"""
确认目录是否存在,启动代码
终端输入命令tensorboard --logdir="/home/tarena/summary/"
刷新界面
"""
import tensorflow as tf
a = tf.constant([1, 2, 3, 4, 5])
var = tf.Variable(tf.random_normal([2, 3], mean=0.0, stddev=1.0),
name="var_1") # 变量
# 定义一组操作
b = tf.constant(3.0, name="aaa")
c = tf.constant(4.0, name="bbb")
d = tf.add(b, c, name="myadd")
with tf.Session() as sess:
sess.run(tf.global_variables_initializer()) # 初始化
# 定义一个FileWriter对象
fw = tf.summary.FileWriter("/home/tarena/summary/", # 事件文件路径
graph=sess.graph) # 当前graph结构保存
print(sess.run([a, var])) # 执行操作

 编辑
编辑
 编辑
编辑
 编辑
编辑
 编辑
编辑
 编辑
编辑
 编辑
编辑
 编辑
编辑
 编辑
编辑
# 05_lr.py
# 利用tensorflow实现线性回归
import tensorflow as tf
import os
# 第一步:准备数据
x = tf.random_normal([100, 1], # 形状
mean=1.75, # 均值
stddev=0.5,# 标准差
name="x_data")# 名称
y_true = tf.matmul(x, [[2.0]]) + 5 # 计算 y = 2x + 5
# 第二步:定义模型
w = tf.Variable(tf.random_normal([1,1]), name="w") # w为随机值
b = tf.Variable(0.0, name="b") # b为小常数
y_predict = tf.matmul(x, w) + b # y = wx + b
# 第三步:定义损失函数、梯度下降优化器
loss = tf.reduce_mean(tf.square(y_true - y_predict))
train_op = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
# 设定收集哪些数据
tf.summary.scalar("losses", loss) # 收集loss(标量)
# 定义Saver对象(用于保存和加载模型)
saver = tf.train.Saver()
# 第四步:执行训练
with tf.Session() as sess:
sess.run(tf.global_variables_initializer()) # 初始化
print("w:", w.eval(), " b:", b.eval()) # 打印参数初始值
# 定义FileWriter对象
fw = tf.summary.FileWriter("/home/tarena/summary/",
graph=sess.graph)
# 训练之前,检查是否有已经保存的模型,如果有则加载
if os.path.exists("model/checkpoint"):#检查checkpoint文件
saver.restore(sess, "model/") # 从目录下加载模型
print("加载模型成功.")
for i in range(200):
sess.run(train_op) # 调用优化器的minize方法(梯度下降)
print("w:", w.eval(), " b:", b.eval(), " loss:", loss.eval())
# 收集loss的值,并存入文件
summary=sess.run(tf.summary.merge_all()) # 收集变量值,摘要合并
fw.add_summary(summary, i) # 写入第i次数据
saver.save(sess, "model/") # 保存模型


 编辑
编辑

 编辑
编辑
 编辑
编辑
 编辑
编辑
 编辑
编辑
 编辑
编辑
 编辑
编辑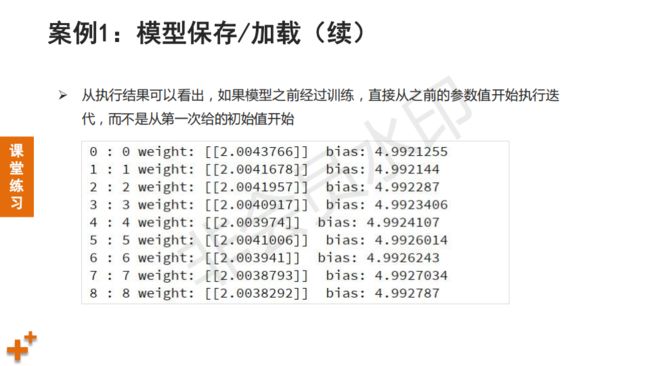
 编辑
编辑

 编辑
编辑
 编辑
编辑
 编辑
编辑
 编辑
编辑
 编辑
编辑
 编辑
编辑
 编辑
编辑
# 06_csv_reader.py # CSV样本文件读取示例 import tensorflow as tf import os # 创建队列、读取、批处理 def csv_read(filelist): # 参数为文件列表 # 1. 创建文件队列 file_queue = tf.train.string_input_producer(filelist) # 2. 读取内容,解码 reader = tf.TextLineReader() # 文本行读取器 k, v = reader.read(file_queue) # 读取,返回文件名、数据 records = [["None"], ["None"]] # 默认值 example, label = tf.decode_csv( v, # 读取到的数据 record_defaults=records)#默认值 # 3. 批处理(分批次返回) example_bat, label_bat = tf.train.batch( [example, label], # 解码后的数据 batch_size=4, # 批次大小 num_threads=1) # 线程数量 return example_bat, label_bat if __name__ == "__main__": dir_name = "test_txt/" # 测试文件所在目录 file_names = os.listdir(dir_name) # 列出所有内容 file_list = [] # 存放文件名称的列表 for f in file_names: full_path = os.path.join(dir_name, f) # 拼接完整路径 file_list.append(full_path) # 加入列表 example, label = csv_read(file_list) # 调用函数读取样本 with tf.Session() as sess: coord = tf.train.Coordinator() # 线程协调器(管理线程) # 返回一组线程 threads = tf.train.start_queue_runners(sess, coord=coord) print(sess.run([example, label])) # 执行操作 # 等待线程结束,回收线程资源 coord.request_stop() coord.join(threads)

 编辑
编辑
 编辑
编辑
 编辑
编辑
 编辑
编辑
# 07_img_reader.py
# 图像样本读取示例
import tensorflow as tf
import os
def img_read(filelist):
# 1. 构建队列
file_queue = tf.train.string_input_producer(filelist)
# 2. 定义reader, 读取, 解码
reader = tf.WholeFileReader() # 一次读取整个文件内容
k, v = reader.read(file_queue) # 读取,返回文件名、数据
img = tf.image.decode_jpeg(v) # 解码
# 3. 批处理
img_resized = tf.image.resize(img, [200, 200]) # 缩放
img_resized.set_shape([200, 200, 3]) # 固定样本形状
img_bat = tf.train.batch([img_resized], # 数据
batch_size=10, # 批次大小
num_threads=1) # 线程数量
return img_bat
if __name__ == "__main__":
# 1. 找到文件,构造一个列表
dir_name = "test_img/"
file_names = os.listdir(dir_name)
file_list = []
for f in file_names:
file_list.append(os.path.join(dir_name, f)) # 拼接目录和文件名
imgs = img_read(file_list)
# 开启session运行结果
with tf.Session() as sess:
coord = tf.train.Coordinator() # 定义线程协调器
# 开启读取文件线程
# 调用 tf.train.start_queue_runners 之后,才会真正把tensor推入内存序列中
# 供计算单元调用,否则会由于内存序列为空,数据流图会处于一直等待状态
# 返回一组线程
threads = tf.train.start_queue_runners(sess, coord=coord)
# print(sess.run([imgs])) # 打印读取的内容
imgs = imgs.eval()
# 回收线程
coord.request_stop()
coord.join(threads)
## 显示图片
print(imgs.shape)
import matplotlib.pyplot as plt
plt.figure("Img Show", facecolor="lightgray")
for i in range(10):
plt.subplot(2, 5, i + 1)
plt.xticks([])
plt.yticks([])
plt.imshow(imgs[i].astype("int32"))
plt.tight_layout()
plt.show()

 编辑
编辑
 编辑
编辑