自动调整学习率
学习率 :决定梯度下降的步长因素
:决定梯度下降的步长因素
为什么要进行自动调整学习率呢?
因为,当训练一个network时,train到最后发现,loss不在下降,有两种原因:
1、卡到了local minima or saddle point
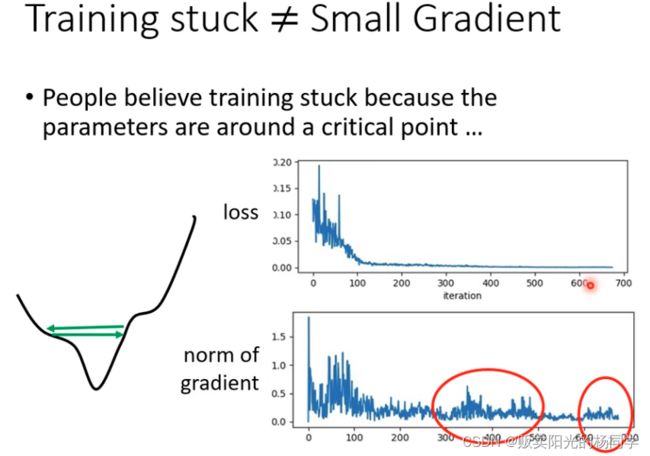
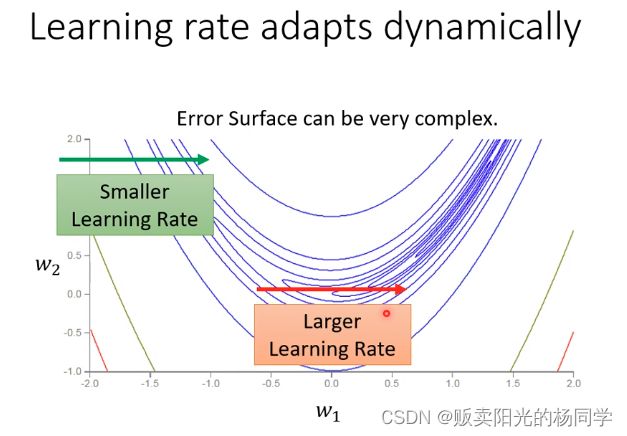
2、 gradient decent 始终上下徘徊 如下图所示:
如何判断这两种情况嘞,很简单,画出norm of gradient 。
此文章的前提:
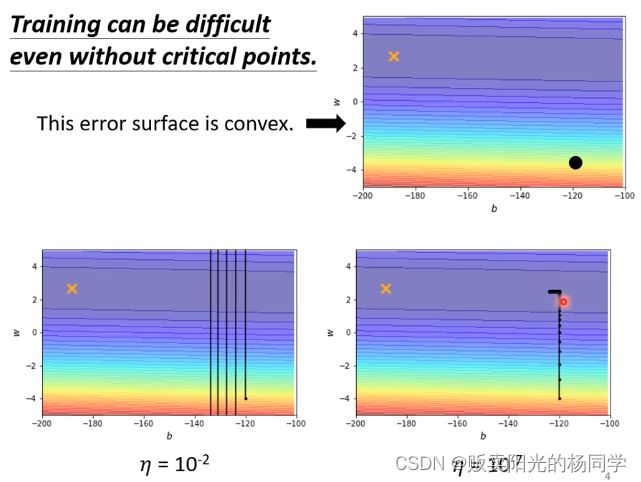
使用gradient descend 做optimization ,Loss在training到最后停滞不前
遇到的问题不会是critical point 而是 learning rate
当使用gradient descend 降低Loss时,由于learning rate 始终保持一种值,但如下图梯度递减的走向:
所以,如何改变此种现象呢? ---- 使用客制化learning rate
什么叫客制化learning rate呢?
---- 在error surface中,遇到平滑面,learning rate 大,步伐大。
-----在error surface中,遇到斜坡面,learning rate 小,步伐小。
如何自动实现客制化learning rate呢?
有两种方式
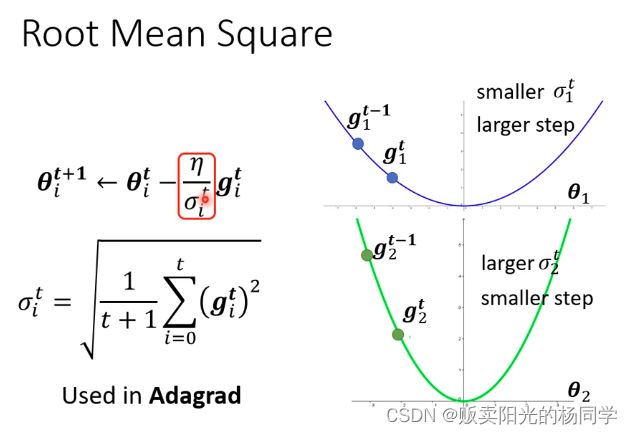
1、Root Mean Square
Ps:对于符号下标i -- 表示第i个参数
对于符号上标t -- 表示RMS所执行的步骤

为什么上述方法可以自动调节learning rate呢? 如下图所示进行详细解释:
见图参数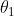 ,由于
,由于![]() and
and ![]() 坡度较小 ---
坡度较小 --- ![]() 较小 ---
较小 --- ![]() 较大--- large step
较大--- large step
见图参数 ,和上述描述刚好相反
,和上述描述刚好相反
但,Room Mean Square 并不是最终结的版本 为啥了?
因为,我们现实中是存在多个参数的,即使是同一个参数,该参数需要的learning rate也会随着时间而改变。如下图所示:
所有就算是同一个参数 & 同一个方向,我们也是期待learning rate 是可以动态调整的
有办法吗? 有的,就是下面的所要讲到得方法2
2、RMSProp (Room Mean Square 加强版)
Ps:出现新的超参数
-- 通过自定义来决定![]() 是(大概率)取决于
是(大概率)取决于![]() 还是(大概率)取决
还是(大概率)取决![]()
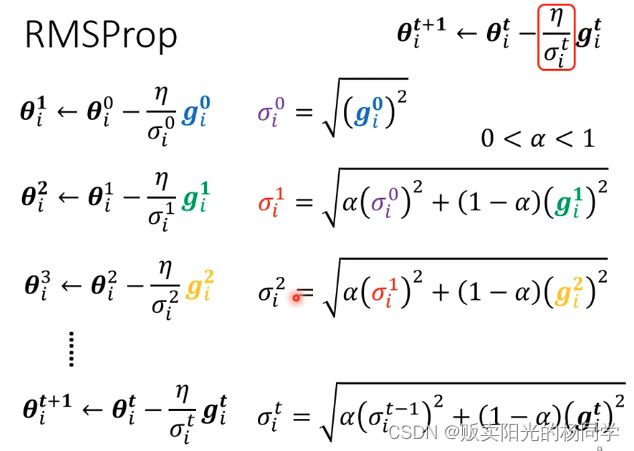
RMSProp优于RMS哪里呢?具体来讲,如下图所示:
观察前两个点,比较平滑,所以 small ![]() -- larger step
-- larger step
但注意到第三个点,他开始到了下坡时,我们可以自定义 小一点,从而注重于当前的![]()
这样,在下坡时,由于关注于![]() ,所以increase
,所以increase ![]() -- smaller step
-- smaller step
这样,相较于RMS,RMSProp更迅速地在斜坡上“刹住车”缓慢移动。

然后,今天最常用的optimization策略是什么呢?
Adam ,而Adam = RMSProp + Momentum
那么,将上诉客制化learning rate 方法应用到optimization中,文章开始所存在的问题还会存在吗?
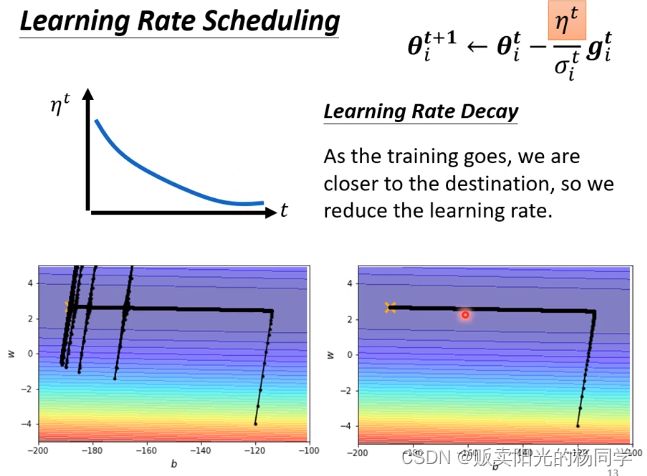
不存在了,但会出现新的问题,如下图所示:
当我们使用RMS时,train时,Loss到最后会不断上下浮动

但放心,有个方法可以解决此种现象
他叫做:Learning Rate Scheduling
就是将随着时间进行变换(因为,文章上述所有的方法,关于都是常量,不是变量)
而Learing Rate Scheduling 有经典非常常用的方法:
1、Learing Rate Decay
随着时间的增加而不断降低
2、Warm up(transformer 的optimization就是用到了这个小技巧--小黑科技)
随着时间的变化,先变大后变小
那么变大要变到多大呢;变大速度要多快呢;变小速度要多快呢 -- 这些都是超参数需要我们自己定义

OK, 对Optimization进行总结:
