Efficient Long-Range Attention Network for Image Super-resolution
Efficient Long-Range Attention Network for Image Super-resolution
Date: 2022/04/09
File Type: paper
Abstract
transformer性能好,但是计算力较高
SA(swlf-attention)计算的限制导致SR(super-resolution)性能不佳
提出ELAN(efficient long-range attention network)做图像SR
- 使用
shift-conv提取图像局部结构信息,其复杂性等同于1*1卷积 - GMSA模块(group-wise multi-scale self-attention)——在非重叠的一组特征图上使用不同大小尺寸的窗口计算SA,用以建立长距离依赖关系
ELAB(efficient long-range attention block)= 2*shift-conv + GMSA,使用共享注意力机制进一步加速计算过程
Without bells and whistles, our ELAN follows a fairly simple design by sequentially
cascading the ELABs.
1 Introduction
CNN缺点
基于CNN的方法卷积核大小一成不变,对建立像素之间的关系不够灵活
为扩大感受野,不断增加深度和复杂度去恢复细节,直接导致计算量增加
传统transformer缺点
SR的输入图片尺寸较大,而ViT计算量和图片大小成平方倍数,不方便使用ViT模型
SwinIR代表的方法中,用1*1 卷积提取的特征感受野很小,进而影响后面SA的计算,且小窗口内计算SA会限制远距离建模的能力
SwinIR有很多冗余和零散的组件,比如相对位置编码,掩码机制,LayerNorm以及一些子分支neat
Restormer提出的通道空间上计算SA,但是在通道空间上计算SA会牺牲一些有用的空间信息,例如纹理和结构信息,这些信息对下游任务很重要
本论文
We therefore aim to build a highly neat and efficient SR model, where the LR to HR image mapping is simply built by stacking local feature extraction operations and SA sequentially.
两个shift-conv来提取局部特征(shift-conv感受野大复杂度低),GMSA 模块将特征图划分为不同窗口尺寸的组计算SA
共享注意力机制去加速计算
Arming with
the shift-convandGMSAwithshared attention, an efficient long-range attention network, namely ELAN, is readily obtained for SR.
贡献
- We propose an efficient long-range attention block to model image long-range
dependency, which is important for improving the SR performance. - We present a fairly simple yet powerful network, namely ELAN, which
records new state-of-the arts for image SR with significantly less complexity
than existing vision transformer based SR methods.
2 相关工作
3 方法
3.1 ELAN概述
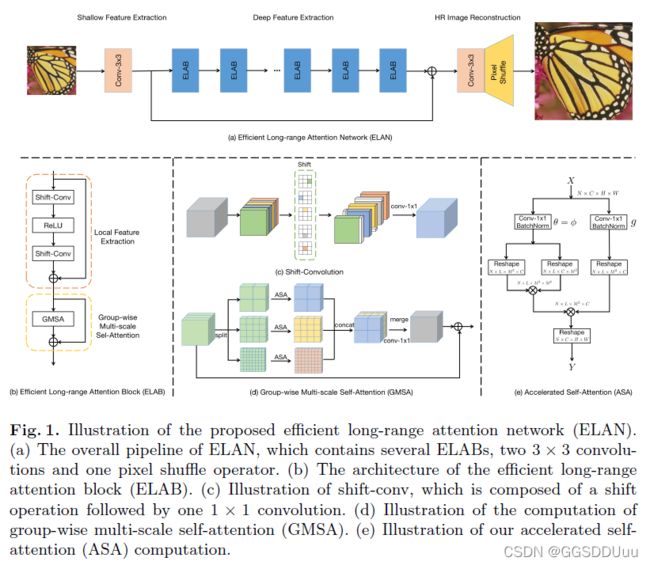
3.2 ELAB模块
局部特征提取
之前都是多层感知机和两个级联的11卷积提取局部特征,这样感受野只有11
我们使用两个shift-conv 和 ReLU激活函数扩大感受野
shift-conv:输入图划分为5组,沿着不同的空间维度移动前四组,包括上下左右,最后一组不动。然后紧接着1*1卷积,这样可以利用邻近像素的信息。
不用引入额外的参数和计算量,shift-conv能带来很大的感受野同时保持1*1卷积相当的复杂度
GMSA
一个 C × H × W C \times H \times W C×H×W 的特征图,划分非重叠窗口大小 M ∗ M M*M M∗M ,则基于窗口的自注意力计算复杂度为 2 M 2 H W C 2M^2HWC 2M2HWC
窗口大小 M M M决定SA计算的距离, M M M越大,提取的自相似性信息就越多
但是直接增加 M M M会带来计算量平方倍的增长
我们提出解决方案是GMSA ,首先把特征图划分为 K K K组,然后在第 K K K组特征图上使用 M k M_k Mk大小的窗口,然后不同组通过1*1卷积堆叠合并。
通过这个方法,我们设置不同大小的窗口大小来灵活控制计算量,
该方法计算量:(其中通道数为 C K \frac{C}{K} KC)
![]()
ASA(Accelerated self-attention)
放弃LN ,因为它将SA计算分割成很多元素操作,对高效推理不友好,而采用BN来稳定训练过程
其次,SwinIR[28]中的SA是在嵌入式高斯空间上计算的,其中采用了三个独立的1×1卷积,分别用θ、j和g表示,将输入特征X映射到三个不同的特征图。我们设定θ=j,在对称的嵌入式高斯空间[30,5]中计算SA,这样可以节省一个1×1的卷积在每一个SA中。这一修改进一步减轻了SA的计算和内存成本,而不影响SR的性能。我们的ASA如图1(e)所示。
Shared attention
在相邻的SA模块之间共享注意力分数,如图2,第 i i i 个SA模块计算出的注意力分数直接被后面的n个SA模块以相同的规模重新使用。
通过这种方式,我们可以在接下来的n个SA中避免2n个重塑和n个1×1卷积操作。我们发现,所提出的共享注意力机制在使用少量的n(如1或2)时,只导致SR性能的轻微下降,而在推理过程中却节省了很多计算资源。
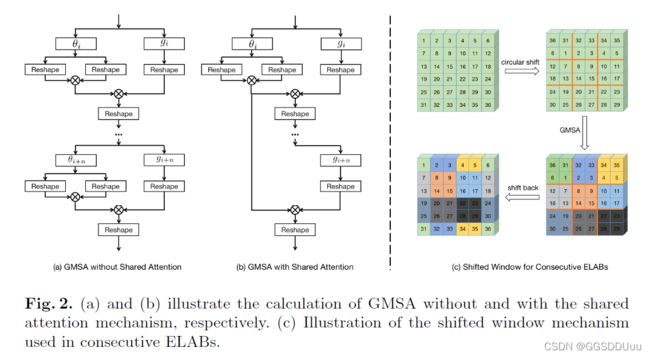
Shifted window
窗口与窗口之间并没有联系,于是引入shifting scheme ,
我们首先沿对角线方向对特征进行圆周移位,并对移位后的特征进行GMSA计算
然后,我们通过反循环移位将结果移回。
窗口大小为一半的循环移位导致了新的特征图分区,并在之前的GMSA模块中引入了相邻非重叠窗口之间的联系。
边界像素对性能影响忽略不计,因为他们只占整个特征图的一小部分
这样实现的移动机制不需要相对位置编码和掩码操作,网络更高效简洁
4. 实验

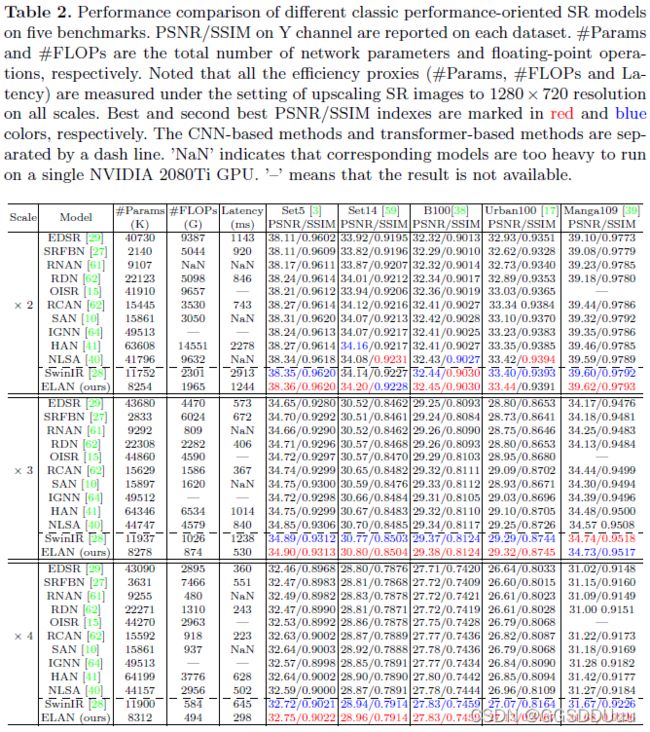
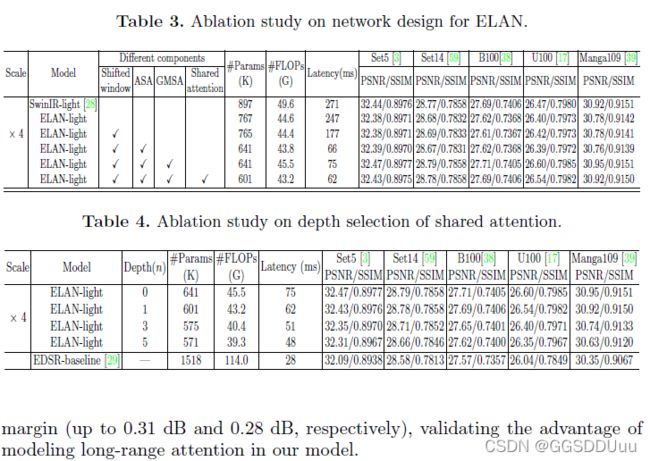
5. 结论
广泛的实验表明,在轻量级和面向性能的设置上,ELAN可以获得比以前最先进的SR模型更具竞争力的性能,同时比以前基于transformer的SR方法要经济得多。
尽管我们的ELAN比SwinIR实现了明显的加速,但与那些基于CNN的轻量级模型相比,SA的计算仍然是计算和内存密集型的。在未来,我们将进一步探索更有效的实现或近似的SA,以完成更多的低层次视觉任务。