Softmax Classifier 多分类问题
文章目录
-
- 8、Softmax Classifier 多分类问题
-
- 8.1 Revision
- 8.2 Softmax
-
- 8.2.1 Design
- 8.2.2 Softmax Layer
- 8.2.3 NLLLoss vs CrossEntropyLoss
- 8.2.4 Mini-Batch
- 8.3 MNIST dataset
-
- 8.3.1 Import Package
- 8.3.2 Prepare Dataset
- 8.3.3 Design Model
- 8.3.4 Construct Loss and Optimizer
- 8.3.5 Train and Test
- 8.3.6 完整代码
- 8.4 Kaggle Exercise
8、Softmax Classifier 多分类问题
B站视频教程传送门:PyTorch深度学习实践 - 多分类问题
8.1 Revision
1、Diabetes dataset: 糖尿病数据集
对该数据集做了二分类,并且该二分类网络的输出,概率其一: P ( y ^ = 1 ) P(\hat{y}=1) P(y^=1),概率其二: P ( y ^ = 0 ) = 1 − P ( y ^ = 1 ) P(\hat{y}=0)=1-P(\hat{y}=1) P(y^=0)=1−P(y^=1) 。
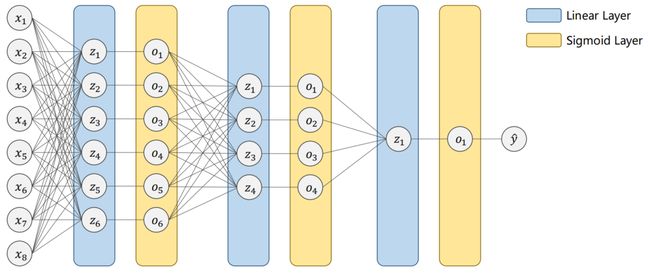
2、MNIST Dataset: MNIST数据集
在该数据集中,由于是做手写数字识别,所以共有10种不同的分类标签。
8.2 Softmax
试想:如果有10个分类,应当如何设计神经网络?
8.2.1 Design
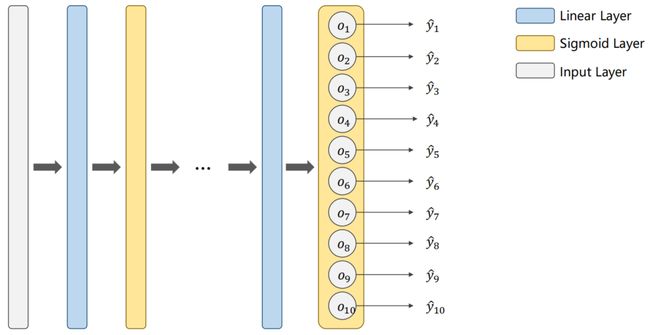
如上图,在最后输出的时候,可将原来只有一个 P ( y = 1 ) P(y=1) P(y=1) 的输出变成10个输出(因为有10个分类),就能输出该样本属于每一个分类的概率,如下表:
| 分类 | 概率 |
|---|---|
| y 1 ^ \hat {y_1} y1^ | P ( y = 0 ) P(y=0) P(y=0) |
| y 2 ^ \hat {y_2} y2^ | P ( y = 1 ) P(y=1) P(y=1) |
| … | … |
| y 10 ^ \hat {y_{10}} y10^ | P ( y = 9 ) P(y=9) P(y=9) |
注意:我们是将每一个类别看作一个二分类问题,且最后每个输出值需满足两个要求:① ≥ 0 \geq 0 ≥0,② ∑ = 1 \sum = 1 ∑=1,即输出的是一个分布。
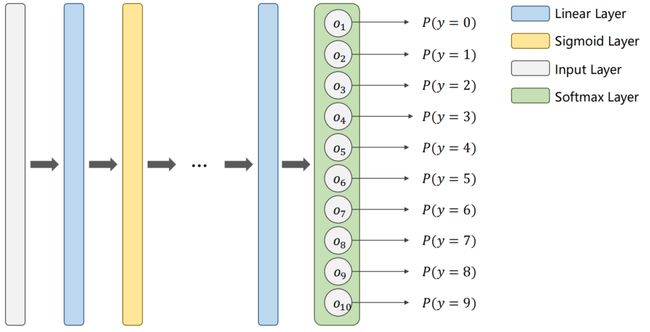
所以,在处理多分类问题时,在最终输出层我们使用 Softmax,即最后输出满足以下两个条件:
P ( y = i ) ≥ 0 (1) \Large P(y=i) \geq 0 \tag{1} P(y=i)≥0(1)
∑ i = 0 9 P ( y = i ) = 1 (2) \Large \displaystyle \sum_{i=0}^{9} P(y=i) = 1 \tag{2} i=0∑9P(y=i)=1(2)
8.2.2 Softmax Layer
Softmax到底是怎么实现的?用了一个什么样的计算来保证这10个元素:
问题 1:经过线性运算后,神经网络输出值可正可负,怎么将其变成正值?
问题 2:怎么让其和等于1?
假设 Z l ∈ R k Z^l \in \mathbb{R}^k Zl∈Rk 是最后一个线性层的输出,Softmax函数:
P ( y = i ) = e Z i ∑ j = 0 k − 1 e Z j , i ∈ { 0 , . . . , K − 1 } (3) \Large P(y=i) = \frac {e^{Z_i}} {\sum_{j=0}^{k-1} e^{Z_j}}, i \in \lbrace 0, ... , K-1 \rbrace \tag {3} P(y=i)=∑j=0k−1eZjeZi,i∈{0,...,K−1}(3)
Example:
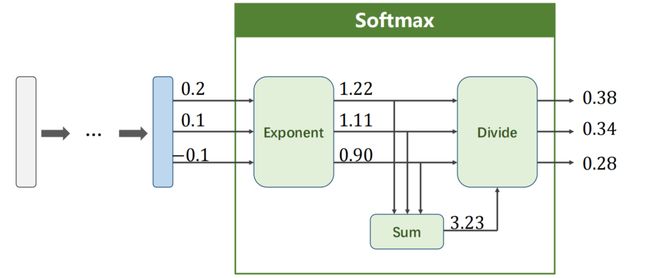
L o s s ( Y ^ , Y ) = − Y l o g Y ^ (4) \Large Loss(\hat Y, Y) = -Y log \hat Y \tag {4} Loss(Y^,Y)=−YlogY^(4)
8.2.3 NLLLoss vs CrossEntropyLoss
one-hot:独热编码(One-Hot)及其代码
NLLLoss:https://pytorch.org/docs/stable/generated/torch.nn.NLLLoss.html?highlight=nllloss#torch.nn.NLLLoss
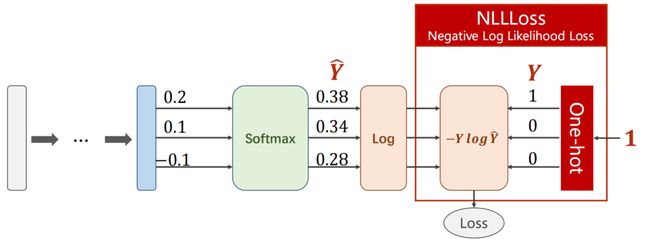
在 Numpy 中:
import numpy as np
z = np.array([0.2, 0.1, -0.1])
y = np.array([1, 0, 0])
y_pred = np.exp(z) / np.exp(z).sum()
print(y_pred)
loss = (- y * np.log(y_pred)).sum()
print(loss)
[0.37797814 0.34200877 0.28001309]
0.9729189131256584
CrossEntropyLoss:https://pytorch.org/docs/stable/generated/torch.nn.CrossEntropyLoss.html?highlight=crossentropyloss#torch.nn.CrossEntropyLoss
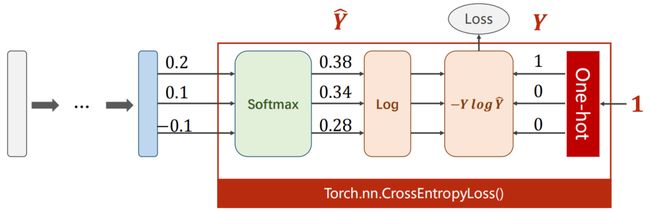
在 PyTorch 中:
import torch
z = torch.Tensor([[0.2, 0.1, -0.1]])
y = torch.LongTensor([0])
criterion = torch.nn.CrossEntropyLoss()
loss = criterion(z, y)
print(loss)
tensor(0.9729)
C r o s s E n t r o p y L o s s < = = > L o g S o f t m a x + N L L L o s s \Large CrossEntropyLoss \lt==\gt LogSoftmax + NLLLoss CrossEntropyLoss<==>LogSoftmax+NLLLoss
神经网络的最后一层不需要做激活(经过Softmax层的计算),直接输入到CrossEntropyLoss损失函数中即可。
8.2.4 Mini-Batch
import torch
criterion = torch.nn.CrossEntropyLoss()
Y = torch.LongTensor([2, 0, 1])
Y_pred1 = torch.Tensor([[0.1, 0.2, 0.9],
[1.1, 0.1, 0.2],
[0.2, 2.1, 0.1]])
Y_pred2 = torch.Tensor([[0.8, 0.2, 0.3],
[0.2, 0.3, 0.5],
[0.2, 0.2, 0.5]])
loss_1 = criterion(Y_pred1, Y)
loss_2 = criterion(Y_pred2, Y)
print('Batch Loss1 =', loss_1.data, '\nBatch Loss2 =', loss_2.data)
Batch Loss1 = tensor(0.4966)
Batch Loss2 = tensor(1.2389)
8.3 MNIST dataset
以下是 MNIST 手写数据集中的一个图像:

8.3.1 Import Package
import torch
from torchvision import transforms # 构造 DataLoader
from torch.utils.data import DataLoader # 同上
from torchvision import datasets
import torch.nn.functional as F # 激活函数 relu()
import torch.optim as optim # 构造优化器
8.3.2 Prepare Dataset
batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(), # 将PIL Image 转换为 Tensor
transforms.Normalize((0.1307,), (0.3081,)) # 均值 和 标准差
])
train_dataset = datasets.MNIST(root='../data/mnist', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='../data/mnist', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)
1、ToTensor():将 PIL Image 转换成 PyTorch Tensor
P I L I m a g e : Z 28 × 28 , p i x e l ∈ { 0 , . . . , 255 } \Large PIL\quad Image: \mathbb{Z}^{28 \times 28}, pixel \in \{0, ... ,255\} PILImage:Z28×28,pixel∈{0,...,255}
P y T o r c h T e n s o r : R 1 × 28 × 28 , p i x e l ∈ [ 0 , 1 ] \Large PyTorch\quad Tensor: \mathbb{R}^{1 \times 28 \times 28}, pixel \in [ 0, 1] PyTorchTensor:R1×28×28,pixel∈[0,1]
2、Normalize((mean, ), (std, )):均值 标准差,数据归一化
P i x e l n o r m = P i x e l o r i g i n − m e a n s t d \Large Pixel_{norm} = \frac {Pixel_{origin} - mean} {std} Pixelnorm=stdPixelorigin−mean
8.3.3 Design Model

class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(784, 512)
self.l2 = torch.nn.Linear(512, 256)
self.l3 = torch.nn.Linear(256, 128)
self.l4 = torch.nn.Linear(128, 64)
self.l5 = torch.nn.Linear(64, 10)
def forward(self, x):
x = x.view(-1, 784)
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
return self.l5(x) # 最后一层 不需要激活
model = Net()
8.3.4 Construct Loss and Optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5) # 进一步优化,momentum:冲量
8.3.5 Train and Test
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
optimizer.zero_grad() # 清零
# forward + backward + update
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad(): # 不需要计算梯度
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy on test set: %d %%' % (100 * correct / total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()
8.3.6 完整代码
import torch
from torchvision import transforms # 构造 DataLoader
from torch.utils.data import DataLoader # 同上
from torchvision import datasets
import torch.nn.functional as F # 激活函数 relu()
import torch.optim as optim # 构造优化器
batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(), # 将PIL Image 转换为 Tensor
transforms.Normalize((0.1307,), (0.3081,)) # 均值 和 标准差
])
train_dataset = datasets.MNIST(root='../data/mnist', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='../data/mnist', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(784, 512)
self.l2 = torch.nn.Linear(512, 256)
self.l3 = torch.nn.Linear(256, 128)
self.l4 = torch.nn.Linear(128, 64)
self.l5 = torch.nn.Linear(64, 10)
def forward(self, x):
x = x.view(-1, 784)
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
return self.l5(x) # 最后一层 不需要激活
model = Net()
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5) # 进一步优化,momentum:冲量
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
optimizer.zero_grad() # 清零
# forward + backward + update
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %3d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad(): # 不需要计算梯度
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy on test set: %d %%' % (100 * correct / total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()
[1, 300] loss: 2.228
[1, 600] loss: 1.029
[1, 900] loss: 0.434
Accuracy on test set: 89 %
[2, 300] loss: 0.321
[2, 600] loss: 0.268
[2, 900] loss: 0.237
Accuracy on test set: 93 %
[3, 300] loss: 0.192
[3, 600] loss: 0.172
[3, 900] loss: 0.153
Accuracy on test set: 95 %
[4, 300] loss: 0.131
[4, 600] loss: 0.123
[4, 900] loss: 0.111
Accuracy on test set: 96 %
[5, 300] loss: 0.092
[5, 600] loss: 0.097
[5, 900] loss: 0.092
Accuracy on test set: 97 %
[6, 300] loss: 0.077
[6, 600] loss: 0.071
[6, 900] loss: 0.076
Accuracy on test set: 96 %
[7, 300] loss: 0.060
[7, 600] loss: 0.059
[7, 900] loss: 0.061
Accuracy on test set: 97 %
[8, 300] loss: 0.045
[8, 600] loss: 0.049
[8, 900] loss: 0.052
Accuracy on test set: 97 %
[9, 300] loss: 0.039
[9, 600] loss: 0.038
[9, 900] loss: 0.040
Accuracy on test set: 97 %
[10, 300] loss: 0.032
[10, 600] loss: 0.032
[10, 900] loss: 0.034
Accuracy on test set: 97 %
8.4 Kaggle Exercise
Otto Group Product Classification Challenge:https://www.kaggle.com/competitions/otto-group-product-classification-challenge

代码如下:
import pandas as pd
import numpy as np
import torch
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
import torch.optim as optim
# 数据预处理
# 定义函数将类别标签转为id表示,方便后面计算交叉熵
def labels2id(labels):
target_id = [] # 给所有target建立一个词典
target_labels = ['Class_1', 'Class_2', 'Class_3', 'Class_4', 'Class_5', 'Class_6', 'Class_7', 'Class_8',
'Class_9'] # 自定义9个标签
for label in labels: # 遍历labels中的所有label
target_id.append(target_labels.index(label)) # 添加label对应的索引项到target_labels中
return target_id
class OttogroupDataset(Dataset): # 准备数据集
def __init__(self, filepath):
data = pd.read_csv(filepath)
labels = data['target']
self.len = data.shape[0] # 多少行多少列
# 处理特征和标签
self.x_data = torch.tensor(np.array(data)[:, 1:-1].astype(float)) # 1:-1 左闭右开
self.y_data = labels2id(labels)
def __getitem__(self, index): # 魔法方法 支持dataset[index]
return self.x_data[index], self.y_data[index]
def __len__(self): # 魔法函数 len() 返回长度
return self.len
# 载入训练集
train_dataset = OttogroupDataset('../data/Otto Group Product Classification Challenge/train.csv')
# 建立数据加载器
train_loader = DataLoader(dataset=train_dataset, batch_size=64, shuffle=True, num_workers=0)
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(93, 64) # 93个feature
self.l2 = torch.nn.Linear(64, 32)
self.l3 = torch.nn.Linear(32, 16)
self.l4 = torch.nn.Linear(16, 9)
self.relu = torch.nn.ReLU() # 激活函数
def forward(self, x): # 正向传播
x = self.relu(self.l1(x))
x = self.relu(self.l2(x))
x = self.relu(self.l3(x))
return self.l4(x) # 最后一层不做激活,不进行非线性变换
def predict(self, x): # 预测函数
with torch.no_grad(): # 梯度清零 不累计梯度
x = self.relu(self.l1(x))
x = self.relu(self.l2(x))
x = self.relu(self.l3(x))
x = self.relu(self.l4(x))
# 这里先取出最大概率的索引,即是所预测的类别。
_, predicted = torch.max(x, dim=1)
# 将预测的类别转为one-hot表示,方便保存为预测文件。
y = pd.get_dummies(predicted)
return y
model = Net()
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5) # 冲量,冲过鞍点和局部最优
def train(epoch): # 单次循环 epoch决定循环多少次
running_loss = 0.0
for batch_idx, data in enumerate(train_loader):
inputs, target = data # 输入数据
inputs = inputs.float()
optimizer.zero_grad() # 优化器归零
# 前馈+反馈+更新
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item() # 累计的损失
if batch_idx % 300 == 299: # 每300轮输出一次
print('[%d, %3d] loss:%.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
# 定义预测保存函数,用于保存预测结果。
def predict_save():
test_data = pd.read_csv('../data/Otto Group Product Classification Challenge/test.csv')
test_inputs = torch.tensor(
np.array(test_data)[:, 1:].astype(float)) # test_data是series,要转为array;[1:]指的是第一列开始到最后,左闭右开,去掉‘id’列
out = model.predict(test_inputs.float()) # 调用预测函数,并将inputs 改为float格式
# 自定义新的标签
labels = ['Class_1', 'Class_2', 'Class_3', 'Class_4', 'Class_5', 'Class_6',
'Class_7', 'Class_8', 'Class_9']
# 添加列标签
out.columns = labels
# 插入id行
out.insert(0, 'id', test_data['id'])
output = pd.DataFrame(out)
output.to_csv('../data/Otto Group Product Classification Challenge/my_predict.csv', index=False)
return output
predict_save()
[1, 300] loss:1.584
[1, 600] loss:0.898
[1, 900] loss:0.799
[2, 300] loss:0.741
[2, 600] loss:0.721
[2, 900] loss:0.694
[3, 300] loss:0.672
[3, 600] loss:0.670
[3, 900] loss:0.662
[4, 300] loss:0.645
[4, 600] loss:0.648
[4, 900] loss:0.631
[5, 300] loss:0.623
[5, 600] loss:0.630
[5, 900] loss:0.611
[6, 300] loss:0.609
[6, 600] loss:0.600
[6, 900] loss:0.599
[7, 300] loss:0.586
[7, 600] loss:0.584
[7, 900] loss:0.594
[8, 300] loss:0.586
[8, 600] loss:0.568
[8, 900] loss:0.568
[9, 300] loss:0.566
[9, 600] loss:0.568
[9, 900] loss:0.566
[10, 300] loss:0.556
[10, 600] loss:0.552
[10, 900] loss:0.559