【pytorch目标检测】FPN网络结构
语义一般指的是图像每个像素点的类别归属
语义信息可以理解为与类别划分有关的信息
对网络前端通过非线性变换,对图像内容中纹理,几何颜色等信息表达,这种表达会使网络后端对类别归属做出正确的预测
- 低级语义信息:对浅层特征的表达(如颜色,几何,纹理等特征) 网络的前几层
- 高级语义信息:高层特征的表达,对分类产生重要影响 网络的后几层
引言
2016年 特征金字塔网络(Feature Pyramid Network)
为了增强语义性,传统的物体检测模型只在backbone的最后一个特征图上进行后续操作,而这一层对应的下采样率(图像缩小的倍数)较大,如16、32造成小物体在特征图上的有效信息较少。
前言:feature pyramid是用来检测不同scale的object 基本方法
多尺度问题:小物体检测性能急剧性能急剧下降
解决方法:图像金字塔
思路:将输图片做成多个尺度,不同尺度图像上生成不太的尺度特征,这种方法简单有效,计算量大
网络创新
基于feature pyrimid来检测不同scale的object,共有5种思路:4种已有思路(分别缩写为ABCD)和(FPN)



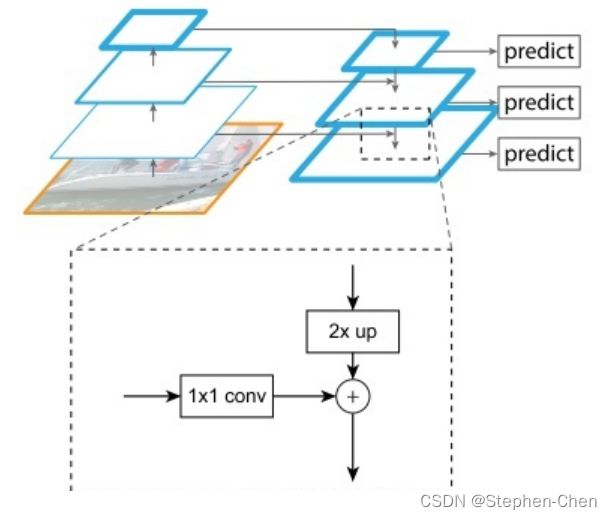
FPN:基于CNN固有的pyramid hierarchy,通过skip connection构建top-down path,仅需少量成本生成feature pyramid,并且feature pyramid的每个scale都具有high-level semantic feature,最终在feature pyramid的各个level上进行目标检测
- 在deep learning detector中构建pyramid(而最近的RCNN、SPPNet、Fast RCNN、Faster RCNN都没有使用pyramid representation),仅需少量成本并且feature pyramid中每个level都具有high-level semantic feature
- 速度快、精度高
- generic:FPN独立于骨干网络,可以用于改进多种算法,本文将其用于Faster RCNN(RPN+Fast RCNN)、instance segmentation proposals
网络结构
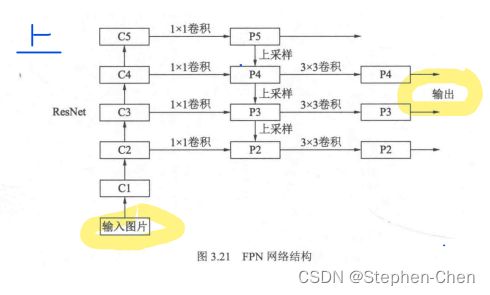
自下而上: bottom-up path
-
最左侧是普通卷积网络默认使用(Resnet),用作提取语义信息
-
C1代表Resnet前几个卷积和池化层
-
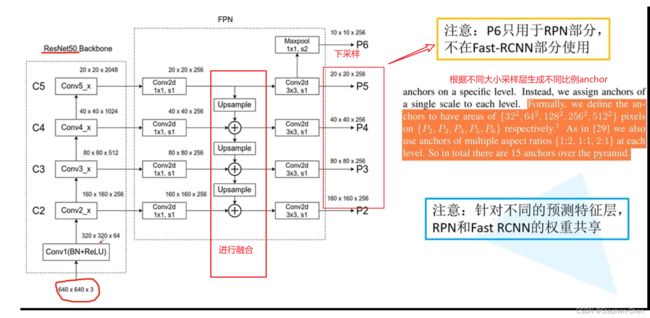
C2-C5分别为ResNet的不同的卷积组stage,这些卷积组中包含多个backbone结构,组内feature map大小相同,组间大小递减
-
stage:
-
- 定义:将backbone分为多个stage,将每个stage定义为1个pyramid level
- 输出:每个stage中,所有layer输出特征图的size是相同的,取其中最后1层的输出作为该stage的输出,因为每个stage中最深的层应该具有最强的特征
- 下采样:相邻stage之间的下采样比例为2
FPN for ResNet:本文将ResNet的后4个stage{ C2,C3,C4,C5}(相对于输入的下采样比例分别为4、8、16、32)的输出定义为4个pyramid level,并不将第1个stage的输出包含到FPN中因为其内存占用量比较大。
自上而下:
- P5依次进行上采样得到P4,P3和P2,目的得到和C4,C3,C2长宽相同的特征,便于下步元素的相加
- 采用的是2倍最邻近上采样,直接对邻近元素复杂,不是线性插值
2 倍上采样的具体实现方法则是简单的最近邻插值算法。pytorch 官方实现的代码就是使用插值算法,模式是最近邻算法。
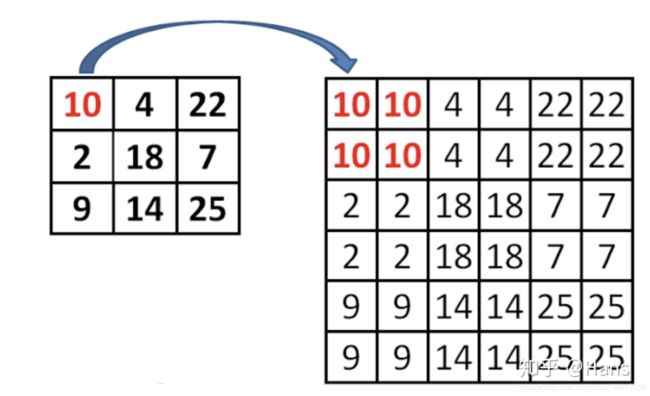
为什么使用最近邻插值而不是双线性插值?
使用最近邻值插值法,可以在上采样的过程中最大程度地保留特征图的语义信息(有利于分类),从而与 bottom-up 过程中相应的具有丰富的**空间信息(高分辨率,有利于定位)**的特征图进行融合,从而得到既有良好的空间信息又有较强烈的语义信息的特征图。
横向链接:skip connection
目的:是为了将上采用后的高语义特征与浅层定位细节特征进行融合
1*1的卷积就是使其通道数变为256
卷积融合:
得到相加的特征后,利用3*3卷积对生成的P2和P4再进行融合,目的是消除上采用带来的重叠效应
方法:FPN将身材的语义信息传到底层,来补充浅层的语义信息
目的:获得高分辨率、强语义的特征
效果:在小物体检测、实例分割等不错表现
代码实现
from torch import nn
import torch.nn.functional as F
class Bottleneck(nn.Module):
def __init__(self,in_dim,out_dim,stride = 1):
super(Bottleneck,self).__init__()
#网络堆叠层使用的1*1 3*3 1*1这三个卷积组成,中间有BN层
self.bottleneck = nn.Sequential(
nn.Conv2d(in_channels=in_dim,out_channels=in_dim,kernel_size=1,bias=False),
nn.BatchNorm2d(in_dim),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=in_dim,out_channels=in_dim,kernel_size=3,padding=1,bias=False),
nn.BatchNorm2d(in_dim),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=in_dim,out_channels=out_dim,kernel_size=1,padding=1,bias=False),
nn.BatchNorm2d(out_dim)
)
self.relu =nn.ReLU(inplace=True)
#Downsample 部分是一个包含BN层的1*1卷积组成
'''利用DownSample结构将恒等映射的通道数变为与卷积堆叠层相同,从而保证可以相加'''
self.downslape = nn.Sequential(
nn.Conv2d(in_channels=in_dim,out_channels=out_dim,kernel_size=1,padding=1,stride=1),
nn.BatchNorm2d(out_dim)
)
def forward(self,x):
identity = x
out = self.bottleneck(identity)
identity = self.downslape(x)
#将identity(恒等映射)与网络堆叠层输出进行相加。并经过Relu后输出
out +=identity
out =self.relu(out)
return out
class FPN(nn.Module):
'''FPN的类,初始化需要一个list,代表ResNet每一个阶段的Bottleneck的数量'''
def __init__(self,layers):
super(FPN,self).__init__()
self.inplaces = 64
#处理输入的C1模块
self.conv1 = nn.Conv2d(3,64,kernel_size=7,stride=2,padding=4,bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
#搭建自下而上的C2,C3,C4,C5
self.layer1 = self._make_layer(64,layers[0])
self.layer2 = self._make_layer(128, layers[1],2)
self.layer3 = self._make_layer(256, layers[2],2)
self.layer4 = self._make_layer(512, layers[3],2)
#对于C5减少通道数,得到p5,主要是1*1卷积
self.toplayer = nn.Conv2d(2048,256,1,1,0)
#3x3卷积特征融合
self.smooth1 = nn.Conv2d(256,256,3,1,1)
self.smooth2 = nn.Conv2d(256, 256, 3, 1, 1)
self.smooth3 = nn.Conv2d(256, 256, 3, 1, 1)
#横向连接,保证通道数相同
self.latlayer1 = nn.Conv2d(1024,256,1,1,0)
self.latlayer2 = nn.Conv2d(512, 256, 1, 1, 0)
self.latlayer3 = nn.Conv2d(256, 256, 1, 1, 0)
#构建C2到C5注意区分stride值为1和2的情况
def _make_layer(self, block, channel, block_num, stride=1) -> nn.Sequential:
downsample = None
if stride != 1 or self.in_channel != channel * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channel * block.expansion)
)
layers = []
layers.append(block(self.in_channel, channel, downsample=downsample, stride=stride))
self.in_channel = channel * block.expansion
# 将实线的残差结构搭进去
for _ in range(1, block_num):
layers.append(block(self.in_channel, channel))
return nn.Sequential(*layers)
#自上而下的上采样模块
def _upsamle_add(self,x,y):
_ , _ ,H ,W = y.shape
return F.upsample(x,size=(H,W),mode="bilinear") + y
def forward(self,x):
'''关键在于forward怎么传递'''
#从下到上是 resnet的主干部分进行卷积
c1 = self.maxpool( self.relu(self.bn1(self.conv1(x))))
c2 = self.layer1(c1)
c3 = self.layer1(c2)
c4 = self.layer1(c3)
c5 = self.layer1(c4)
#从上到下:上采样部分
p5 = self.toplayer(c5)
p4 = self._upsamle_add(p5,self.latlayer1(c4))
p3 = self._upsamle_add(p4,self.latlayer1(c3))
p2 = self._upsamle_add(p4, self.latlayer1(c2))
#卷积融合,平滑处理
p4 = self.smooth1(p4)
p3 = self.smooth2(p3)
p2 = self.smooth3(p2)
return p2,p3,p4,p5
总结
不足:
- PoolNet指出top-down路径中高级语义信息会逐渐稀释
- Libra RCNN指出FPN采取的sequential manner使得integrated features更多地关注于相邻层,而较少关注其它层,每次fusion时非相邻层中的semantic information就会稀释1次