DDIA读书笔记第五章——复制
分布式系统中采用复制的原因:
1、提高可用性:冗余容错
2、降低延迟:使得数据与用户更接近
3、提高读吞吐:水平扩展可以接受读请求的机器数量
如果数据只读,那么复制做起来很简单,设计系统时可以考虑这点,比如LSM tree。难点在于数据可以变更,怎样保证副本上的数据一致性。
常见的三种复制算法:单领导者、多领导者、无领导者
设置复制时的取舍:同步复制or异步复制,复制失败时如何处理
领导者与跟随者
存储冗余数据的成为副本,基于领导者的同步算法,是把数据同步到所有副本的常见算法:
1、副本中选取一个作为leader,客户端发送请求给leader,leader先将新数据写到本地
2、leader将数据变更发送给所有的follower
3、客户端读请求可以发送给leader或者follower
同步复制和异步复制
同步复制:强一致性、时延高、可用性不高(一个失败,全部不能工作)
异步复制:最终一致性、时延低、可用性高
半同步复制:两者折中
一般工业实践选择异步复制
新增从库
如果从库只读,只需要拷贝数据即可;
如果从库可写,先禁止写入,拷贝完成之后,再设置可写,具体过程如下:
1、leader上做快照
2、从库拉快照
3、从库加载完快照之后,继续拉leader的新增变更数据流
4、直到赶上leader
宕机处理
从库宕机
拉取宕机时间内,主库的新增变更即可;或者落后太多,先拉快照
主库宕机
需要做failover,拥有最新变更的从库提升为主库
1、确认主库宕机:一般用超时判断
2、选择一个从库提升为主库:从库要有最新日志
3、重新更新配置,系统内部其他节点要感知到leader已经切换,系统外客户端也要感知到
failover时,可能有很多问题:
1、如果使用异步复制,从库上数据可能不是最新的,发生数据丢失
2、相关外部系统冲突
3、新老主副本冲突:脑裂
4、超时阈值选取、活锁等
复制日志的实现
对一个系统来说,多副本同步的是什么?增量修改
具体到一个数据库系统来说,有数据库外部的应用层、数据库内部的查询层和存储层组成。修改在查询层体现为:语句;在存储层体现为:与存储引擎相关的预写日志;与存储引擎无关的逻辑日志;修改完成后,在应用层变现为触发器逻辑
基于语句的复制
主副本同步用户的更新语句:INSERT、DELETE、UPDATE
问题:
1、非确定性函数:例如NOW()、RAND()
2、自增或者有外部条件WHERE等
3、有副作用的语句
解决办法:
1、识别非确定函数
2、对于这些语句同步值而不是语句
一般不用这种复制
传输预写式日志(WAL)
同步存储引擎的WAL
缺点:与存储引擎绑定
逻辑日志复制(基于行)
复制日志与存储引擎的预写日志解耦开来,
好处:
1、方便代码兼容,更好的滚动升级
2、不同副本可以使用不同的存储引擎
3、允许导致做各种变更
基于触发器的复制
与用户的应用层有关
复制延迟问题
异步复制会导致复制延迟问题,异步复制实现的是最终一致性(最弱的一致性状态?)
读你所写
主从复制延迟,可用让用户觉得数据丢失:

需要提供另一种一致性:读写一致性
1、按内容分类:读可能被主库修改的内容,都从主库读,比如:从主库读取自己的档案,从从库读取其他人的档案
2、按时间分类:对于刚更新的数据,从主库读,对于较老的数据,从从库读
3、利用时间戳:客户端记下上一次写入的时间戳,当该时间戳的变更传到从库时,可以从从库读,否则从主库读。时间戳可以是实际时间,也可以是逻辑时间
复杂case:
1、多个数据中心:发送给主副本的请求都要能够路由到该数据中心的主副本上
2、一个用户多个逻辑客户端
单调读
1、异步复制的另外一个问题:读摇摆

需要保证单调读一致性,比强一致性弱,比最终一致性强,与读写一致性区别:
读写一致性是,读到的数据与写入的数据保持一致性
单调读一致性:多次读数据之间的一致性
保证单调读:保证客户端只从一个副本去读
一致前缀读
异步复制问题,违反因果关系:如果一些列写入按照某种顺序发生,那么任何人读取这些写入时,也要看到相同的顺序

本质是由于分区造成的,解决方案:保证所有相关的写入都落到相同的分区中
复制延迟的解决方案
通过事务解决?
多主复制
多个领导者,读写、写写冲突解决更加困难,一般很难有完全的解决方案
应用场景
运维多个数据中心

性能:避免跨地域延时,性能更好
容错性:容忍数据中心级别的故障
需要离线操作的客户端
应用程序在断网之后仍然需要继续工作
本地客户端充当一个主,远程服务端有事另外一个主
协同编辑
例如github
处理接入冲突
多领导者复制的最大问题是可能发生写冲突,这意味着需要解决冲突
冲突检测
没啥好办法,比如,账户共10元,两个用户分别去5元、6元,有可能都成功
避免冲突
多主冲突很难解决,所以首要是避免冲突,比如检测到可能有冲突发生时, 强制两个写入路由到同一个主上
冲突收敛
两个写入后,如果检测到冲突,那么治理冲突
冲突合并方法:
1、最后写入胜利LLW:根据事件顺序,最近的写入为准
2、显示的保留冲突,交给用户解决
自定义解决
把写冲突交给用户解决
写时解决
写入时,检测到冲突时并解决
读时解决
读取时返回冲突的数据,由用户解决
多主复制拓扑

三种常见的拓步:环形、星型、点多点
环形和星型有单点可用性问题,点多点拓步在冲突解决方案更加复杂
无主复制
典型:Dynamo
当节点故障时写入数据库
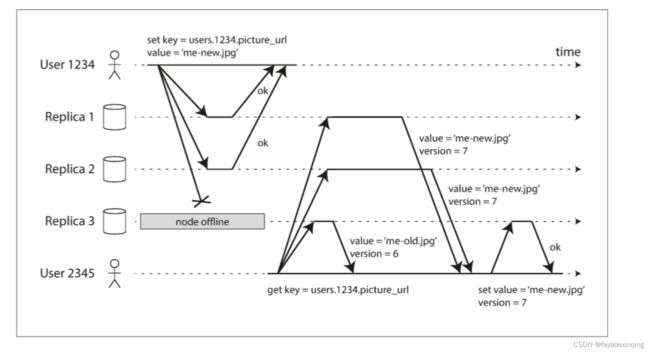
满足条件:W+R > N,适当设置W和R的值,可以做读写性能的handoff
读修复和反熵
由于副本故障,导致某个副本落后时,如何修复?
读修复:客户端读取时,根据逻辑时间发现某个副本逻辑,主动修复
反熵:集群主动修复落后的副本
检测并发写入
Dynamo风格的读写会有数据冲突问题:
多个客户端写入时:
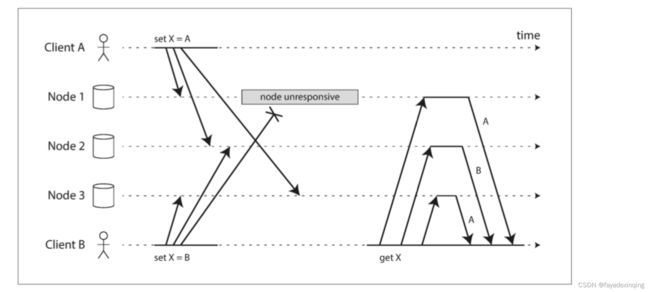
读X,有可能读到A或者B,并且无法通过度修复或者反伤解决
最后写入胜利(丢弃并发写入)
“此前发生”的关系和并发
只要有两个操作A和B,就有三种可能性:A在B之前发生,或者B在A之前发生,或者A和B并发。前两种情况在具有因果关系的写入时容易界定,后一种需要合并写入,比如购物车添加商品场景