starGan-v2论文复现-代码完整
github:https://github.com/clovaai/stargan-v2
Paper: https://arxiv.org/abs/1912.01865
github上的代码没有预训练权重,并且给出下载地址也拒绝访问,所以基本上没有能跑的完整代码。
如果需要完整代码:https://download.csdn.net/download/weixin_48167570/85093151
文章目录
- 解决问题
- 内容
-
- 1、框架
- 效果图
- 损失函数
- 数据集
解决问题
理想的图片到图片的转换应该能够考虑到域内的各种各样的样式。但是这样的话,设计模型和学习模型都会变得复杂,因为域和样式都能有很多。
域(domain):一组可以在视觉上独特分类的图片,并且每一张图都有独特外观(称为样式style)。例如,可以设置图片的域是基于人的性别,这种情况下样式(style)可以包括妆容、胡须、发型等。
需要解决以下两点:
解决样式多样性(diversity):已知方法是向生成器(generator)中注入低纬度的latent code(可以从标准高斯分布中随机采样) 。 但是,由于这些方法仅考虑了两个域之间的映射,因此无法扩展到越来越多的域。例如,如果有K个域,这些方法需要训练K(K-1)个生成器来处理每个域之间的转换,从而限制了它们的实际使用。
解决可扩展性(scalability):一些统一的框架被提出。StarGAN 可以使用单个生成器学习所有可用域之间的映射,但是因为把预定标签作为附加输入使得映射是确定的,无法成为多模式。
解决方法:
为了解决以上问题,StarGAN v2这种可扩展方法被提出,它可以在多个域中生成各种图片。
StarGAN v2提出两个模块,一个映射网络mapping network和一个样式编码器style encoder。 映射网络学习将随机高斯噪声转换为style code,编码器则学习从给定的参考图像中提取style code。 考虑到多个域,两个模块都具有多个输出分支,每个分支都提供特定域的style code。 利用这些style code,生成器将学习成功地在多个域上成功合成各种图像。
内容
1、框架
X:图片集
Y:可能的域
生成器Generator
将输入图像x转换成能反映特定域style codes的输出图像G(x, s)。s 可以由mapping network F或者是style encoder E 提供。使用自适应实例归一化AdaIN 来将s注入G中。s 被设计成表示特定域y的样式,这样就不用向G提供y并且能够使G合成所有域的图像。
生成器将输入图像转换为反映特定于域(domain)的style code的输出图像。

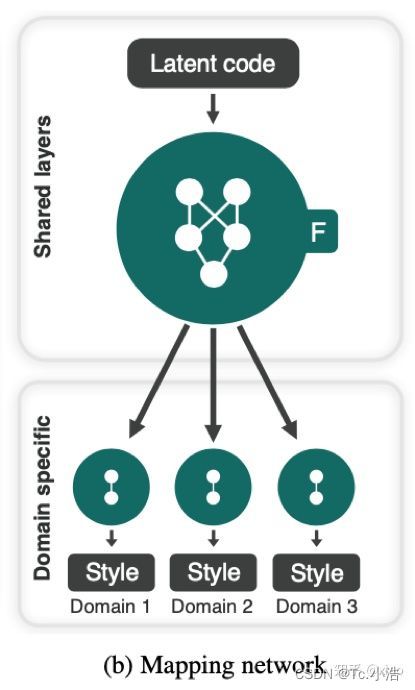
映射网络Mapping network
给定一个latent code z和一个域y,映射网络F生成style code s = Fy(x)其中Fy(·)表示与域y相对应的F的输出。 F由带有多个输出分支的MLP组成,可为所有可用域提供样式代码。 F可以通过随机采样潜在向量z∈Z和域y∈Y来产生不同的style code。多任务架构使F可以有效地学习所有领域的样式表示。
映射网络将一个潜在的代码转换成多个域(domain)的style code,在训练过程中随机选择其中一个域(domain)。
样式编码器Style encoder
给定图像x及其对应的域y,编码器E提取x的style code s = Ey(x)其中Ey(·)表示与域y相对应的输出。与F相似,样式编码器是多任务学习设置, E可以使用不同的参考图像生成不同的style code。这允许G合成反映参考图像x的样式s的输出图像。
样式编码器提取图像的style code,允许生成器执行参考引导的图像合成。

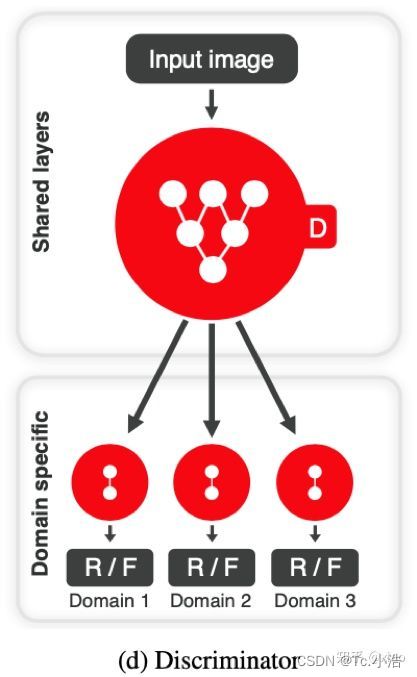
鉴别器Discriminator
是一个多任务鉴别器,它由多个输出分支组成。每个分支Dy学习一个二进制分类,确定图像x是其域y的真实图像还是由G生成的假图像G(x,s)。
鉴别器从多个域(domain)区分真假图像。
效果图
第一行和第一列图像是真实图像,而其余图像由模型StarGanv2生成的图像。模型参考图像中提取高级语义,如发型、妆容、胡须和年龄,同时保留参考图像的姿势和特点。下图反应了StarGanV2可以合成反映不同参考样式的图像,包括发型、妆容和胡须,而不会损害源特性。

章中也分别对CelebA HQ和AFHQ数据集进行比较。文章中使用随机抽样的latent code将参考图像(最左边的列)转换为目标图像。(a) 前三行将男性转化为女性的结果,反之亦然。(b)顶部每两行按以下顺序显示合成图像:猫到狗,狗到野生动物,野生动物到猫。
损失函数
对抗性目标
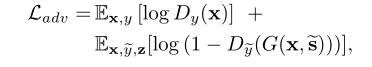
其中,Dy(·)表示与域y相对应的D的输出,x为输入图片,s是style code
风格重构
![]()
这是为了让生成器G在生成图片G(x,s)的时候使用style code
风格多样化
![]() s1和s2由两个随机的潜在编码(latent codes)z1和z2产生。最大化两个风格生成图像的差距,这种方式可以让生成器探索意义的风格特征以生成不同的图像。
s1和s2由两个随机的潜在编码(latent codes)z1和z2产生。最大化两个风格生成图像的差距,这种方式可以让生成器探索意义的风格特征以生成不同的图像。
保留原图特征
![]()
生成器G使用原图经过风格编码器(style encoder)所得进行重建,让G保留源图特征,有些像cyclegan。
总损失函数
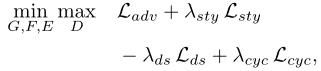
其中 λ s t y λ_{sty} λsty, λ d s λ_{ds} λds,和 λ c y c λ_{cyc} λcyc是超参数。
数据集
CelebA-HQ 和新AFHQ数据集上评估StarGAN v2。 我们将CelebA-HQ分为男性和女性两个域,将AFHQ分为猫,狗和野生动物三个领域。 除主要标签外,我们不使用任何其他信息(例如CelebA-HQ的面部属性或AFHQ的品种),并让模型无需监督即可学习样式等信息。将所有图像调整为256×256分辨率以进行训练 。
Animal Faces HQ(AFHQ): 15000张512*512动物图片。猫,狗和野生动物分别有5000张图。每个域,500张用于测试。