yolo系列笔记
yolo v1
yolo v1的模型训练过程。
yolo v1理解
- 首先要做标签的变换,因为yolo v1生成的 embedding 是 b a t c h − s i z e × S × S × 30 batch-size \times S \times S \times 30 batch−size×S×S×30的维度,所以首先要把每张图像的标签也转换成相同的 S × S × 30 S \times S \times 30 S×S×30的维度。标签转换的依靠encoder函数完成:
def encoder(self, boxes, labels): //这里的boxes是voc2007.txt中的bounding box
"""
boxes (tensor) [[x1,y1,x2,y2],[]]
labels (tensor) [...]
return 14x14x30 //这里的 S = 14 B = 2
"""
grid_num = 14
target = torch.zeros((grid_num, grid_num, 30)) //每张图片都要根据voc2007.txt中的标签编码成[S, S, 30]的向量
cell_size = 1./grid_num # 归一化后每个网格的大小
wh = boxes[:, 2:] - boxes[:, :2] # 读出每个bounding box的宽高
cxcy = (boxes[:, 2:] + boxes[:, :2]) / 2 # 读出每个bounding box的中心点
for i in range(cxcy.size()[0]): # 有几个obj就是[n, n]
cxcy_sample = cxcy[i] # 第 i 个obj的bounding box 的归一化中心点
ij = (cxcy_sample/cell_size).ceil()-1 # 找到该obj的bounding box的中心的索引,也就是看它属于那个网格
target[int(ij[1]), int(ij[0]), 4] = 1 # 将target中box设为1
target[int(ij[1]), int(ij[0]), 9] = 1 # 将target中box设为1
target[int(ij[1]), int(ij[0]), int(labels[i])+9] = 1 # 将target中class设为1
xy = ij*cell_size # 匹配到网格的左上角相对坐标
delta_xy = (cxcy_sample - xy)/cell_size # 相对网格的左边和上边的偏移量
target[int(ij[1]), int(ij[0]), 2:4] = wh[i] # 每个bounding box的归一化宽高
target[int(ij[1]), int(ij[0]), :2] = delta_xy # 相对中心点的偏移量
target[int(ij[1]), int(ij[0]), 7:9] = wh[i]
target[int(ij[1]), int(ij[0]), 5:7] = delta_xy
return target
标签转换的过程就是将图片编码成一个[S,S,30]维的向量,也就是将 S × S S \times S S×S个patch每个都encode为30维的向量,如果这个patch 中存在object,则将该patch的30维的向量的第 5 个, 第 10 个位置(即是置信度,代表有 obj 的位置)置 1,另外将 20 个类别的相应类别位置置 1,注意前 4 个位置是经过转换后的,而且一个patch 只预测一个类别,所以一个patch的30维向量的后 20 个位置是 one-hot 编码,(x, y, w, h --> x y 代表真实bbox的中心点相对其落入的网络的上边和下边的偏移量,w h–>代表每个bounding box的归一化宽高),因为一个patch 只预测一个类别,所以该obj的框是唯一的,所以第1-4 个和 5-8个位置的数都相同。
2. yolo 的训练流程:先将整张图片分成 S × S S \times S S×S 个patch,然后每个 patch 负责预测两个 bounding box,如果 图片分成了 14 × 14 14 \times 14 14×14个patch,那么就将有 14 × 14 × 2 14 \times 14 \times 2 14×14×2个bounding box,yolo的网络很简单就是普通的CNN网络结构,只是最后不需要激活(因为做的是回归不是分类),加了激活就是逻辑回归,就变成分类了。,最后的pred_tensor为 [batch-size, 14, 14, 30],和真实标签是匹配的。然后将这个pred_tensor进行损失的计算。详细的损失如下:
- 损失的计算
yolo v1的损失包括 5 个部分。

首先对于pred_tensor和target_tensor都是[Batch-size, 14, 14, 30],
(1)首先计算置信度误差:置信度误差分为边框内无对象和边框内有对象的损失两种
边框内无对象:如果预测的很准的话真实标签和预测标签应该是相同的。所以可以通过真实标签的第 5 或者 10 位是否为 1 把相应在预测标签内应该存在 object 的 patch找出来,这时可以将预测 pred_tensor 分为两类,一类是应该存在 obj 的patch,第二类是不应该出现 obj 的 patch。然后可以根据预测向量中第 5 或者 10 位的值是否为 0 把第二类不应该有 obj 的 patch 但是被网络预测为有 obj 的 patch 提取出来. 也可以把第一类中本该有 obj 的 patch 但是被网络预测为没有 obj 的 patch 提取出来。 主要是找到预测出错的patch
边框内有对象:假设按照真实标签挑选出了应该出现(这个 patch 就是用来预测的) obj 的 patch,每个patch的pred_tensor都有两个置信度和两个 bbox, 通过计算这两个bbox和真实的bbox之间的IoU来确定这个 patch 的 最后保留的 bbox,然后通过计算每个保留的 bbox 和 相应的 IoU 的误差之和(MSE均方和)误差,可以叫做 IoU 误差。这个误差可以理解为应该出现 obj 的 patch (对该 obj 负责)预测出来的置信度和 IoU 之间的差距。不负责的bbox可能按理说是没用的,但是可能会出现误剔除的情况,所以还要一种损失就是不负责的 bbox 和真实标签中没有 obj 的patch之间的误差。
(2)定位损失
定位损失是针对应该出现obj的patch而言的。最终预测出的所有 bbox 的中心点损失和宽高损失。宽度和高度先取了平方根,因为如果直接取差值的话,大的对象对差值的敏感度较低,小的对象对差值的敏感度较高,所以取平方根可以降低这种敏感度的差异,使得较大的对象和较小的对象在尺寸误差上有相似的权重.
(3)对象的分类误差
yolo v1 里面分类误差还是使用了MSE。
总结: yolo v1的三部分损失全部用了MSE.
- IoU的计算
注意:在训练过程中没有用到 NMS
模型的预测过程(指预测图片)
这个过程和训练过程不同的是采用了 NMS 方法来产生 预测窗口。
NMS方法原理
NMS方法一般只对同一类别的框进行抑制。
yolo v1的注意点
1、每个网格只预测一个类别(也即一个类别的边界框),而且最后只取置信度最大的那个边界框。这就导致如果多个不同物体(或者同类物体的不同实体)的中心落在同一个网格中,会造成漏检。
2、yolo对相互靠的很近的物体,还有很小的群体检测效果不好,这是因为一个网格中只预测了两个框,并且只属于一类。
3、位置精准性差,召回率低。由于损失函数的问题,定位误差是影响检测效果的主要原因。尤其是大小物体的处理上,还有待加强
4、对测试图像中,同一类物体出现的新的不常见的长宽比和其他情况时。泛化能力偏弱

yolo v2
yolov2相对于yolov1改进的地方:
(1)网络结构的改变,作者设计了一个Darknet-19网络,不仅减少了计算,而且提高了精度。
(2)加入了anchor base,yolov2 采取faster rcnn的做法,先对数据集做个k-means聚类,得到 5 个anchor bbox的宽和高(这和faster rcnn不一样,后者是得到9个anchor bbox, 而且得到4个维度,即中心点坐标和宽、高)。所以yolo v2就不再是直接预测真实bbox了。而是通过预测与anchor的偏移来优化,这种方法大大提高了召回率。
(3)网络的特征维度的变化。yolov2的darknet-19网络的输出特征维度是[b, 125, 14, 14],表示 14 × 14 14 \times 14 14×14个patch,每个patch都可以预测 5 个bounding bbox,也就是 5 × ( 20 + 5 ) 5 \times (20 + 5) 5×(20+5),这就是说yolo v2每个patch可以预测5个objes,这比yolo v1的输出维度[b, 20+5+5, 7, 7]一个patch只能预测 1 个类别要更精确。
yolo v3
yolo v3相对yolo v2的改进,
(1)yolo v3出的时候resnet网络已经出现了,所以yolo v3借鉴了resnet的残差结构将darknet-19网络加深到darknet-53,即有53层卷积层。
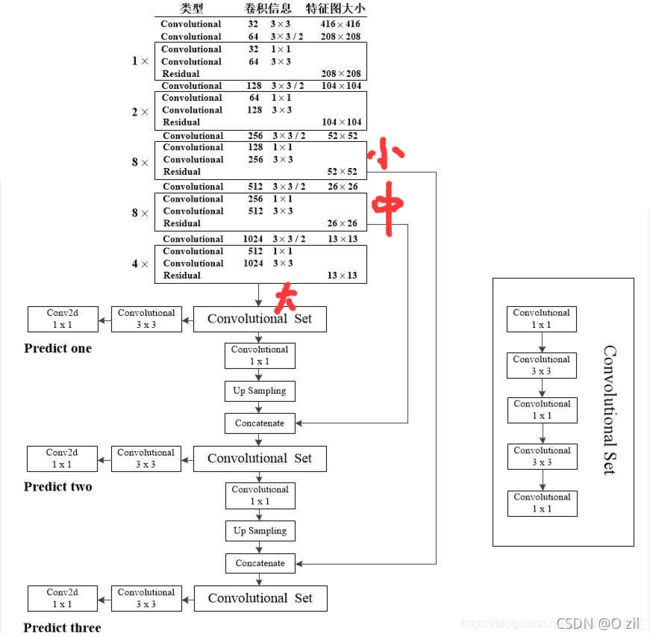
yolo v3的结构如上图所示,除了darknet-53作为backbone,而且还利用了FPN(和真实的FPN有点不同,但是都是采用上采样,也就是插值的方法)进行多尺度预测,其中predict one 专门用来预测大物体, predict two 用来预测midium物体,predict three 用来预测 small 物体。
yolo v3的整体流程
(1)真实标签的转变。voc数据集的标签是代表左上角坐标和右下角坐标
首先取输入图像,经过resize为 448 × 448 448\times448 448×448,同时标签也需要经过变换。假设一个batch-size为2,则先取两张图片,然后对每张图片,经过resize为 448 × 448 448\times448 448×448和标签的变换,变成[3, 448, 448]的格式。对于数据集经过K-means聚类后得到9个anchor base的宽高,将anchor分成三个尺度(L,M,S),每个尺度对应三个anchor base。图片在变换过程中,采用了mixup和label smooth增强方式,对于mixup方式,得专门在输出维度上增加一位保存mixup prob。下面用一个例子来表示真实标签的转变。
batch-size=4,图像经过resize,标签经过转换后得到img_org=[448, 448, 3]和bboxes_org=[[184., 137., 377., 313., 2.], [ 25., 199., 252., 288., 6.]],随后从batch-size里面找一张用来做mixup的图片,同样经过resize和标签转换后得到img_mix=[448, 448, 3]和bboxes_mix=[[174., 230., 276., 337., 13. ], [209., 122., 282., 269., 14. ]]这些bbox都是左上角和右下角坐标, 随后做一个mix操作,mix 操作不改变真实 bbox 的位置和大小,只是将两张图像的真实标签进行np.concatenate得到mix后的图像img= [448, 448, 3]和初始真实框bboxes=[[184., 137., 377., 313., 2., 0.72], [ 25., 199., 252., 288., 6., 0.72], [174., 230., 276., 337., 13., 0.28 ], [209., 122., 282., 269., 14. , 0.28]],注意这里多加一维用于存放mix_prob,以上是数据增强方式,然后用bboxes生成各种标签,随后的过程如下图,对每个初始真实框,分别除每个尺度的stride得到三种尺度的真实 bbox,记为bbox_xywh_scaled,随后对bbox_xywh_scaled里的每个尺度的bbox分别与该尺度的三个anchor计算iou=[0.0038, 0.014, 0.02],如果在某个尺度下iou里面有一个值超过了设定的iou阈值0.3,就将该bbox设置成该尺度下的标签,假如在第二个尺度下iou有满足条件的,首先找出该尺度下的真实bbox属于该尺度下的那个patch,就把lable[2]的相应位置置位。
label = [np.zeros(56, 56, 3, 6+20)), np.zeros(28, 28, 3, 6+20)), np.zeros(14, 14, 3, 6+20))],代表三个尺度的真实标签,14*14代表这个尺度相当于把图片设置成14*14的patch,每个patch产生三个bbox,每个bbox的维度为26,这个26前4位代表初始真实框的中心点和宽高坐标,第5维代表置信度,第6维代表mix_prob,后20维代表做了label_smooth的类别标签 (2)模型的训练
(2)模型的训练
模型的训练采用多尺度训练方式,总体结构如图 1 所示,采用 FPN 的上采样+ 1*1卷积的思想,产生多尺度的预测结果。对于predict_one支路来说,它负责预测大物体,它的输出维度为[bs, 75, 14, 14], 对于predict_two支路来说,它负责预测中物体,它的输出维度为[bs, 75, 28, 28], 对于predict_three支路来说,它负责预测大物体,它的输出维度为[bs, 75, 56, 56]。注意:kaiming he论文中提出的FPN是高阶特征经过upsample后与低阶特征做eltwise操作,即加法的融合操作。而yolov3中的高阶特征经过upsample后与低阶特征做concat操作,即通道方向的拼接操作
(3)yolo v3的损失
yolo v3求损失时是对三个尺度的支路分别求损失,总体来说损失还是三种损失,
- 定位损失(回归损失,yolo v3没有在采取和yolo v1 和yolo v2的 MSE 均方差损失来算回归损失,而是采用了 GIOU 损失来计算)GIOU Loss,
- 置信度损失,yolo v3的置信度损失采用了 Focal Loss来平衡前景和背景不不均衡问题,yolo 这种one-stage的目标检测方法的正负样本不均衡指的是前景太少,而背景太多的问题,也就是反应在置信度上,置信度高的就认为是前景,低的就认为是背景。Focal Loss
- 分类损失:分类损失,采用BCE loss(二元交叉熵损失),不是交叉熵损失,YOLOv3将之前版本的单标签分类(CE)改进为多标签分类,网络结构上将原来用于单标签分类的Softmax分类器(交叉熵采用的是softmax)(Detection层的激活函数,其前一层采用Linear作为激活函数,其他卷积层采用LeakyRelu作为激活函数,这一点和前两版相同)换成用于多标签分类的Logistic分类器(BCE loss就是二分类)。(BCELoss) BCEWithLogitsLoss 一般用于单标签二分类或者多标签二分类。多标签分类
pytorch中BCELoss,BCEWithLogitsLoss和CrossEntropyLoss的区别
YOLOv3深度理解
深度理解yolov3损失函数
YOLO v3网络结构分析