PCIe接口在FPGA上的实现
引言
- PCI Express Base Specification Revision 3.0
- PCI Local Bus Specification Revision 3.0
- 书籍:PCI Express System Architecture,对应那本紫色的《PCI Express 体系结构标准教材》
上面的两个Specification的文档虽然不是从官网找的,但是可信度还是有保证的。我们学校图书馆有那本中文的书,基本上跟规范里的内容是一致的,而且应该更好理解一点。第一个规范里主要看第七章“Software Initialization and Configuration”,里面介绍了PCIe配置空间的大部分寄存器;第二个规范介绍的是PCI协议,PCIe很多都跟PCI兼容,所以这个文档也很重要,这里主要看第六章“Configuration Space”,MSI相关的寄存器只有在这个文档里才有。在开发过程中,Xilinx的IP文档里没有对这些配置寄存器做具体的说明,所以需要查看这两个规范文档。
目前我的需求是实现FPGA和DSP之间利用PCIe链路进行通信,所以准备先从FPGA这边的实现开始介绍,然后再写DSP相关的配置。我采用的方式是DSP作为RC(Root Complex)端,FPGA作为EP(End Point)端。我觉得作为嵌入式开发者,对于PCIe的协议其实不用理解特别深入,能够实现初始化配置、数据传输和中断就可以了。
PCIe协议简介
PCIe的配置空间
首先最重要的就是PCIe的配置空间,当PCIe板卡插到主机上时,host可以通过这一块配置空间获取PCIe设备的信息,同时可以对其进行配置。
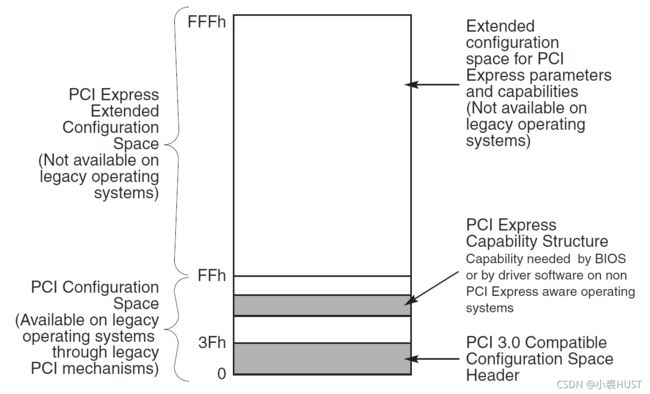
这块空间的前64个字节(0x00~0x3F)作为这块空间的头部,有两种类型,Type 0 和Type 1 。Type 0 是作为端点设备(EP)的设置,Type 1 是作为跟复合体(RC)或者交换结构(Switch)的设置。也就是说,主机和从机,这块配置空间头部是不同的。
BAR空间
BAR,Base Address Register,就是基址寄存器。什么的基址呢?PCIe的数据空间的基址。PCIe的EP有一块自己的数据空间,上游设备可以通过发包的形式直接对指定的数据空间进行读写。
一般只在EP上实现BAR,很少有在RC上实现BAR。因为一般都是主机来方位PCIe设备的数据空间。
如果EP上是32位的BAR,它会先用BAR中低位0的个数来表明BAR对应的数据空间的大小。比如BAR的初始值是“0xFFFF0000”,它的低位有16个0,这几个bit都是硬件上固定的,RC无法改写。这个BAR就表明了它的大小是64kB。RC先读这个BAR,根据低位0 的数量确定了BAR对应的数据空间大小之后,再对高位的“F”进行改写,改成需要的PCIe地址空间的地址。比如改写成“0x68000000”,那么从0x68000000开始的64kB的数据就是这个BAR对应的数据空间。
如果EP是64位的BAR,情况会有点不一样,但是大同小异。
MSI中断
MSI,Message Signaled Interrupts,EP可以用这个给RC发中断。MSI中断实际上是EP向RC发送双字数据包,这个双字的地址和内容由RC给定。就是在系统初始化的时候,需要由RC的系统软件往EP的MSI Capability Structure里面进行配置。不难理解,这里的一组寄存器只有RC能够对它改写,因为这是RC告诉EP可以往哪里写数据就表示发中断;如果EP随便往一个地址写数据,搞不好会出大问题。MSI Capability Structure有下面这几种结构:

这几种结构的区别在于是32位地址还是64位地址,是否支持Per-vector Masking。
地址的区别很好理解,如果是64位地址,就会多一个Message Upper Address的寄存器。
Per-vector Masking是一个可选的功能。支持这一功能的话就会多一个Mask Bits的寄存和一个Pending Bits的寄存器。Mask Bits中每一个bit对应一个MSI vector,MSI总共支持32个中断向量。如果把相应的bit置一,EP想要发送这个中断向量的中断的话,就发不出去,而对应的Pending Bits中的bit会置一。如果把mask撤销,这个被挂起的中断就会被发送。
Message Control寄存器中的有相应的只读的bit来表明目前这个设备是哪种结构的MSI Capability Structure。Xilinx的PCIe的IP好像是支持64bit地址,但是不支持Masking。
Xilinx提供的IP
Xilinx 提供了三个和PCIe相关的IP,就是下面这三个。文档都可以在DocNav里很容易找到。
- Integrated Block for PCI Express
- AXI Memory Mapped to PCI Express
- DMA/Bridge Subsystem for PCI Express
我感觉第一个IP的接口是最复杂的,有四个Stream通道,然后又有很多物理层的配置接口。这个应该是PCIe最底层的IP,Virtex 7系列的FPGA的IP文档还是独立的,但都是“Integrated Block for PCI Express”。这个文档里有一部分内容很重要,就是第二章的PCI Configuration Space,这里介绍了PCIe配置空间的寄存器分布。即使我们实际用的是另外两个IP,也需要通过这个文档查寄存器的位置。而这每个寄存器的功能就要查之前说的PCIe的协议规范了。
第二个IP应该是用AXI接口封了一层,这个AXI接口直接访问PCIe的BAR寄存器对应的数据空间。这个就很方便了,相当于我可以直接从PCIe的数据空间读写数据。这个数据空间既可以是存储器,也可以是外设,总之非常方便灵活。然后这个IP还支持传统的PCI中断,也支持MSI中断。当我们拿它作EP时,可以给RC发中断,这个在之后的具体设计中应该也会经常用到。
第三个IP的功能最强大,它不仅实现了第二个IP的功能,而且实现了数据上下行的DMA通道,这个IP也被称为XDMA。RC可以给它发送DMA传输的描述符,然后它自己就能搬数据。它也有DMA Bypass 的通道,就是RC也可以不用XDMA,而是像第二个IP一样直接对一块数据空间进行读写。
第二个IP和第三个IP我觉得各有侧重点。第三个IP虽然既能DMA传输,又能DMA Bypass地直接访问,但是它的Bypass空间只能有一个BAR寄存器对应,而第二个IP可以灵活地设置多个BAR。而且因为第三个IP实现了XDMA,它把原有的最多32个MSI中断中的16个固定作为了DMA传输中断,剩余16个留给用户;而第二个IP则是32个MSI中断都可以由用户自己使用。
不管是用哪个IP都可以根据实际需求来选择,在每个IP的文档中的Product Specification里面介绍了相关的寄存器。然后要看清楚有些寄存器写着“Only applicable to Root Port cores”,那就是它只能在用作RC的时候使用,要分清楚哪些寄存器是作为RC用的,哪些是作为EP用的。
电路设计
- UG476 - 7 Series FPGAs GTX/GTH Transceivers
- 对应器件的 Integrated Block for PCI Express(PG023、PG054、PG156、PG213)
我用的FPGA是国产的的Virtex 7 系列的XC7VX690T,其实跟Xilinx的是一样的用法。FPGA的PCIe接口是在BANK115上做的,在设计电路的时候要查看上面两篇文档来选择BANK。
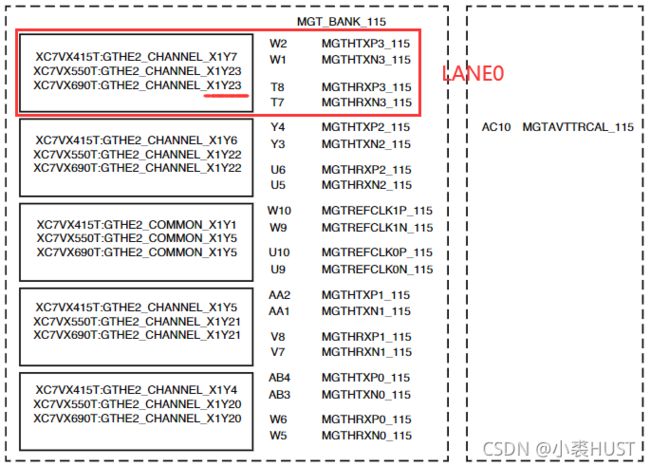
先看Integrated Block for PCI Express,第四章Design Flow Steps里的Constraining the Core里的Transceiver Placemenet里面介绍了每条链路应该放在哪个Block里。要找准型号和封装,就比如我用的是XC7VX690T,就找到下面这张表,然后找到FFG1927的封装,准备用下面红框中的这几个Block来做一个x4的链路。
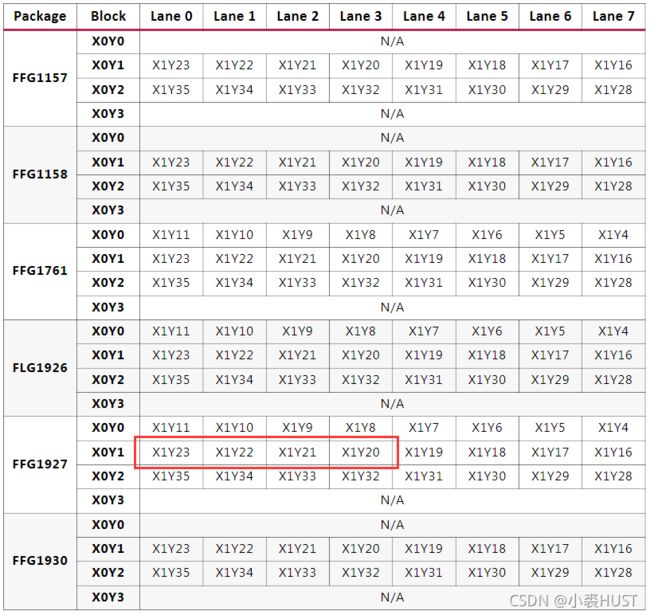
找到Block之后就需要去另一个文档——UG476里面找对应的引脚位置。在附录A里面根据Tranceiver的类型和封装可以找到下面这张图。我们在上面已经知道了LANE0是在X1Y23的Block,就像下面红框中标注的一样,我们用红框内的引脚作为LANE0的引脚。所以我们就依次可以确定LANE0~LANE4的发送和接收的差分对应该接哪几个引脚。
DSP的电路没有什么好说的,PCIe的模块引脚都是固定的。值得一提的是时钟的问题,PCIe通信的双方时钟可以是同步时钟,也可以使异步时钟。如果用异步时钟的话需要注意下面的问题。我用的是异步时钟,但是一般来说同步时钟用得比较多。

Block Design
下面是我的整体的设计,主要是实现了让DSP通过PCIe接口访问FPGA上外接的DDR的功能。
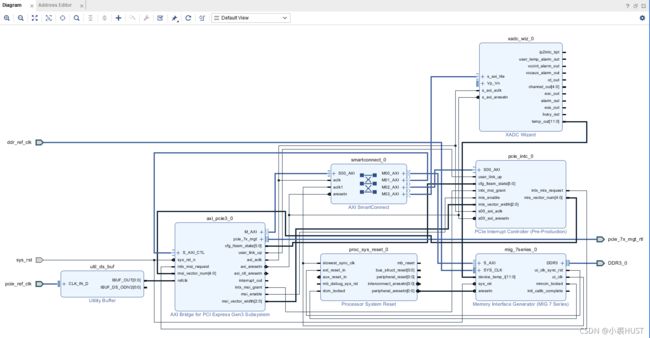
新建一个Block Design之后,加入“AXI Bridge for PCI Express”的IP,点击页面上方的“Run Block Automation”之后,可以做一下简单的配置(之后还要改),它就能够生成一个时钟输入的Buffer

双击对其配置,这里的PCIe Block Location是和具体的引脚引脚分配有关的,已经在前面介绍了。如果这里的Block选得不对,后面的Implement就会报时序的问题。

IP配置中的PCIe ID那一栏可以默认不管;MISC那一栏是中断相关的,根据需求配置即可;AXI:BARs是AXI地址到PCIe地址的转换,这个应该是用了AXI Slave接口之后才会用到,我这次的设计里没有用Slave接口所以这个也没配置;Debug Options也没啥东西。所以只剩下这个PCIe的BARs了,我分配了三个BAR空间,如下面的图所示。
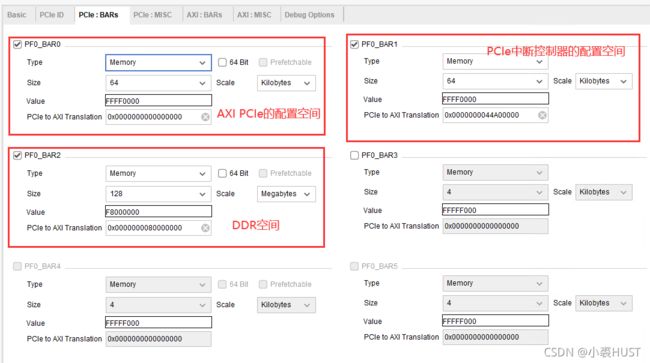
BAR0指向的是AXI PCIe的配置空间,它其实非常小,64kB已经完全能够访问到所有寄存器了;BAR1是指向的是我自己做的IP,用来从向RC发MSI中断;BAR2指向的是DDR内的128MB的数据空间。这里的PCIe to AXI Translation只要把AXI的基址填上去就行,要跟Address Editor里面的相对应。Address Editor里的地址我是自动分配的(很多可能BAR访问不到,但这不要紧)。用了XADC是因为DDR的MIG需要一个温度输入,如果MIG里面能直接Enable XADC那就很省事了,但我这不行所以在外面加了XADC。

一些经验
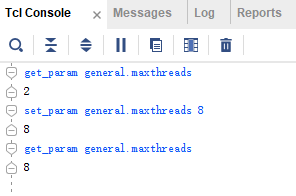
Windows下的Vivado默认线程(thread)数是2个,Linux系统下的默认线程数是8个。可以用下面的tcl命令获取当前的最大线程数:
get_param general.maxthreads
Windows下的支持的最大线程数是8个,可以用下面的tcl命令更改
set_param general.maxthreads 8
每次启动Vivado,这个最大线程数都会回到默认的2个,可以用这个博主的方法来一劳永逸地更改Vivado的默认线程数:链接
线程数量越多,实现每个job的速度越快。在Run Setting里面的Number of jobs是指可以同时运行的job个数,我们一般只有一个实现,所以即使把这个设置得很大,也不会有加速的效果。Number of jobs的设置在预先独立综合每个IP的时候很有用,每个IP可以各自综合,不同IP综合之间的并行会受到这个数量限制。

我之前为了在一个工程里实现两个方案,所以新建了一个Run,同时把不用的源文件disable掉。但我看别人好像是用不同的约束文件来限制不同的Run,但是源文件是不用改的。我这么做的时候要改源文件,有时候会报一些奇怪的报错,但确实能在一个工程里做两个实现。
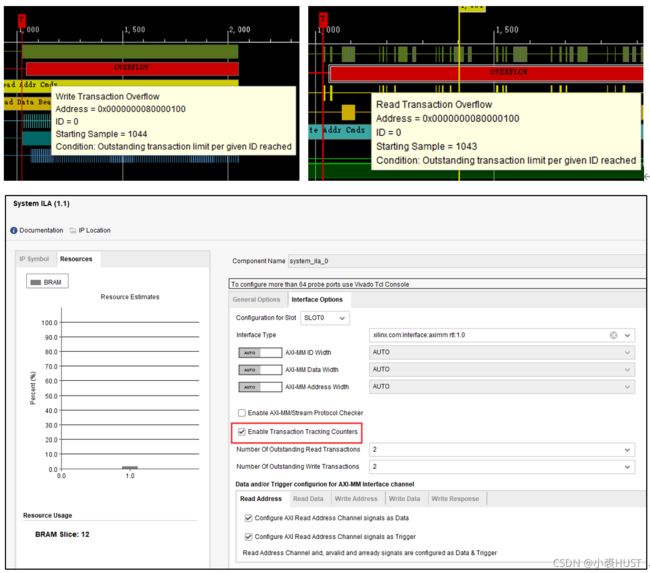
最后是在读写DDR的时候,出现了这个Transaction Overflow的问题,但是数据都是没错的。DDR在读写的时候会有好几个Outstanding的Transaction,就是那种在读写,但是还没有响应完成的事务。我用的是加在Block Design里面的System ILA,只要在这个IP里面把Enable Transaction Tracing Counter的勾去掉或者把计数值加大就好了。