人体姿态识别方案详解
原文:http://www.51din.com/235572.html
文章目录
姿态迁移简介
方案详解
Mediapipe
Mediapipe数据获取
多人姿态识别方向探索
PoseNet
MoveNet
OpenPose
OpenMMD
总结
参考链接
姿态迁移简介
目前AR,VR,元宇宙都比较火,需要实际场景和虚拟中进行交互的情况,因此研究了通过摄像头获取图像进行识别,本文主要概述了在人体身体姿势识别跟踪方面的一些调研和尝试。
通过各个方案,我们可以从RGB视频帧中推断出整个身体的关键特征点,从而根据这些关键特征点去做扩展,比如迁移到unity模型中等。
从识别角度来说,我们可以分成两个大方向,一是人体身体关键特征点识别,这里特征点分为2d特征点和3d特征点,部分方案只支持2d特征点;二是人体动作识别,比如用户在做什么动作,举一个很简单的例子,我们可以通过mediapipe识别出用户在做俯卧撑或者深蹲等。
从用户体验角度来说,我们可以分成实时摄像头传输和对视频进行处理两个方向。摄像头实时传输的话就必须要做到对视频每一帧RGB图像做到即时处理,这里就牵扯到优化效率问题。对视频进行处理的话可以采用对视频后期处理的形式去处理,一般动捕方案都是这么做的。
方案详解
Mediapipe
Google出品,可以实现人脸检测、姿态识别,手势识别等很多效果,并且可以在多平台高效的输出。这里强调下Mediapipe检测出来的特征点数据均为3d,有空间感。
Mediapipe检测是基于BlazeFace模型,明确地预测了两个额外的虚拟关键点,这些虚拟关键点将人体中心、旋转和缩放牢固地描述为一个圆圈。受莱昂纳多的维特鲁威人的启发,我们预测了一个人臀部的中点,外接整个人的圆的半径,以及连接肩部和臀部中点的线的倾斜角。
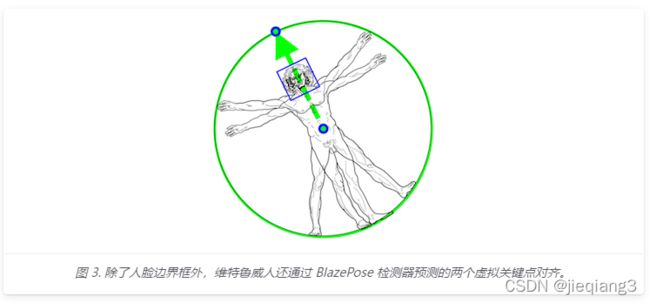
Mediapipe数据获取
从Mediapipe上获取的身体的33个特征点,具体如下图,对此33个特征点进行判断。
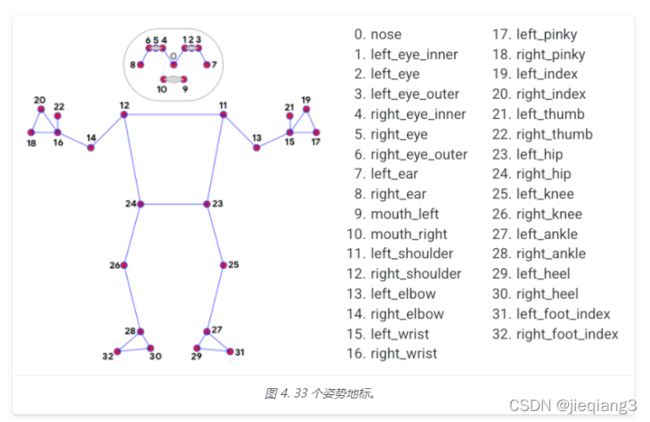
主要通过角度来判断:
float Angle(NormalizedLandmark ver1, NormalizedLandmark ver2, NormalizedLandmark ver3, NormalizedLandmark ver4){
return Vector3.Angle(new Vector3(ver1.X, ver1.Y, ver1.Z)- new Vector3(ver2.X, ver2.Y, ver2.Z),
new Vector3(ver3.X, ver3.Y, ver3.Z)- new Vector3(ver4.X, ver4.Y, ver4.Z));}多人姿态识别方向探索
Mediapipe 在人脸上是支持多人的,但是在姿态识别上目前只支持单人。在实验了网上能搜到的各种方案之后,有一种方案目前是可行的,但是在性能上会比较卡顿。
既然Mediapipe支持单人,那我们把视频画面中的多人画面拆分成多个单人就行了。
这里我采用的是OpenVINO中的行人检测模型。(我尝试了多种方案,YOLO-unity、Barracuda-Image-Classification和OpenVINO后发现OpenVINO效果最佳)OpenVINO ToolKit是英特尔发布的一套深度学习推断引擎,支持各种网络框架。对此不熟悉的同学可以参考OpenVINO开发系列文章汇总进行较为系统的学习。

具体思路就是通过OpenVINO识别出人物范围框,然后使用Opencv进行图像分割,单人图像传递给Mediapipe sdk去做单人姿态识别,然后进行汇总。目前该方案在移动端测试效果较为卡顿,不是很理想。
PoseNet
PoseNet是TensorFlow和谷歌创意实验室合作发布的专门用于姿态估计的一种技术方案。PoseNet可用于估计单个姿势或多个姿势,该算法有一个版本可以仅检测图像/视频中的一个人,另一个版本可以检测图像/视频中的多个人。
流程主要有两个阶段:
输入RGB 图像通过卷积神经网络馈送。
单姿势或多姿势解码算法用于解码来自模型输出的姿势、姿势置信度分数、关键点位置 和关键点置信度分数。
同Mediapipe一样,我们来看看PoseNet给到我们的关键姿势点。PoseNet提供了17个关键点,不同于Mediapipe提供的3d数据点,PoseNet提供的是关键点的2d坐标,x和y。以及关键点可信度分数,使用者可以根据实际情况去做判断,范围在0.0-1.0之间,越接近1.0表示识别出来的点越正确。
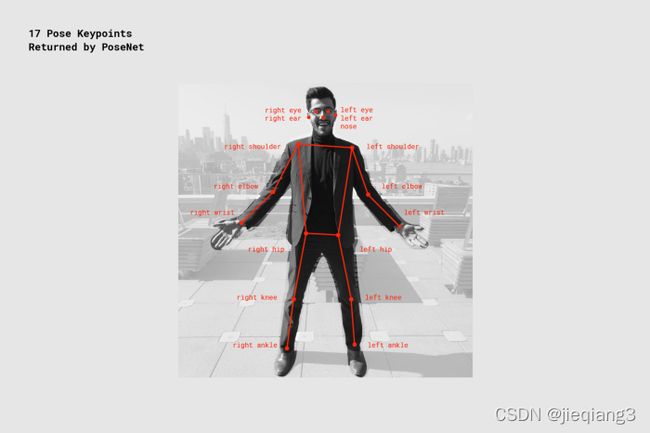
ok,我们来看下我把posenet这一套通过tf-lite加载的形式在unity上的呈现效果。

MoveNet
MoveNet是一种超快速且准确的模型,可检测身体的 17 个关键点。该模型在TF Hub上提供,有两种变体,称为 Lightning 和 Thunder。Lightning 适用于延迟关键的应用程序,而 Thunder 适用于需要高精度的应用程序。在大多数现代台式机、笔记本电脑和手机上,这两种模型的运行速度都比实时 (30+ FPS) 快,这对于现场健身、健康和保健应用至关重要。
我们可以看到movenet的识别出来的点的效果如下:

官方从tf hub 加载模型代码:
model_name ="movenet_lightning"if"tflite"in model_name:if"movenet_lightning_f16"in model_name:
!wget -q -O model.tflite https://tfhub.dev/google/lite-model/movenet/singlepose/lightning/tflite/float16/4?lite-format=tflite
input_size =192elif"movenet_thunder_f16"in model_name:
!wget -q -O model.tflite https://tfhub.dev/google/lite-model/movenet/singlepose/thunder/tflite/float16/4?lite-format=tflite
input_size =256elif"movenet_lightning_int8"in model_name:
!wget -q -O model.tflite https://tfhub.dev/google/lite-model/movenet/singlepose/lightning/tflite/int8/4?lite-format=tflite
input_size =192elif"movenet_thunder_int8"in model_name:
!wget -q -O model.tflite https://tfhub.dev/google/lite-model/movenet/singlepose/thunder/tflite/int8/4?lite-format=tflite
input_size =256else:raise ValueError("Unsupported model name: %s"% model_name)# Initialize the TFLite interpreter
interpreter = tf.lite.Interpreter(model_path="model.tflite")
interpreter.allocate_tensors()defmovenet(input_image):"""Runs detection on an input image.
Args:
input_image: A [1, height, width, 3] tensor represents the input image
pixels. Note that the height/width should already be resized and match the
expected input resolution of the model before passing into this function.
Returns:
A [1, 1, 17, 3] float numpy array representing the predicted keypoint
coordinates and scores.
"""# TF Lite format expects tensor type of uint8.
input_image = tf.cast(input_image, dtype=tf.uint8)
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
interpreter.set_tensor(input_details[0]['index'], input_image.numpy())# Invoke inference.
interpreter.invoke()# Get the model prediction.
keypoints_with_scores = interpreter.get_tensor(output_details[0]['index'])return keypoints_with_scores
else:if"movenet_lightning"in model_name:
module = hub.load("https://tfhub.dev/google/movenet/singlepose/lightning/4")
input_size =192elif"movenet_thunder"in model_name:
module = hub.load("https://tfhub.dev/google/movenet/singlepose/thunder/4")
input_size =256else:raise ValueError("Unsupported model name: %s"% model_name)defmovenet(input_image):"""Runs detection on an input image.
Args:
input_image: A [1, height, width, 3] tensor represents the input image
pixels. Note that the height/width should already be resized and match the
expected input resolution of the model before passing into this function.
Returns:
A [1, 1, 17, 3] float numpy array representing the predicted keypoint
coordinates and scores.
"""
model = module.signatures['serving_default']# SavedModel format expects tensor type of int32.
input_image = tf.cast(input_image, dtype=tf.int32)# Run model inference.
outputs = model(input_image)# Output is a [1, 1, 17, 3] tensor.
keypoints_with_scores = outputs['output_0'].numpy()return keypoints_with_scores实际生产过程中,movenet主要通过tf-lite去加载计算,可以分为单人和多人。tf-hub地址如下:地址。测试发现,从帧率和效果上来说,movenet比mediapipe效果要好一点。
但是在unity使用中,我发现movenet的tf-lite模型在unity中遇到了unity barracuda插件转换的问题,单人的tf-lite可用,但是多人无法转换。已知是unity barracuda插件问题,已提交issues,但目前还没走通。
不熟悉unity barracuda的同学可以移步这里
主要用于在untiy中集成神经网络算法。
OpenPose
OpenPose是我在github上搜到的一个人体姿态识别的一个算法方案。
主要功能:
2D实时多人关键点检测:15、18 或25 关键点身体/足部关键点估计,包括6 个足部关键点。运行时不受检测到的人数的影响。2x21-keypoint 手部关键点估计。运行时间取决于检测到的人数。70个关键点人脸关键点估计。运行时间取决于检测到的人数。
3D实时单人关键点检测
其实可以理解成在效果产出和姿态识别角度来说,是mediapipe和posenet的综合体。
效果如下:

OpenMMD
OpenMMD是一个可以直接分析现成视频(各种MP4, AVI等视频格式),自动生成vmd动作文件的工具。
这个方案无法做到实时转换,即使你的输入源是摄像头的话,也必须录完以后生成动捕文件,然后再把动捕文件绑定到模型上才可以完成。
OpenMMD具体使用教程在b站上有一个大佬总结的很清楚了,但有一个问题,他只能绑定在mmd模型上,mmd模型在游戏里的通用性并不大,属于比较小范围的应用。尝试了几种模型之间互转的方案,Blender等,但无果,转换起来没那么简单。
这是我迁移后的效果,左边是mmd模型,成功跑通。
总结
以上五种方案,简单总结如下:

参考链接
BlazeFace
Mediapipe Pose
PoseNet
MoveNet
OpenPose
OpenMMD