人和工具的关系_Python | 如何解析非结构化文档文本中的隐蔽关系(二)?
点蓝字关注 设为星标 ☆ 优先赏阅数据化审计:问题导向、应用至上、解决痛点
内容导读专业的 NLP 工具介绍和 Python 实例分析代码声明
本文中的所有信息和数据都是虚拟的,仅为说明数据化风控的思路和过程,不代表真实的交易情况。
代码很业余,只为抛砖引玉,拓展思路。专业人士请忽略!
全文内容较多,分为两个部分:
第一部分:业务背景介绍,结合实例介绍自然语言处理(NLP)的相关技术。( 文章链接 )
第二部分:专业的自然语言处理(NLP)工具介绍和 Python 代码实例。
第二部分
专业的自然语言处理(NLP)工具介绍和 Python 代码实例。
专业的NLP工具
早期的NLP,主要是基于规则、字典或传统的机器学习方法,业界比较有名的哈工大 LTP、HanLP。 最新的版本基本是基于深度学习方法了。
专业的NLP工具基本都有如下功能:
分词。tokenize,Word Segmentation 。
词性标注 POS。标注文本中出现的词组的词性,如名词、动词等。
命名实体识别 NER。识别出文本中出现的地名、人名、公司名、组织名等。
依存句法分析。识别出文本中包含的主谓关系、动宾关系、定中关系等。
目前专业的NLP工具主要有:
Stanford CoreNLP。由斯坦福大学开发,基于Java环境,也可以在Python中进行调用。新版本支持中文,有专门的中文模型。功能很强大,比如Stanford的命名实体识别,可以把Time, Location, Organization, Person, Money, Percent, Date七类实体很清晰的标注出来。详细情况见官网:https://stanfordnlp.github.io/CoreNLP/index.html。
LTP:Language Technology Platform。由哈工大研发,LTP提供了一系列中文自然语言处理工具,可以使用这些工具对于中文文本进行分词、词性标注、句法分析等等工作。目前基于Pytorch的LTP4 已经发布。
HanLP。HanLP是一系列模型与算法组成的NLP工具包,由大快搜索主导并完全开源,目标是普及自然语言处理在生产环境中的应用。1.X版本基于Java开发,基于深度学习的HanLP2.0已于2020年初发布。
LTP的安装和配置
LTP:Language Technology Platform 是由哈工大研发的NLP工具平台,基于Pytorch的LTP4发布后,LTP的安装和配置都较之前的版本便捷了很多。本文也通过LTP,进行实例分析。
1.安装Pytorch
新版的LTP是基于 Pytorch 的,在安装之前需要根据机器配置、windows版本等,选择正确版本的Pytorch安装。具体可以访问 https://pytorch.org/ ,在页面的 INSTALL PYTORCH 进行选择,生成 pip 命令行参数(绿框内)。如下图:
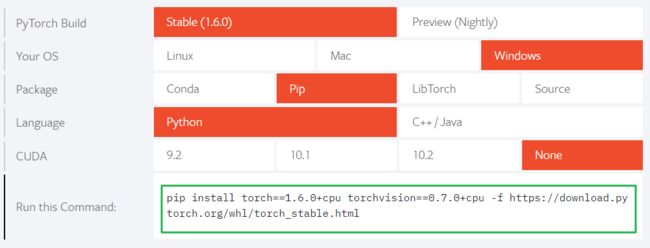
2.安装LTP4
安装LTP4是非常简单的,在命令行执行 pip install ltp 即可完成。
详细操作参见LTP 官网( https://github.com/HIT-SCIR/ltp )和中文说明文档。网址:https://ltp.readthedocs.io/zh_CN/latest/index.html。
3.下载模型数据
LTP官网提供了已训练后的模型,下载解压后可以直接调用。下载地址:https://github.com/HIT-SCIR/ltp。
模型区分不同的版本,一般直接下载 Base(v2) :http://39.96.43.154/ltp/v2/base.tgz
下载后,带文件夹解压到指定的目录,如:D:\ltp_data\base。
数据分析环境
本文分析所使用的环境具体如下:
| 软件或环境 | 说明 |
|---|---|
| Win10 64位 | 系统环境 |
| Python 3.6.2 : Anaconda custom (64-bit) | 数据分析语言平台 |
| torch 1.6.0+cpu | pytorch LTP的环境 |
| ltp 4.0.9 | LTP 4 NLP 工具库 |
| networkx 1.11 | 复杂网络分析库 |
实现代码
代码可以按住屏幕,左右滑动查看
1.环境初始化
# -*- coding:utf-8 -*-import
2.进行分词
## 对中文文本进行分词
## LTP支持自定义词语,比如文中的“原宜”如果不添加为自定义词语,就会被拆成两个字。
## 添加自定义词语
nerwords = ['原宜']
curltp.add_words(words=nerwords, max_window=4)
segs, hidden = curltp.seg(cursents)
print(segs)
LTP支持自定义词语,比如文中的“原宜”如果不添加为自定义词语,就会被拆成两个字。

3.进行命名实体识别
## 找出公司名、人名
curners = curltp.ner(hidden)
## 将第一步识别出来的命名实体作为自定义词组存放到 nerwords
nerwords = []
for idx, curner in enumerate(curners):
for tag,start,end in curner:
print(tag,"".join(segs[idx][start:end + 1]))
nerwords.append("".join(segs[idx][start:end + 1]))
## 删除重复的值
nerwords = list(set(nerwords))
非结构文本数据中的公司名(Ni)和人名(Nh)都识别出来了。

3.进行依存句法分析并可视化
## 看看找到识别出来的命名实体在文本中是什么关系
## 将第一步识别出来的命名实体作为自定义词组 重新分词
curltp.add_words(words=nerwords, max_window=14)
segs2, hidden2 = curltp.seg(cursents)
print(segs2)
可以看到分词结果,将识别出来的公司名、人名都作为单独的词语了

## 依存句法分析
curdeps = curltp.dep(hidden2)
## 并绘制出和已出现的公司名人名相关的依存关系图
plt.clf()
plt.rcParams['font.sans-serif']=['SimHei']
plt.figure(figsize=(10,10))
## 建立无向图G
G = nx.Graph()
## 添加边
## 添加识别出来的公司名和人名与核心人的关系
for word in nerwords:
G.add_edge(word,nerwords[0], attrtype=x)
## 添加依存关系中出现识别出来的公司名和人名的关系
for idx, curdep in enumerate(curdeps):
for i,j,x in curdep:
if (segs2[idx][i-1] in nerwords) or (segs2[idx][j-1] in nerwords):
G.add_edge(segs2[idx][i-1],segs2[idx][j-1], attrtype=x)
## 绘制关系网络并显示
pos = nx.spring_layout(G)
nx.draw(G, pos=pos, with_labels=True)
plt.axis("off")
plt.show()
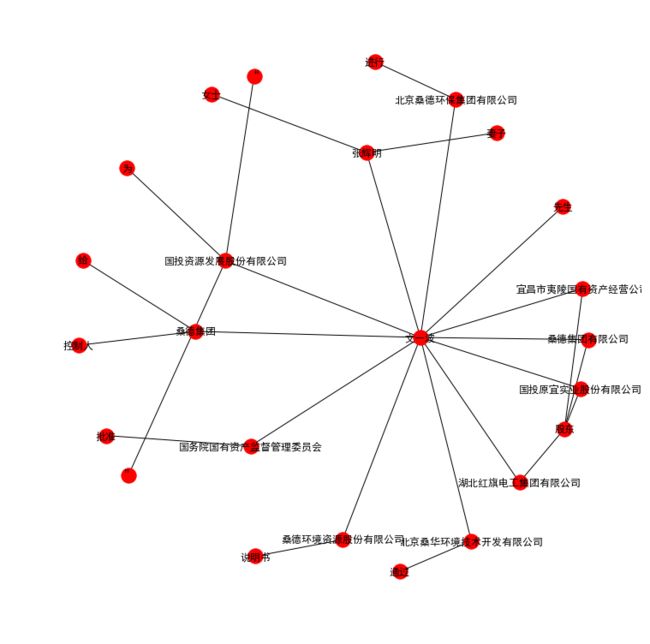
最后的结果如下图,基本可见非结构化文本中的重要公司、人和关系。
如果是多个文档一起处理,也可以识别出不同非结构文档间是否存在隐蔽的关系。
参考文献
自然语言处理NLP, [E/OL], https://easyai.tech/ai-definition/nlp/
命名实体识别NER, [E/OL], https://easyai.tech/ai-definition/ner/
什么是依存句法分析?, [E/OL], https://easyai.tech/ai-definition/constituency-based-parse-trees/#what2
相关阅读
如何快速Get到领导讲话重点?
用Excel从非结构化数据中提取关键信息
一文看会!半结构化数据的处理和审计应用实例
