美国某超市销售数据分析
本次分析以美国某超市4年的销售信息作为数据基础,运用Excel、MySql和Tableau进行数据处理、分析和可视化,从订单维度、客户维度、商品维度、时间维度、区位维度、生命维度、购买周期等 7个维度对该超市数据进行全面的分析。
一、数据概述
1.数据集概述
来源:kaggle (点击下载数据)
该数据是美国某超市在2014-2017年的销售数据,共有21个字段,9994条数据。包括订单号、下单日期、客户编号等多个字段。该超市出售的商品分类只有家具,科技产品以及办公用品。
2. 数据集内容
| Row ID |
行号,索引号 |
Customer ID |
客户编号,由客户姓和名的首字母+五位数字组成 |
| Order ID |
订单编号,由US/CA-年份-6位数字组成 |
Customer Name |
客户姓名 |
| Order Date |
下单日期 |
Segment |
客户身份,由顾客、家庭办公室和公司组成 |
| Ship Date |
发货日期 |
Country |
购买国家 |
| Ship Mode |
货物所在仓位级别 |
City |
购买城市 |
| State |
购买所在州 |
Sub-Category |
子分类 |
| Postal Code |
邮政编码 |
Product Name |
产品名称 |
| Region |
区域 |
Sales |
货物出售单价 |
| Product ID |
产品id |
Quantity |
货物数量 |
| Category |
分类,家具、科技产品及办公用品 |
Discount |
折扣,实际出售总价为单价*数量*(1-折扣) |
| Profit |
利润,负数表示亏损 |
二、数据清洗
1.修正日期
打开从kaggle上下载的文件后发现日期中的“日”变为“年”,“年”变为“日”,应将日期修改为正确的数据。
先将数据按照符号“/”分成三列,用“right”函数提取“日”,用“20&”生成年,再用“date(年,月,日)”函数生成日期,得到结果如表二所示。
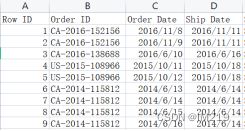
图 1修改前日期
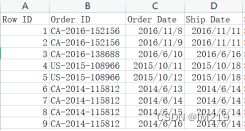
图 2 修改后日期
2、去除重复值
操作:全选/删除重复项
发现该数据集没有重复项
3、查找缺失值
在列尾输入函数“=COUNTBLANK(区域)”
发现该结果集没有空值
4、查找异常数据
(1)利用筛选功能发现sales和Quantity中存在非数值型数据,删除后剩下数据9897条。
(2)在Quantity、Discount、Profit列尾输入公式“=countif(区域,“<0”)”
发现Quantity、Discount没有异常数据,Profit有1871个数据小于0,说明有一部分业务发生亏损。
5、新增一列数据总交易额
函数为“=sales*quantity*(1-discount)”
三、问题
本文希望通过以下几个部分进行分析:
1.订单维度:笔单价和连带率是多少?订单金额与订单内商品件数的关系如何?
2.客户维度:客单价是多少?客户消费金额与消费件数的关系如何?
3.商品维度:商品的价格定位是高是低?哪种价位的商品卖得好?哪种价位的商品带来了实际上最多的销售额?
4.时间维度:各月/各日的销售情况是什么走势?可能受到了什么影响?
5.区位维度:客户主要来自哪几个国家?哪个国家是境外主要市场?哪个国家的客户平均消费能力最强?6.客户行为:客户的生命周期、购买周期如何?
本文的主要研究对象是美国某超市2014-2017的销售情况信息,希望通过分析超市四年的历史销售数据,从不同维度出发分析超市经营状况,挖掘出提高销售额、销量的销售策略。
四、数据分析
1、订单维度
运用excel的数据分析功能对Quantity、Profile、Sumprice进行描述性统计,再利用函数“==SUMPRODUCT((区域 <>"")/COUNTIF(区域,区域&""))”得出订单数量,得出结果如下。
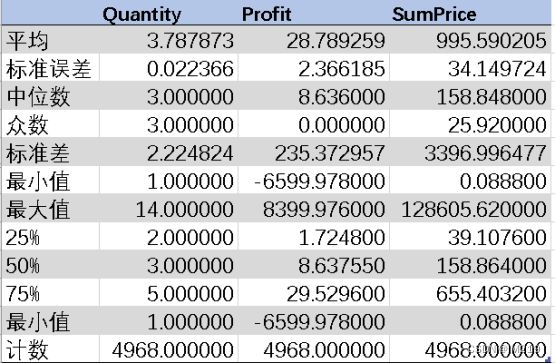
由图4可知,有效订单共有4977单,订单平均单价为995.6美元,订单平均商品数为3.8件,说明超市订单的商品以单价高的商品为主;此外,订单商品数的均值在中位数和第三分位数之间,订单总金额的均值大于第三分位数,说明订单总体差异大,又部分购买力很强的客户。
绘制出经过筛选的交易金额分布图,订单商品数分布图,利润分布图:
(需要筛选是因为数据量太大,会导致组间对比不明显,筛选掉数值大但出现频率小的部分)

图 5 订单总额分布图(金额在1000以下)
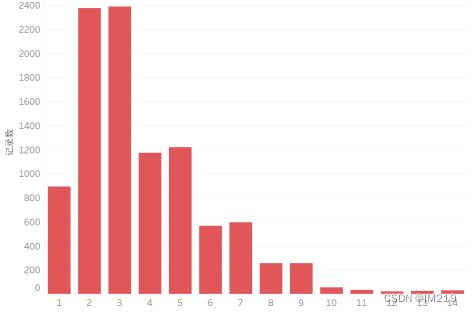
图 6 购买数量分布图
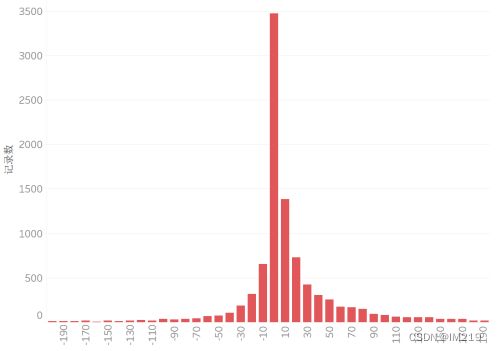
图 7 订单利润分布图(在-200至200之间)
可以看出交易总价在50美元及以下的居多,订单商品数多在5件以内,5~9也比较多,而利润多在25美元以下。
绘制出经过筛选的订单总额—商品数和订单总额—利润的散点图:
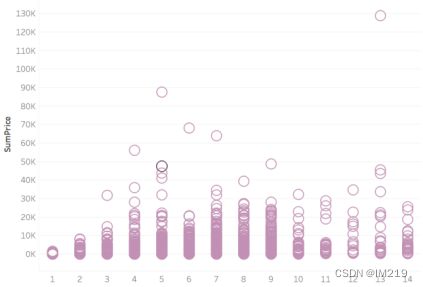
图 8 订单总额—商品数
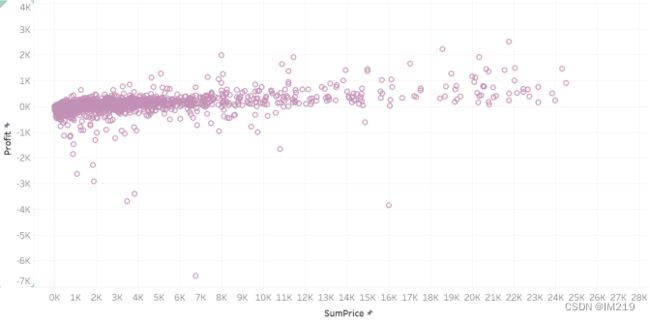
图 9 订单总额—利润(订单总额<25000)
订单商品数和订单总金额的分布比较均匀,而在获利方面交易总金额在4000以下的订单基本收支平衡甚至可能出现亏损,而交易总金额在10000以上的订单基本都能盈利。
2、客户维度
统计各客户的订单物品数,交易总额,以及利润:

人均订单数为6,中位数也是6。客户平均购买数为50.63,在中位数和Q3分位数之间。交易总价的平均数为12423美元,在中位数和Q3分位数中间。从客户均获利为361美元,也在中位数和Q3分位数之间,说明客户的购买力分布比较均匀,从客户中获利的程度也较为平均,但也存在极少数购买力极强的客户。
绘制经过筛选的客户消费总价的直方图与订单总价和交易量的散点图:
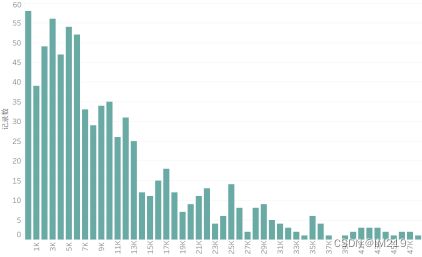
图 10 客户消费金额分布
客户消费金额的分布呈现双峰中尾形态,在1000美金以下,3000美金,5000美金和10000美金有4个峰值。客户群体比较健康,而且规律性比订单更强,同时拥有一定数量消费能力强的用户。
3、商品维度
绘制商品单价的直方分布图

图 12 商品单价分布图(sales<1000)
可以看出该店卖出去的主要商品单价在5~15美元之间,15~25美金的商品也比较多,50~200美金的商品分布较均匀且少,所以主要还是以价格低廉的商品为主要市场。
绘制单价与出售商品数的散点图:
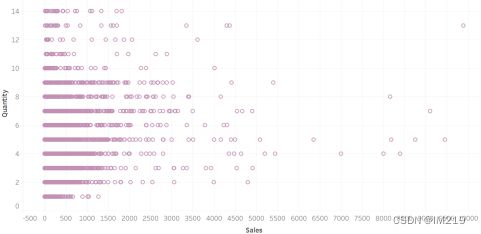
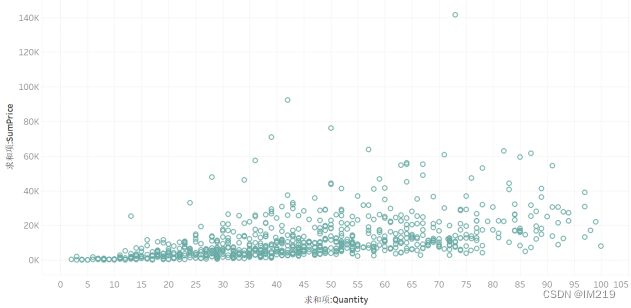
图 13 商品单价与售出数量散点图(sales<10000)
在单价500美金以下的商品销售得比较多,而单价500~3000美金的商品也有一定的市场。绘制单价与销售总价和单价与总利润的散点图:
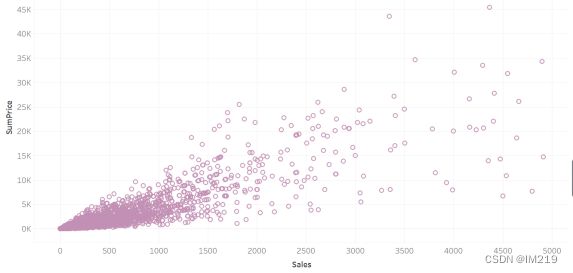
图 14 商品单价与销售总价散点图(sales<5000)
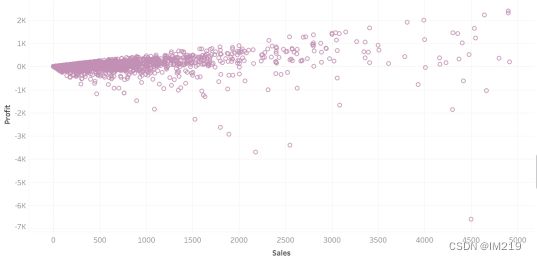
图 15 商品单价与售出总利润散点图
能看出销售总额和销售单价呈正比,单价高的商品能带来更高的销售额,也能带来更高的利润。因此建议商店多选一些单价高的商品来获取更高的利润。
4、时间维度
以月为单位绘制时间销售图:
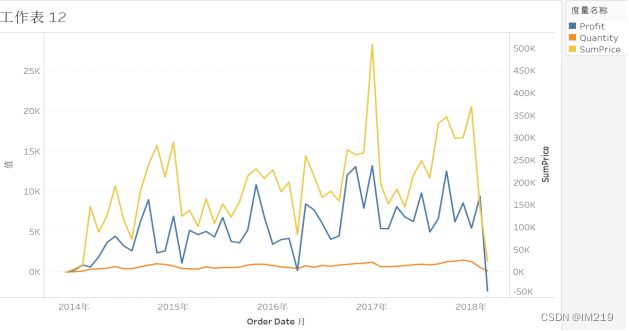
可以看出四年的销售状况每年都有类似的循环,在1月,7月,10月和11月的销售状况最好,可能是有营业活动造成的。
5、地区维度
因订单销售国家都在美国,因此只按城市划分销售额和客户数:
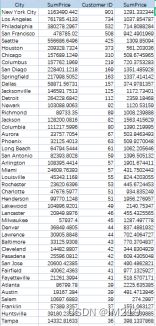
可以发现纽约、洛杉矶是销售额和客户量最高的两个城市,费城、旧金山、西雅图、休斯顿、芝加哥的销售额和客户量比起其他城市高出了许多,应重点关注这些城市做销售计划。平均消费额上底特律和凤凰城都达到了两万美金以上,说明这些城市的客户虽不多但消费水平高,应当去开发出这些城市更多的客户。
6、客户消费行为分析
6.1客户生命周期
按客户编号分组创建客户消费的初始日期和最后日期,并统计前后日期累计用户量:

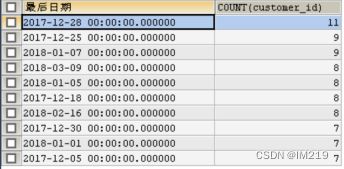
能看出无论初始还是最后的客户分布都较为均匀,说用户的生命周期短的用户并不多,大多数客户的生命周期比较均匀。
客户生命周期的整体状况:
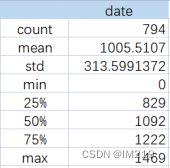
共有794位客户,平均生命周期为1005.5天超过2.5年,与中位数1092天差不到100天,Q1分位数达到829天,说明大部分消费客户的生命周期都比较长,不存在两极分化的情况。
接着绘制客户生命周期的直方图:
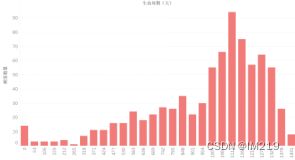
可看出一次性客户占比不多,大部分客户的生命周期都有650天以上,其中1000天以上的用户超过了其中的一半。证明该超市的主要客户是忠实客户,超市在他们眼中是消费的首选。超市的重点应该是为这些客户制定更好的消费策略来促进他们继续消费,以超市的知名度能使不少初次消费者转换成忠实客户。
6.2 客户购买周期
计算客户每两次交易所相差的时间,并按客户分组绘制直方图:
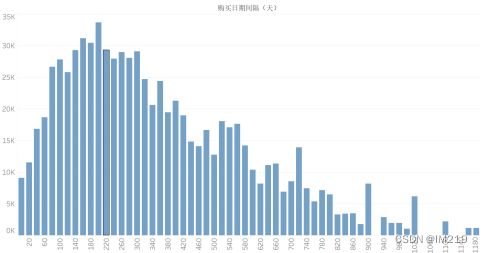
大部分客户的购买间隔期为80~320天,可以建议每隔三个月推送一次优惠活动信息。
五、总结
1.订单维度
有效订单共计4977单,笔单价为995.6美元,连带数为3.8件,说明以单价高的订单为主。订单商品数和订单总金额的分布比较均匀,而在获利方面交易总金额在4000以下的订单基本收支平衡甚至可能出现亏损,而交易总金额在10000以上的订单基本都能盈利。
2.客户维度
客户人均消费为12423美元,客户的购买力分布比较均匀,从客户中获利的程度也较为平均,但也存在极少数购买力极强的客户。客户群体比较健康,而且规律性比订单更强。
3.商品维度
出该店卖出去的主要商品单价在5~15美元之间,主要还是价格较低的商品市场,销售量也主要集中在低价商品。销售总额和销售单价呈正比,单价高的商品能带来更高的销售额,也能带来更高的利润。因此建议商店多选一些单价高的商品来获取更高的利润。
4.时间维度
四年的销售状况每年都有类似的循环,在1月,7月,10月,11月,12月的销售状况最好,但是以为没有数据支撑,无法确定是什么原因造成的。
5.区位维度
纽约、洛杉矶是销售额和客户量最高的两个城市,费城、旧金山、西雅图、休斯顿、芝加哥的销售额和客户量比起其他城市高出了许多,应重点关注这些城市做销售计划。平均消费额上底特律和凤凰城都达到了两万美金以上,说明这些城市的客户虽不多但消费水平高,应当去开发出这些城市更多的客户。交易额高的城市主要都是一些沿海城市,可以考虑在运输上找到更优惠的策略。
6.生命周期
一次性客户占比很少,大部分客户的生命周期都有650天以上,其中1000天以上的用户超过了其中的一半。证明该超市的主要客户是忠实客户,超市在他们眼中是消费的首选。超市的重点应该是为这些客户制定更好的消费策略来促进他们继续消费。