语义分割基础讲解
文章目录
-
- 1. 常见的分割任务
- 2. 常见的分割网络
- 3.语义分割常见数据集格式
-
- 3.1 PASCAL VOC数据集
- 3.2 MS COCO数据集
- 4.语义分割结果的具体形式
- 5.常见的评价指标
-
- 5.1 举例说明
- 6 语义分割标注工具
-
- 6.1 Labelme
- 6.2 EISeg
- 7. 参考
1. 常见的分割任务
语义分割(semantic segmentation):可以理解为一个分类任务,对图片上每个像素进行分类。经典网络:FCN实例分割(Instance segmentation): 相比于语义分割对每个像素进行分类,比如所有飞机位置都用同一个颜色表示。但在实例分割任务中,分割的结果会更加精细些。针对同一个类别的不同目标,也有不同的颜色进行区分。经典网络:Mask R-CNN全景分割(Panoramic segmentation): 全景分割可以认为是语义分割+实例分割。其实在我们实例分割任务中,我们并不关注背景情况,比如背景中可能有蓝天,草地,在我们实例分割任务中我们是不会关注这些的,只是关注每个目标的分割边界。而在全景分割任务中,我们不仅需要将每个目标给分割出来,还需要将背景进行划分,比如背景中的蓝天、草地、马路等等。 经典网络:Panoptic FPN
语义分割,实例分割,全景分割这三个分割任务的精细程度是逐级递增的。

2. 常见的分割网络
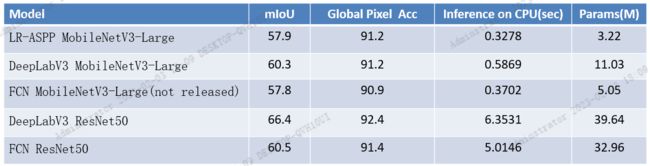
官方源码https://pytorch.org/blog/torchvision-mobilenet-v3-implementation/#semantic-segmentation
3.语义分割常见数据集格式
3.1 PASCAL VOC数据集
PASCAL VOC在语义分割任务中,提供的分割标签形式是PNG图片

在PNG图片中记录了每个像素所属的类别信息,注意这里提供的PNG图(P模式)是以调色板模式存储的(即只存储颜色的索引,通过索引与RGB颜色表线性对应,可以达到显示彩色图像的效果,节省图像存储占用的空间)。调色板模式存储的图片其实是一张单通道的图片,也就是黑白图片。为什么可以显示彩色图片呢?因为提供了调色板,针对像素0-255都对应一个颜色,所以可以将它映射到彩色图像中。(比如像素0对应的是(0,0,0)黑色,像素1对应的是(127,0,0)深红色,像素255对应的是(224,224,129))。
- 这里需要注意下,你如果使用python的
PIL包去读取图片的话,它默认读取进来的是调色板模式的图片(P模式), 它的通道数为1,对应的是一张图片每个像素的索引。当然你可以将它转化为RGB图片,但我们在训练的时候只需要关注每个像素它所属的类别索引就可以了,因此target需要按调色板模式读取标签图片,对于image的话则需要转化为RGB``
img = Image.open(img_path).convert('RGB')
target = Image.open(mask_path)
- 对于分割的标签图片
mask(如上图),我们可以看到目标的边缘,会有一个特殊的颜色(白色)进行分割(255),还有图片中的一些特殊区域(难分割区域),也会有用特殊的颜色(白色)进行填充,这些位置它所对应的像素值为255。在我们训练过程中,在计算损失的时候,会忽略掉这些数字为255的地方,因为针对我们目标边缘它到底属于哪个类别其实也并不好严格去区分。包括有些分割难度较高的区域,我们也可以用这些颜色填充,这样就可以不去管它了(如上图白色矩形区域是飞机的尾翼,利用分割的话其实是很难分割的)。
参考: PASCAL VOC这篇博文,可以看到背景部分填充的是0,在目标边缘填充的都是255。对于目标(person)它填充的是15, pascal voc类别与索引对应关系中,person的索引为15.

3.2 MS COCO数据集
MS COCO数据集中分割的标注格式如下图所示:
- 它提供的是针对图像中的
每个目标记录了多边形的坐标, 比如图像中的人,它的轮廓的多边形形式。以x,y坐标两个一组表示一个点,将这些点全部连起来它就得到了我们的目标了。将图片中的所有目标都给绘制出来,就可以得到右下角对应的分割图片。因此在使用MS COCO数据集的时候,我们需要将坐标形式的标签转换为我们所期望的标签形式,如上图的右下部分。 - 在我们的MS COCO 数据集中,我们所记录的多边形信息,不光用于我们做语义分割,还可以做实例分割等等。因为标签中记录了每个目标的信息,所以我们是可以将每个目标都给区分出来的。
可以参考 MS COCO数据集介绍,这篇博文介绍了如何读取MS COCO的标签文件,转换成我们所期望的标签target样式。
- 读取每张图像的segmentation信息
下面是使用pycocotools读取图像segmentation信息的简单示例:
import os
import random
import numpy as np
from pycocotools.coco import COCO
from pycocotools import mask as coco_mask
from PIL import Image, ImageDraw
import matplotlib.pyplot as plt
random.seed(0)
json_path = "/data/coco2017/annotations/instances_val2017.json"
img_path = "/data/coco2017/val2017"
# random pallette
pallette = [0, 0, 0] + [random.randint(0, 255) for _ in range(255*3)]
# load coco data
coco = COCO(annotation_file=json_path)
# get all image index info
ids = list(sorted(coco.imgs.keys()))
print("number of images: {}".format(len(ids)))
# get all coco class labels
coco_classes = dict([(v["id"], v["name"]) for k, v in coco.cats.items()])
# 遍历前三张图像
for img_id in ids[:3]:
# 获取对应图像id的所有annotations idx信息
ann_ids = coco.getAnnIds(imgIds=img_id)
# 根据annotations idx信息获取所有标注信息
targets = coco.loadAnns(ann_ids)
# get image file name
path = coco.loadImgs(img_id)[0]['file_name']
# read image
img = Image.open(os.path.join(img_path, path)).convert('RGB')
img_w, img_h = img.size
masks = []
cats = []
for target in targets:
cats.append(target["category_id"]) # get object class id
polygons = target["segmentation"] # get object polygons
rles = coco_mask.frPyObjects(polygons, img_h, img_w)
mask = coco_mask.decode(rles)
if len(mask.shape) < 3:
mask = mask[..., None]
mask = mask.any(axis=2)
masks.append(mask)
cats = np.array(cats, dtype=np.int32)
if masks:
masks = np.stack(masks, axis=0)
else:
masks = np.zeros((0, height, width), dtype=np.uint8)
# merge all instance masks into a single segmentation map
# with its corresponding categories
target = (masks * cats[:, None, None]).max(axis=0)
# discard overlapping instances
target[masks.sum(0) > 1] = 255
target = Image.fromarray(target.astype(np.uint8))
target.putpalette(pallette)
plt.imshow(target)
plt.show()
通过pycocotools读取的图像segmentation信息,配合matplotlib库绘制标注图像如下:

4.语义分割结果的具体形式

- 语义分割得到的图片是一张单通道的图片,之所以显示彩色,是因为在单通道的图像上加上了
调色板,所以看到的是一张彩色图片。 - 如上图是pytorch 图像分割的预测结果,对应背景像素值为0,对于飞机的位置像素值是为1的,对于人的位置像素值是为15的。
- 如果不是调色板的模式,看到的分割的结果形式,就是一张黑色图片。因为目标的像素值都很小,根本看不出来区别,所以增加了调色板,将每个像素值对应到彩色颜色中,这样可以方便可视化我们的预测结果。
5.常见的评价指标
常见的语义指标有3个,分别是Pixel Accuracy,mean Accuracy,mean IoU来源于FCN论文
P i x e l A c c u r a c y ( G l o b a l A c c ) = ∑ i n i i ∑ i t i Pixel \quad Accuracy(Global \quad Acc) =\frac{\sum_i n_{ii}}{\sum_i t_i} PixelAccuracy(GlobalAcc)=∑iti∑inii
M e a n A c c u r a c y = 1 n c l s ∑ i n i i ∑ i t i Mean \quad Accuracy = \frac{1}{n_{cls}} \frac{\sum_i n_{ii}}{\sum_i t_i} MeanAccuracy=ncls1∑iti∑inii
M e a n I o U = 1 n c l s ∑ i n i i t i + ∑ j n j i − n i i Mean \quad IoU = \frac{1}{n_{cls}} \sum_i \frac{n_{ii}}{t_i+\sum_j n_{ji}-n_{ii}} MeanIoU=ncls1i∑ti+∑jnji−niinii
其中:
- n i j n_{ij} nij: 类别 i i i被预测成类别 j j j的像素个数
- n c l s n_{cls} ncls: 目标类别个数(包含背景)
- t i = ∑ j n i j t_i = \sum_j n_{ij} ti=∑jnij:目标类别 i i i的总像素个数(真实标签)
指标的说明:
Pixel Accuracy,分子:预测标签中所有预测正确的像素个数总和,分母:实际标签target图像中总像素个数mean Accuracy, 将每个类别的Accuacy计算出来,再求和。然后除以 n c l s n_cls ncls取平均。 n i i n_{ii} nii 类别 i i i被预测正确的总个数, t i t_i ti对应真实标签中目标类别 i i i像素总个数。mean IoU: 计算每个类别的IoU,再求和,然后对所有类别求平均。- 以类别 i i i为例,它的Iou计算,如下图所示
绿色的圆圈对应真实标签,蓝色圆圈对应预测标签。这里 n i i n_{ii} nii就是两个圆重合部分,也就是预测正确部分。 t i t_i ti对应真实标签像素总个数,也就是绿色圆圈的总面积(总像素), ∑ j n j i \sum_j n_{ji} ∑jnji它所对应的就是在我们预测标签中,所有预测为类别 i i i的像素总个数,对应就是蓝色这个圆。由于中间重叠部分 n i i n_{ii} nii计算了两次,所以需要减去 n i i n_{ii} nii

5.1 举例说明
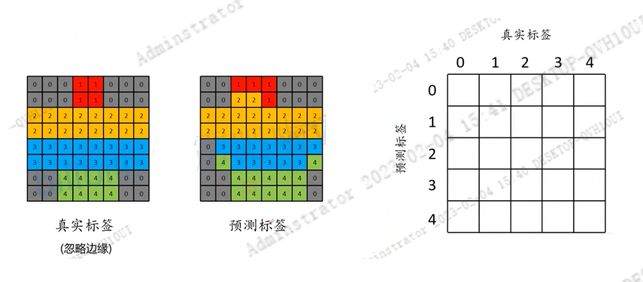
通过构建混淆矩阵来进行计算。假设左边这幅图对应的是真实标签,右边的图对应网络预测的标签。
- 对于类别0而言,这里方便理解。将target所有标签为0的位置设置为白色,非0的位置全部设置为灰色。同样预测标签中所有为0的像素也提取出来,预测正确的位置用绿色进行表示,预测错误的位置用红色进行表示。

可以看出预测标签为0,实际标签也为0的像素个数为16,另外两个预测为0,实际标签为2。 - 同样对于类别1而言,预测标签为1,实际标签也为1的有3个,预测标签为1,真实标签为0的有1个,对应下图所示。

- 最终的混淆矩阵的结果如下图。

global_accuracy: 所有预测正确像素个数/ (图片)总像素个数
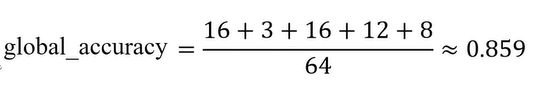
mean accuracy: 各个类别的accuracy之和,除以 总的类别数

对于0而言,预测正确的像素为16,真实标签中类别为0总的像素为20,因此为类别0的accuarcy=16/20;同理,类别对于类别1而言,预测正确的像素为3个,类别1在真实标签中总的像素为4,因此类别1的accuarcu= 3/4,同理其他也一样。
然后将各个类别的accuracy相加,然后狐疑总的类别个数5,就可以计算出mean_accuracy了。
iou: 对于每个类别的iou,分子:该类别预测正确的像素个数,分母:真实标签该类别的总像素个数+ 预测该类别像素个数- 预测正确的像素个数。mean_iou等于各个类别的iou之后,除以所有类别个数。

6 语义分割标注工具
针对分割任务的标注工具有很多,网上搜一搜一大把,你一个个去试,总有一款是你喜欢的。这里简单介绍2款标注工具:Labelme和EISeg
6.1 Labelme
Labelme是一款非常老的标注工具,使用起来非常简单,就是靠你人工一个个点去标,将我们的目标慢慢的框出来。其实这是一种非常传统的标注方式,标注起来也比较费时。参考:Labelme的使用

6.2 EISeg
EIseg是百度提出来的半自动化图像分割标注工具,Github地址:https://github.com/PaddlePaddle/PaddleSeg/tree/release/2.7/EISeg

这个标注工具,基于百度提供的预训练模型,这些模型在一些非常大的数据集上进行训练,它已经包含了我们日常生活中大部分常见的一些目标,使用起来非常简单。
- 比如标注猫,只需要在猫的位置点一下,它就直接将猫给抠出来。不需要一个个点去描,对标注而言确实非常省时省力。
- 对于生活中不常见的目标,如果使用EISeg效果不好的话,可以使用传统的labelme一个点一个点的去标
详细的使用,可参考: EISeg的安装和使用
7. 参考
- https://www.bilibili.com/video/BV1ev411P7dR/
- https://blog.csdn.net/qq_37541097/article/details/120154543