一、贝叶斯网(Bayesian network)
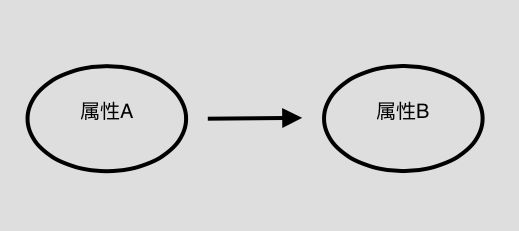
借助有向无环图来刻画属性之间的依赖关系。可以用条件概率表(Conditional Probability Table)来描述属性的联合概率分布。若两个属性有直接的依赖关系,用一条有向边连接。如下,属性B依赖属性A。量化的依赖关系是P(B|A)。
二、结构
有了贝叶斯的网络,我们就可以得到属性x1,x2...xn的联合概率分布。如下图:
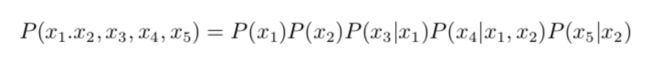
其中,x3和x4在给定了x1的取值时独立,x4和x5在给定x2的时候独立。
贝叶斯网络中有三种典型的依赖关系,可以组成任意的贝叶斯网络。如下图:
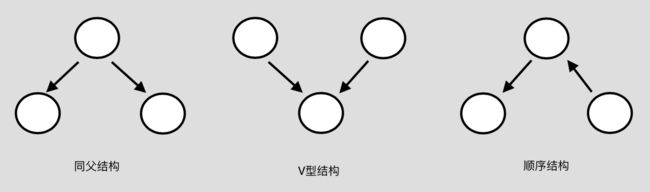
条件独立:条件有时为不独立的事件之间带来独立(gain independence),有时也会把本来独立的事件,因为此条件的存在,而失去独立性(lose independence)
为了分析有向图中变量间的条件独立性,使用“有向分离”把有向图转变为一个无向图。具体步骤如下:
1、找出有向图中的所有V型结构,在V型结构的两个父结点之间加上一条无向边。
2、将所有有向边改为无向边。
这样得到的图称为“道德图(moral graph)”。通过这个图,能迅速地找到变量间的条件独立性。假定道德图中有变量x,y和变量集合z={zi},若变量x和y能在图上被z分开,即从道德图中将变量集合z去除后,x和y分属两个连通分支,则称变量x和y被z有向分离,x和y在给定z的时候条件独立。
三、学习
有了一个贝叶斯网络后,只需通过对训练样本的计数,估计出每个结点的条件概率表即可。但是,现实生活中我们往往不知道一个最好的贝叶斯网络。怎么找出来呢?
“评分搜索”是一个常用的方法。我们通过定义一个评分函数来评估贝叶斯网与训练数据的契合程度。常用的评分函数基于信息论准则。我们将学习问题看作一个数据压缩任务,学习的目标是找到一个能以最短编码长度描述训练数据的模型。这个编码长度包括描述模型自身所需的字节长度和使用该模型描述数据所需的字节长度。
给定训练集D={x1,x2...xm},贝叶斯网B=
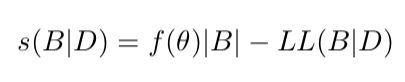
其中,|B|是贝叶斯网的参数个数,f(θ)表示描述每个参数所需的字节数。
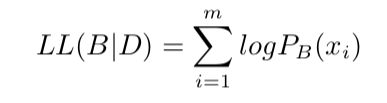
计算B对应的概率分布对D描述的有多好。
这样,就变成了一个最优化的问题。不幸的是,从所有可能的网络结构中搜索最优解是一个NP难问题。有两种策略:贪心法,从某个网络结构出发,每次调整一条边,直到评分数值不会下降为止;另一种是施加约束缩小搜索空间。
四、推断(吉布斯采样)
在我们得到了一个最优的贝叶斯网络后就可以投入使用了。当我们观测到西瓜的属性后就可以推测待查询变量。观测值称为“证据(evidence)”。最理想的是,我们可以直接根据网络关系精确计算后验概率,但是,这种方法被证明是NP难的问题。于是,在较为大型的贝叶斯网络中需要近似推断。在实际生活中,经常采用“吉布斯采样(Gibbs sampling)”
Let's see how it works!
我们有待查询变量:
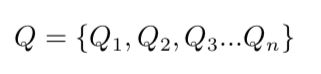
和证据变量:

目标是计算后验概率P=(Q=q|E=e)
吉布斯采样的具体算法是:
1、先随机产生一个与证据E=e一致的样本q0(具体就是固定化证据变量,用随机方法确定查询变量和非证据变量)
2、对非证据变量逐个进行采样。
最开始困扰我的就是什么叫做“采样”?
采样方法就是根据贝叶斯网络和已知变量计算非证据变量的概率。然后通过计算机生成随机数与概率进行比较。如果计算出的概率大于随机数,就改变这个变量。否则停留在原状态。
3、对查询变量进行采样
重复2,3步骤,每一个步骤都是一个样本,到了固定的访问次数后,统计计算查询变量的比例即可。
这种“随机漫步”,每一步仅依赖于前一步的状态,这是一个“马尔可夫链”。在一定条件下,无论从什么初始状态开始,都会在第t步(t->∞)收敛于一个平稳分布。需要注意的是,这种方法通常需要很长时间才能趋于平稳分布,收敛速度较慢。若贝叶斯网络中存在极端概率0或1,则无法保证马尔可夫链存在平稳分布。
五、EM算法
在之前,我们已知假设训练样本的所有属性变量的值都是可以被观测到的,但是在现实生活中往往会遇到无法观测的变量,被称为latent variable--潜在变量。往往较为抽象,比如我们可以知道一个人的grades,但是不能观测到一个人的intelligence。
Θ作为模型参数,我们希望对Θ做极大似然估计,但是现在有两个量都是未知的。EM的基本想法是:若Θ已知,可根据数据推断出最优隐变量Z的值;反之,若Z的值已知,则可方便地对参数Θ做极大似然估计。在之后的文章中可能会更详细解释并给出实例。