基于yolov5的卡片任意倾斜角度较正
序言
因为之前有在做一些规则卡片类的OCR识别任务,就难免会遇到这样的问题:用户上传的照片里卡片的角度是任意的,不规则的,或多或少都会存在不同的倾斜和形变。所以在识别的时候必须要先对其进行矫正再进行检测识别。当时有想到借鉴人脸检测中的关键点回归对卡片的四个角进行回归,但是后来感觉有点麻烦,而且数据有限,如果使用传统的opencv去寻找角点的话实际效果又不太稳定,刚好那段时间v5出来了,突发奇想可以使用v5去做,然后发现效果奇好。
一、数据准备
这里使用银行卡作为示例,其他类型卡片操作一样。首先是使用labelimg对银行卡的四个角度进行标注,将卡片的四个角点当作检测目标,这里需要注意的是,框的标注中心点尽量要对齐角点,因为我们最终要的不是检测框,而是角点的坐标(即检测框的中心点):

标注完后,可以得到voc格式的xml文件,然后就可以用来训练了。
二、v5训练
2.1 准备数据集
首先从github上把yolov5下载下来,解压后将以下makeTxt.py和voc_label.py文件拷贝到文件夹中,训练过yolo的同学应该对这两个文件比较熟悉,makeTxt文件是用来划分训练集和测试集,voc_label文件是用来将voc格式转换为coco格式:
makeTxt.py
import os
import random
trainval_percent = 0.1
train_percent = 0.9
xmlfilepath = 'data/Annotations'
txtsavepath = 'data/ImageSets'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('data/ImageSets/trainval.txt', 'w')
ftest = open('data/ImageSets/test.txt', 'w')
ftrain = open('data/ImageSets/train.txt', 'w')
fval = open('data/ImageSets/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
voc_label.py
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets = ['train', 'test', 'val']
classes = ['point']
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('data/Annotations/%s.xml' % (image_id),encoding='UTF-8')
# print(in_file)
out_file = open('data/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
# print(wd)
for image_set in sets:
if not os.path.exists('data/labels/'):
os.makedirs('data/labels/')
image_ids = open('data/ImageSets/%s.txt' % (image_set)).read().strip().split()
list_file = open('data/%s.txt' % (image_set), 'w')
for image_id in image_ids:
print(image_id)
list_file.write('data/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()
然后将刚才标注的数据拷贝到data文件中,格式如下,Annotations存放xml文件,images存放标注图片,然后新建一个point.yaml文件,定义自己的训练数据集,其他的文件可以暂时不用管,按照步骤来后面会自己慢慢产生:
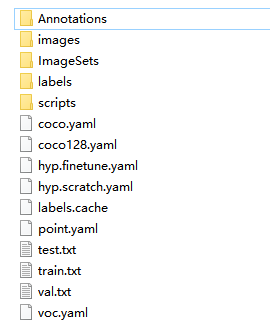
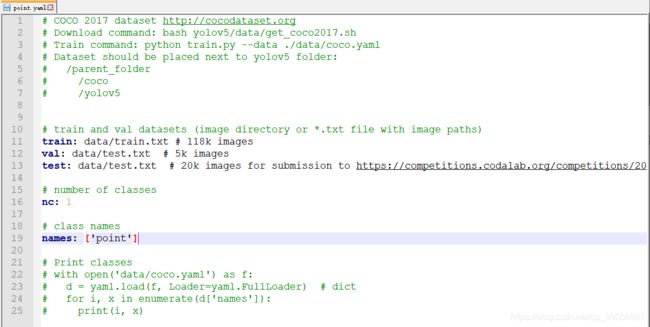
修改模型文件,到mdoels文件夹里,找到yolov5s.yaml,拷贝一份,定义为yolov5s-point.yaml,将里面的nc类别数改为1即可,因为检测任务比较简单,5s模型已经足够了,所以没必要上更大的模型:
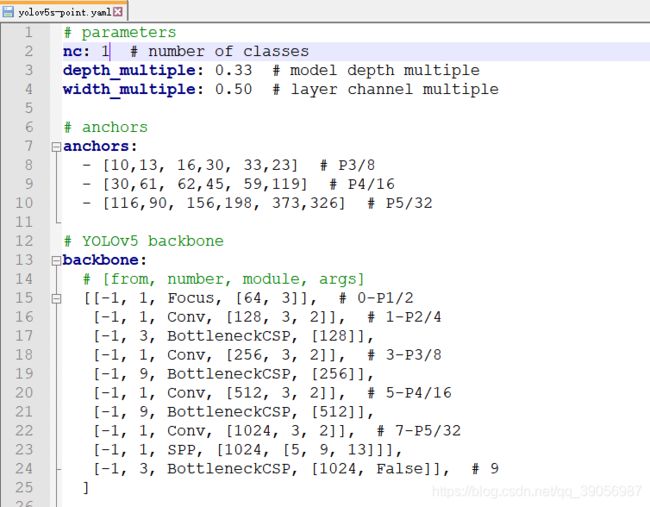
OK,配置修改完成。别忘了把官方的模型文件下载下来,放到weights里,用于预训练加载。
三、开始训练
首先对数据集进行划分,同级目录下打开终端,运行makeTxt.py:
python makeTxt.py
将voc格式转换为coco格式,运行voc_label.py,生成的coco格式文件存放在data/label中:
python voc_label.py
正式训练,批次大小根据自己显卡而定,如果爆cuda的话可以改小一点(windows很容易爆):
python train.py --data point.yaml --img-size 416 --cfg yolov5s-point.yaml --weights weights/yolov5s.pt --batch-size 16 --epochs 100
训练结束后的权重和训练可视化信息可以在runs文件夹中找到:
四、结果可视化
这里我将runs里面的权重拷贝到外面的weights文件中,将待测试的图片拷贝到inference\images中,运行:
python detect.py --weights weights/best.pt --img-size 416

效果还是非常的奈斯。这还只是将角点在原图检测出来,还有后续的操作,需要自己在v5推理后处理那块自己去修改,这里删改的地方太多了,有点乱就不贴上来了。
在后处理阶段,只提取检测框中心点,这才是我们需要的:


得到四个角点的坐标后,就可以用opencv做一个透视变换,得到新纠正后方方正正的图,识别起来就very easy了:
透视变换核心代码如下:
def order_points(pts):
rect = np.zeros((4, 2), dtype = "float32")
# 获取左上角和右下角坐标点
s = pts.sum(axis = 1)
rect[0] = pts[np.argmin(s)]
rect[2] = pts[np.argmax(s)]
# 分别计算左上角和右下角的离散差值
diff = np.diff(pts, axis = 1)
rect[1] = pts[np.argmin(diff)]
rect[3] = pts[np.argmax(diff)]
return rect
def four_point_transform(image, pts):
# 获取坐标点,并将它们分离开来
rect = order_points(pts)
rect = np.array(pts,dtype = "float32")
(tl, tr, br, bl) = rect
# 计算新图片的宽度值,选取水平差值的最大值
widthA = np.sqrt(((br[0] - bl[0]) ** 2) + ((br[1] - bl[1]) ** 2))
widthB = np.sqrt(((tr[0] - tl[0]) ** 2) + ((tr[1] - tl[1]) ** 2))
maxWidth = max(int(widthA), int(widthB))
# 计算新图片的高度值,选取垂直差值的最大值
heightA = np.sqrt(((tr[0] - br[0]) ** 2) + ((tr[1] - br[1]) ** 2))
heightB = np.sqrt(((tl[0] - bl[0]) ** 2) + ((tl[1] - bl[1]) ** 2))
maxHeight = max(int(heightA), int(heightB))
# 构建新图片的4个坐标点
dst = np.array([
[0, 0],
[maxWidth - 1, 0],
[maxWidth - 1, maxHeight - 1],
[0, maxHeight - 1]], dtype = "float32")
M = cv2.getPerspectiveTransform(rect, dst)
warped = cv2.warpPerspective(image, M, (maxWidth, maxHeight))
# 返回变换后的结果
return warped
五、可能会遇到的问题
以上效果都是经过调优后得到的结果,实际串联部署起来有很好的鲁棒性,使用过程中有比较多的优化步骤因为文章篇幅的原因没有全部写出来,这里列出一些实际使用中可能还会存在的问题,需要自己去解决:
- 检测框的置信度不高;
- 误检问题,即如果检测出来4个点以上;漏检问题,检测出来低于4个点;
- 图片大角度(0,90,180,270)分类问题,可以再训练一个很小的分类网络做辅助;
- 如果训练的图片卡片角点也是方方正正的,对形变的卡片检测效果并不太好,需要考虑使用更多的数据增强;
- 其他训练tricks调优。
一些后话:该方法对角点明显的数据纠正效果比较好,也比较通用,当然在服务器资源足够的情况下可以考虑,如果在资源缺乏的设备中,使用v5去做就有点奢侈,可以尝试其他更小的模型去做,如果自己的数据场景没有这么复杂也可以使用传统的opencv的方法去将四个角点找出再做变换,可以很大程度上节省资源,不过稳定性可能会差一些。这个方法思想比较简单,主要还是突发奇想,对yolov5的一个扩展应用,如果有更好的纠正方式可以评论分享,相互学习。