Datawhale组队学习之西瓜书task2
第三章 线性模型
3.0 机器学习三要素
- 模型:根据具体问题,确定假设空间,选定一个模型
- 策略:根据评价标准,确定选取最优模型的策略,确定一个损失函数
- 优化:通过优化算法,求解损失函数,确定最优模型
3.1 基本形式
线性模型(linear model)通过给样本的每个特征不同的权重来进行建模,基本形式如下:
f ( x ) = w 1 x 1 + w 2 x 2 + ⋯ + w d x d + b = w T x + b \begin{aligned} f(\boldsymbol x)&=w_1x_1+w_2x_2+\cdots+w_dx_d+b \\ &=\boldsymbol w^\mathbf T\boldsymbol x+b \end{aligned} f(x)=w1x1+w2x2+⋯+wdxd+b=wTx+b
需要注意的是,对于离散特征,如果存在“序”的关系(即可以进行比较),那么可以将其连续化为连续值,如果不存在“序”的关系,那么就需要转换为k维向量,比如特征“种类”的取值“A”“B”“C”转化为 (1, 0, 0), (0, 1, 0), (0, 0, 1)
接下来我们将通过线性模型来求解回归问题与分类问题
3.2 求解回归问题
3.2.1 一元线性回归
首先考虑只有一个特征的情况,现在我们已经选定了模型,接下来要确定损失函数。
对于回归问题,考虑通过最小化均方误差来确定模型参数,即
E ( w , b ) = ∑ i = 1 m ( y i − w x i − b ) 2 ( w ∗ , b ∗ ) = arg min ( w , b ) E ( w , b ) \begin{aligned} E_{(w,b)}&=\sum_{i=1}^{m}(y_i-wx_i-b)^2\\ (w^*,b^*)&=\underset{(w,b)}{\text{arg\,min}}\,E_{(w,b)} \end{aligned} E(w,b)(w∗,b∗)=i=1∑m(yi−wxi−b)2=(w,b)argminE(w,b)
现在损失函数 E E E已经确定,接下来就要优化它了。
经过证明,此函数为凸函数(可以通过判断黑塞矩阵的正定性进行证明,见3.7.1),对w和b分别令偏导数等于0,可以得到最优解的解析解(闭式解):
w ∗ = ∑ y i ( x i − x ˉ ) ∑ x i 2 − 1 m ( ∑ x i ) 2 b ∗ = 1 m ( ∑ y i − w x i ) \begin{aligned} w^*&=\frac{\sum y_i(x_i-\bar{x})}{\sum x_i^2-\frac{1}{m}\left(\sum x_i\right)^2} \\ b^*&=\frac{1}{m}\left(\sum y_i-wx_i\right) \end{aligned} w∗b∗=∑xi2−m1(∑xi)2∑yi(xi−xˉ)=m1(∑yi−wxi)
这种基于均方误差最小化来进行模型求解的方法称为“最小二乘法”(least square method)
3.2.2 多元线性回归
现在考虑含有d个特征的样本,同样使用最小二乘法进行模型求解。为了便于讨论,令 w ^ = ( w 1 ; w 2 ; ⋯ ; w d ; b ) \hat{\boldsymbol{w}}=(w_1;w_2;\cdots;w_d;b) w^=(w1;w2;⋯;wd;b),令 x i ^ = ( x i 1 ; x i 2 ; ⋯ ; x i d ; 1 ) \hat{\boldsymbol x_i}=(x_{i1};x_{i2};\cdots;x_{id};1) xi^=(xi1;xi2;⋯;xid;1), X = ( x 1 ^ T ; x 2 ^ T ; ⋯ ; x m ^ T ) \mathbf X=(\hat{\boldsymbol x_1}^\mathbf T;\hat{\boldsymbol x_2}^\mathbf T;\cdots;\hat{\boldsymbol x_m}^\mathbf T) X=(x1^T;x2^T;⋯;xm^T),可得
( w ∗ , b ∗ ) = arg min ( w , b ) ∑ i = 1 m ( y i − w T x i − b ) 2 w ^ ∗ = arg min w ^ ∑ i = 1 m ( y i − w ^ T x i ) 2 = arg min w ^ ( y − X w ^ ) T ( y − X w ^ ) \begin{aligned} (\boldsymbol w^*,b^*)&=\underset{(\boldsymbol w,b)}{\text{arg\,min}}\sum_{i=1}^{m}(y_i-\boldsymbol w^\mathbf Tx_i-b)^2 \\ \hat{\boldsymbol{w}}^*&=\underset{\hat{\boldsymbol{w}}}{\text{arg\,min}}\sum_{i=1}^{m}(y_i-\hat{\boldsymbol{w}}^\mathbf{T} x_i)^2 \\ &=\underset{\hat{\boldsymbol{w}}}{\text{arg\,min}}(\boldsymbol y-\mathbf X\hat{\boldsymbol w})^\mathbf T(\boldsymbol y-\mathbf X\hat{\boldsymbol w}) \\ \end{aligned} (w∗,b∗)w^∗=(w,b)argmini=1∑m(yi−wTxi−b)2=w^argmini=1∑m(yi−w^Txi)2=w^argmin(y−Xw^)T(y−Xw^)
令 E w ^ = ( y − X w ^ ) T ( y − X w ^ ) E_{\hat{\boldsymbol{w}}}=(\boldsymbol y-\mathbf X\hat{\boldsymbol w})^\mathbf T(\boldsymbol y-\mathbf X\hat{\boldsymbol w}) Ew^=(y−Xw^)T(y−Xw^),同样可证明此函数为凸函数,因此令 w ^ \hat{\boldsymbol{w}} w^的偏导数为0(向量求导见3.7.2),可得最优解:
∂ E w ^ ∂ w ^ = 2 X T ( X w ^ − y ) = 0 w ^ ∗ = ( X T X ) − 1 X T y \begin{aligned} \frac{\partial E_{\hat{\boldsymbol{w}}}}{\partial \hat{\boldsymbol{w}}}&=2\mathbf{X}^\mathbf T(\mathbf X\hat{\boldsymbol w}-\boldsymbol y)=0 \\ \hat{\boldsymbol{w}}^*&=(\mathbf{X^T X})^{-1}\mathbf{X^T}\boldsymbol y \\ \end{aligned} ∂w^∂Ew^w^∗=2XT(Xw^−y)=0=(XTX)−1XTy
显然,仅当 X T X \mathbf{X^T X} XTX为满秩矩阵时,最优解的解析解才存在,而在现实中大多数时候该矩阵都不是满秩矩阵,常用的办法是引入正则化(regularization)项来调整学习算法的归纳偏好,从而选择最优解。
3.3 求解分类问题
对于分类问题,我们希望模型可以输出的是一个概率值,更极端的,对于二分类任务,我们希望模型只会输出0与1,因此上述会输出实数值的线性模型就不能直接使用了,我们需要改动一下模型。
3.3.1 广义线性模型
考虑单调可微函数 g ( ⋅ ) g(\cdot) g(⋅),令 y = g − 1 ( w T x + b ) y=g^{-1}(\boldsymbol w^\mathbf T\boldsymbol x+b) y=g−1(wTx+b),这样得到的模型即为广义线性模型(generalized linear model),函数 g ( ⋅ ) g(\cdot) g(⋅)被称为联系函数(link function)。
通过联系函数,即便使用线性模型,也可以求取输入空间到输出空间的非线性映射
3.3.2 对数几率回归
根据分类问题的要求,我们找到了一个特殊的联系函数:
y = 1 1 + e − z y=\frac{1}{1+e^{-z}} y=1+e−z1
此函数被称为对数几率函数(logistic function),或者Sigmoid函数,它的函数图像如下:
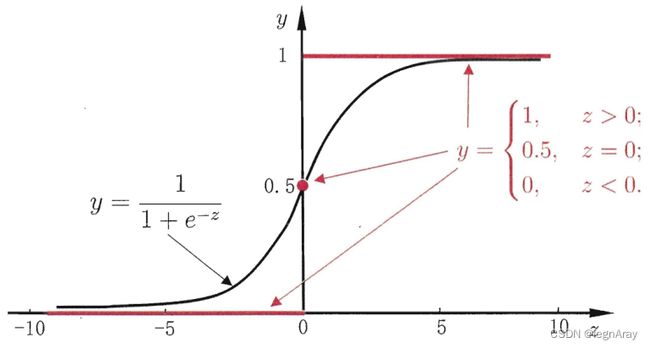
将线性模型带入对数几率函数,再小小的变化一下,得
ln y 1 − y = w T x + b \text{ln}\frac{y}{1-y}=\boldsymbol w^\mathbf T\boldsymbol x+b ln1−yy=wTx+b
ln y 1 − y \text{ln}\frac{y}{1-y} ln1−yy被我们称为对数几率(log odds),因此这种用线性回归去逼近对数几率的模型被称为对数几率回归(logistic regression)
将上式中的 y y y视为概率质量函数 p ( y = 1 ∣ x ) p(y=1|\boldsymbol x) p(y=1∣x),可得
p ( y = 1 ∣ x ) = e w T x + b 1 + e w T x + b p ( y = 0 ∣ x ) = 1 1 + e w T x + b \begin{aligned} p(y=1|\boldsymbol x)&=\frac{e^{\boldsymbol w^\mathbf T\boldsymbol x+b}}{1+e^{\boldsymbol w^\mathbf T\boldsymbol x+b}} \\ p(y=0|\boldsymbol x)&=\frac{1}{1+e^{\boldsymbol w^\mathbf T\boldsymbol x+b}} \\ \end{aligned} p(y=1∣x)p(y=0∣x)=1+ewTx+bewTx+b=1+ewTx+b1
为方便讨论,令 β = ( w ; b ) , x ^ = ( x ; 1 ) , p 1 ( x ^ ; β ) = p ( y = 1 ∣ x ) , p 0 ( x ^ ; β ) = p ( y = 0 ∣ x ) \boldsymbol\beta=(\boldsymbol w;b),\hat{\boldsymbol x}=(\boldsymbol x;1),p_1(\hat{\boldsymbol x};\boldsymbol\beta)=p(y=1|\boldsymbol x),p_0(\hat{\boldsymbol x};\boldsymbol\beta)=p(y=0|\boldsymbol x) β=(w;b),x^=(x;1),p1(x^;β)=p(y=1∣x),p0(x^;β)=p(y=0∣x)
现在可以通过极大似然估计(见3.7.3)或交叉熵(见3.7.4)进行损失函数的求解,这里我选用交叉熵来求解
以单个样本 y i y_i yi来说,理想分布 p ( y i ) p(y_i) p(yi)与模拟分布 q ( y i ) q(y_i) q(yi)分别是:
p ( y i ) = { p ( 1 ) = 1 , p ( 0 ) = 0 if y i = 1 p ( 1 ) = 0 , p ( 0 ) = 1 if y i = 0 q ( y i ) = { p 1 ( x ^ ; β ) if y i = 1 p 0 ( x ^ ; β ) if y i = 0 \begin{aligned} p(y_i)&=\begin{cases}p(1)=1,p(0)=0& \text{ if } y_i=1 \\p(1)=0,p(0)=1& \text{ if } y_i=0 \end{cases}\\ q(y_i)&=\begin{cases}p_1(\hat{\boldsymbol x};\boldsymbol\beta)& \text{ if } y_i=1 \\p_0(\hat{\boldsymbol x};\boldsymbol\beta)& \text{ if } y_i=0 \end{cases}\\ \end{aligned} p(yi)q(yi)={p(1)=1,p(0)=0p(1)=0,p(0)=1 if yi=1 if yi=0={p1(x^;β)p0(x^;β) if yi=1 if yi=0
因此全体训练样本的交叉熵为(令b=e):
E ( β ) = ∑ i = 1 m [ − ∑ y i p ( y i ) ln q ( y i ) ] = ∑ i = 1 m [ − y i ln p 1 ( x i ^ ; β ) − ( 1 − y i ) ln p 0 ( x i ^ ; β ) ] = ∑ i = 1 m ( − y i β T x ^ i + ln ( 1 + e β T x ^ i ) ) β ∗ = arg min β E ( β ) \begin{aligned} E(\boldsymbol\beta)&=\sum_{i=1}^m\left[-\sum_{y_i}p(y_i)\,\text{ln}\,q(y_i)\right] \\ &=\sum_{i=1}^m\left[-y_i\,\text{ln}\,p_1(\hat{\boldsymbol x_i};\boldsymbol\beta)-(1-y_i)\,\text{ln}\,p_0(\hat{\boldsymbol x_i};\boldsymbol\beta)\right] \\ &=\sum_{i=1}^m\left(-y_i\boldsymbol\beta^\mathbf T\hat{\boldsymbol x}_i+\text{ln}(1+e^{\boldsymbol\beta^\mathbf T\hat{\boldsymbol x}_i})\right) \\ \boldsymbol\beta^*&=\underset{\boldsymbol\beta}{\text{arg\,min}}\,E(\boldsymbol\beta) \\ \end{aligned} E(β)β∗=i=1∑m[−yi∑p(yi)lnq(yi)]=i=1∑m[−yilnp1(xi^;β)−(1−yi)lnp0(xi^;β)]=i=1∑m(−yiβTx^i+ln(1+eβTx^i))=βargminE(β)
不同于3.2中的情况, β ∗ \boldsymbol\beta^* β∗没有解析解,因此需要使用一些最优化理论中的优化算法来进行求解,例如梯度下降法(gradient descent method)、牛顿法(Newton method)等,这里不做详细介绍,详情可以参见3.7.5与3.7.6
3.4 线性判别分析
线性判别分析(Linear Discriminant Analysis,LDA)是一种经典的分类方法:给定训练集,将样例投影到d维空间的直线上,使得同类样例的投影点尽可能接近、异类样例的投影点尽可能远离。
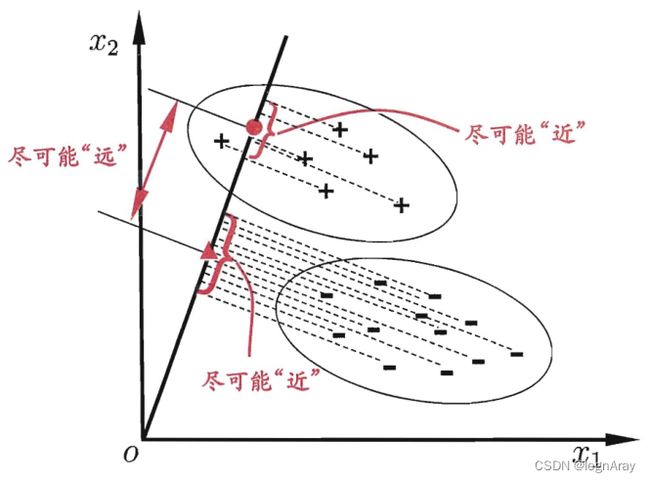
3.4.1 二分类情况
给定数据集 D = { ( x i , y i ) } i = 1 m , y i ∈ { 0 , 1 } D=\{(\boldsymbol x_i,y_i)\}^m_{i=1},y_i\in\{0,1\} D={(xi,yi)}i=1m,yi∈{0,1},其第 i i i类(0或1)的集合、均值向量、协方差矩阵分别为 X i , μ i , Σ i X_i,\boldsymbol\mu_i,\mathbf\Sigma_i Xi,μi,Σi
对于均值向量,根据投影规则,可得两个投影向量为
p 0 = w w T w w T μ 0 p 1 = w w T w w T μ 1 \begin{aligned} \boldsymbol p_0&=\frac{\boldsymbol w}{\boldsymbol w^\mathbf T\boldsymbol w}\boldsymbol w^\mathbf T\boldsymbol\mu_0 \\ \boldsymbol p_1&=\frac{\boldsymbol w}{\boldsymbol w^\mathbf T\boldsymbol w}\boldsymbol w^\mathbf T\boldsymbol\mu_1 \\ \end{aligned} p0p1=wTwwwTμ0=wTwwwTμ1
因此只需要留下 w T μ 0 \boldsymbol w^\mathbf T\boldsymbol\mu_0 wTμ0与 w T μ 1 \boldsymbol w^\mathbf T\boldsymbol\mu_1 wTμ1即可比较投影长度
而对于协方差矩阵,其投影的结果为 w T Σ 0 w \boldsymbol w^\mathbf T\mathbf\Sigma_0\boldsymbol w wTΣ0w与 w T Σ 1 w \boldsymbol w^\mathbf T\mathbf\Sigma_1\boldsymbol w wTΣ1w
定义类内散度矩阵 S w = Σ 0 + Σ 1 \mathbf S_w=\mathbf\Sigma_0+\mathbf\Sigma_1 Sw=Σ0+Σ1,类间散度矩阵 S b = ( μ 0 − μ 1 ) ( μ 0 − μ 1 ) T \mathbf S_b=(\boldsymbol\mu_0-\boldsymbol\mu_1)(\boldsymbol\mu_0-\boldsymbol\mu_1)^\mathbf T Sb=(μ0−μ1)(μ0−μ1)T,则LDA最大化的目标
J = ∥ w T μ 0 − w T μ 1 ∥ 2 2 w T Σ 0 w + w T Σ 1 w = w T S b w w T S w w \begin{aligned} J&=\frac{\left\|\boldsymbol w^\mathbf T\boldsymbol\mu_0-\boldsymbol w^\mathbf T\boldsymbol\mu_1\right\|_2^2}{\boldsymbol w^\mathbf T\mathbf\Sigma_0\boldsymbol w+\boldsymbol w^\mathbf T\mathbf\Sigma_1\boldsymbol w} \\ &=\frac{\boldsymbol w^\mathbf T\mathbf S_b\boldsymbol w}{\boldsymbol w^\mathbf T\mathbf S_w\boldsymbol w} \end{aligned} J=wTΣ0w+wTΣ1w wTμ0−wTμ1 22=wTSwwwTSbw
显而易见, J J J同时也是 S b S_b Sb对 S w S_w Sw的广义瑞利商(generalized Rayleigh quotient),其最大值可以通过最大的广义特征值确定
因为此式的解与 w \boldsymbol w w的长度无关,所以我们令 w T S w w = 1 \boldsymbol w^\mathbf T\mathbf S_w\boldsymbol w=1 wTSww=1(仅仅是好算而已,固定哪边都行),再通过拉格朗日乘子法(见3.7.7),可以得到 S b w = λ S w w \mathbf S_b\boldsymbol w=\lambda S_w\boldsymbol w Sbw=λSww(这也是广义特征值的表达式)
最终解得 w = S w − 1 ( μ 0 − μ 1 ) \boldsymbol w=\mathbf S_w^{-1}(\boldsymbol\mu_0-\boldsymbol\mu_1) w=Sw−1(μ0−μ1)
再次提醒,我们仅仅关注 w \boldsymbol w w的方向,而不关注它的大小
3.4.2 多分类情况
LDA多分类时的情况类似二分类,详细过程参见西瓜书,但归根结底还是求解 S b S_b Sb对 S w S_w Sw的广义特征值(非零),从而得到对应的特征向量
3.5 基于二分类的多分类
大多数时候,我们可以通过拆解法从而基于二分类学习器解决多分类问题
- 一对一(OvO):将N个类别两两配对,产生 N ( N − 1 ) / 2 N(N-1)/2 N(N−1)/2个二分类任务,最终的结果通过每个二分类器投票产生
- 一对其余(OvR):将一个类别作为正例,将其他类别作为反例来训练N个分类器,最终结果由置信度最大的一个分类器决定
- 多对多(MvM):常用纠错输出码方法(ECOC),训练时编码,对N个类别进行M次划分,训练M个二分类器。测试时解码,使用M个分类器对其预测,将生成的编码与每个类别的编码比较,距离最小的即为预测结果
3.6 类别不平衡问题
对于训练样例中正反例数目不同的情况,可以通过以下三种方式处理
- 欠采样(undersampling):也称下采样,去除一些比例高的数据
- 过采样(oversampling):也称上采样,通过插值增加一些比例少的数据
- 阈值移动(threshold-moving):用原始训练集训练,但在预测时令 y ′ 1 − y ′ = y 1 − y × 反例数量 正例数量 \frac{y'}{1-y'}=\frac{y}{1-y}\times\frac{反例数量}{正例数量} 1−y′y′=1−yy×正例数量反例数量
3.7 补充知识
部分请点击链接查看原文…
3.7.1 凸集、凸函数与极值
3.7.2 矩阵求导
3.7.3 极大似然估计
3.7.4 交叉熵
自信息(self-information):表示一个随机事件所包含的信息量,一个随机事件发生的概率越高,其自信息越低。
I ( X ) = − log b p ( x ) I(X)=-\text{log}_b\,p(x) I(X)=−logbp(x)
信息熵(entropy):即自信息的期望,用来度量随机变量X的不确定性,信息熵越大越不确定
H ( X ) = E [ I ( X ) ] = − ∑ x p ( x ) log b p ( x ) H(X)=E[I(X)]=-\sum_xp(x)\text{log}_b\,p(x) H(X)=E[I(X)]=−x∑p(x)logbp(x)
相对熵(relative entropy):又称KL散度、信息散度,用来度量两个分布之间的差异,在机器学习中大多数情况是一个概率分布为真实分布,另一个为理论(拟合)分布
KL ( p ∣ ∣ q ) = ∑ x p ( x ) log b p ( x ) q ( x ) = ∑ x p ( x ) log b p ( x ) − ∑ x p ( x ) log b q ( x ) \begin{aligned} \text{KL}(p||q)&=\sum_xp(x)\text{log}_b\frac{p(x)}{q(x)} \\ &=\sum_xp(x)\text{log}_b\,p(x)-\sum_xp(x)\text{log}_b\,q(x) \\ \end{aligned} KL(p∣∣q)=x∑p(x)logbq(x)p(x)=x∑p(x)logbp(x)−x∑p(x)logbq(x)
我们把 − ∑ x p ( x ) log b q ( x ) -\sum_xp(x)\text{log}_b\,q(x) −∑xp(x)logbq(x)这一项称为交叉熵(cross-entropy),因为p分布是真实分布,那么它的信息熵是固定的,因此当我们想要最小化KL散度时,只需要最小化交叉熵即可。
3.7.5 梯度下降法
3.7.6 牛顿法
3.7.7 拉格朗日乘子法
对于仅含等式约束的优化问题
min x f ( x ) s.t. h i ( x ) = 0 i = 1 , 2 , ⋯ , n \begin{aligned} \underset{\boldsymbol x}{\text{min}}\quad &f(\boldsymbol x) \\ \text{s.t.}\quad &h_i(\boldsymbol x)=0\quad i=1,2,\cdots,n \\ \end{aligned} xmins.t.f(x)hi(x)=0i=1,2,⋯,n
若其中 f ( x ) f(\boldsymbol x) f(x)和 h i ( x ) h_i(\boldsymbol x) hi(x)均有连续的一阶偏导数,则可列出拉格朗日函数:
L ( x , λ ) = f ( x ) + ∑ i = 1 n λ i h i ( x ) L(\boldsymbol x,\boldsymbol\lambda)=f(\boldsymbol x)+\sum_{i=1}^n\lambda_ih_i(\boldsymbol x) L(x,λ)=f(x)+i=1∑nλihi(x)
对拉格朗日函数关于 x \boldsymbol x x求偏导,令偏导数等于零,再结合约束条件即可解出 x \boldsymbol x x, x \boldsymbol x x中包含所有可能的极值点,后续再做分析即可
参考资料
周志华:《机器学习》
维基百科
Datawhale:【吃瓜教程】《机器学习公式详解》(南瓜书)与西瓜书公式推导直播合集
BigYouYou:凸函数定义与判定条件 凸优化方法总论
legnAray:矩阵的迹与导数