8种视觉Transformer整理(下)
一、Focal Transformer
原文链接:https://arxiv.org/pdf/2107.00641.pdf
网络结构
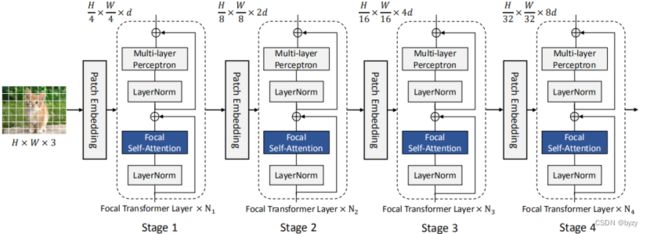
首先将图片分成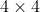 的patch。然后进入Patch Embedding层(卷积核和步长都为4的卷积层),输入到Focal Transformer层。在每个stage中,特征的大小减半,通道维度变为原来的两倍。
的patch。然后进入Patch Embedding层(卷积核和步长都为4的卷积层),输入到Focal Transformer层。在每个stage中,特征的大小减半,通道维度变为原来的两倍。
Focal自注意力(FSA)
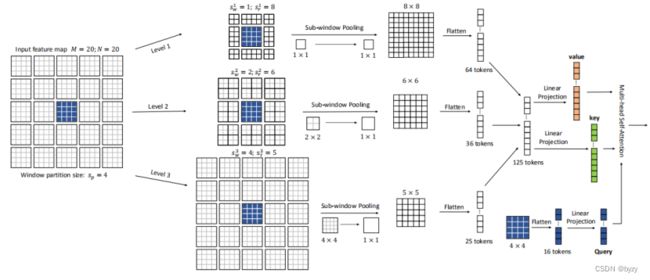
传统的SA由于对所有的token都进行细粒度的关注,因此非常费时;本文提出的FSA对靠近当前token的信息进行更加细粒度的关注,对远离当前token的信息进行粗粒度的关注。
分为多个level,每个level有两个参数,子窗口大小![]() 和横纵数量
和横纵数量![]() (
(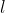 为level序号)。
为level序号)。
子窗口池化:对每一个level的feature map,每一个子窗口通过线性层池化得到一个值。然后拉长为向量,不同level的向量拼接,用线性层分别生成 和
和 ;用原始窗口的特征拉长通过线性层生成
;用原始窗口的特征拉长通过线性层生成 。
。
注意力计算: 为可学习的相对位置偏置(和下面Swin Transformer的类似)
为可学习的相对位置偏置(和下面Swin Transformer的类似)
![]()
二、Swin Transformer
原文链接:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows | IEEE Conference Publication | IEEE Xplore
网络结构
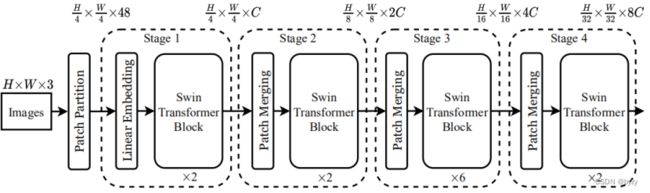
将图像分为 的patch,通过linear embedding将特征维度变为
的patch,通过linear embedding将特征维度变为 ,送入Swin-T块。此后每一个stage开始有一个patch merging,将
,送入Swin-T块。此后每一个stage开始有一个patch merging,将 的patch合并为1个,再把特征维度乘以2。
的patch合并为1个,再把特征维度乘以2。
Swin-T块
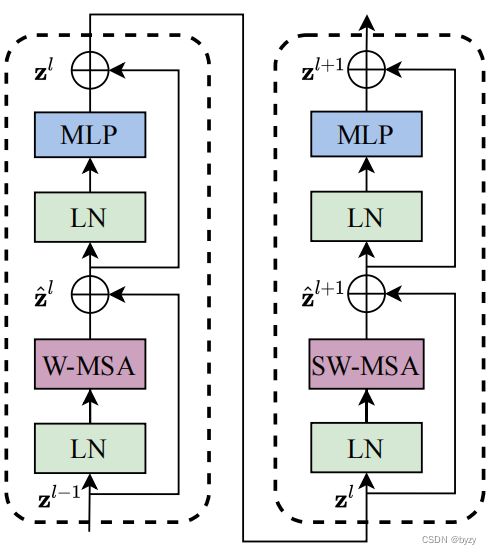 其中MLP为2层,激活函数为GELU
其中MLP为2层,激活函数为GELU
将输入图片划分成不重合的窗口,每个窗口包含![]() 的patch,在每个窗口内部计算自注意力。但由于未考虑窗口间的关系,因此引入shifted window。
的patch,在每个窗口内部计算自注意力。但由于未考虑窗口间的关系,因此引入shifted window。
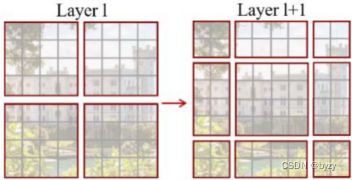
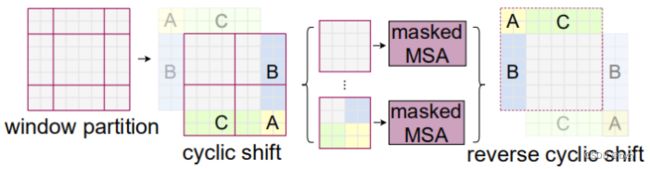
对于连续两个Swin-T块,第二个采用shifted window:
![]()
--相对位置偏置,文章未介绍计算方法,具体可能要看代码(可参考图解swin transformer - 腾讯云开发者社区-腾讯云的讲解)。
三、ResT
原文链接:https://arxiv.org/pdf/2105.13677.pdf
网络结构
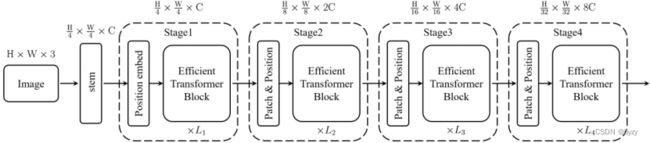
stage组成:patch embedding模块+位置编码+![]() efficient Transformer块。efficient Transformer块中的多头自注意力称为EMSA。
efficient Transformer块。efficient Transformer块中的多头自注意力称为EMSA。
EMSA
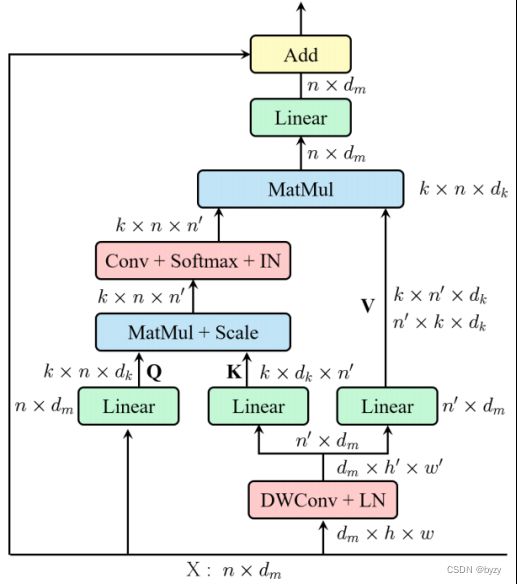 EMSA结构
EMSA结构
 通过depth-wise卷积(核大小,步长和padding分别为
通过depth-wise卷积(核大小,步长和padding分别为![]() ,
, ,
,![]() ,这里
,这里![]() ,
, 为head数量),然后通过线性层生成和。按照下式计算:
为head数量),然后通过线性层生成和。按照下式计算:
![]()
这里Conv为1*1卷积,IN为Instance Normalization。
最后拼接所有head的输出,通过线性层。
剩下的部分和常规Transformer一致,即
![]()
![]()
Stem
使用3个 卷积层(步长分别为2,1,2,padding为1,中间包含BN和ReLU)将尺寸缩小到1/4。
卷积层(步长分别为2,1,2,padding为1,中间包含BN和ReLU)将尺寸缩小到1/4。
Patch embedding
减少输入token的分辨率并且增加通道数。使用卷积(步长2,padding 1)将尺寸缩小1半,通道数提高1倍。
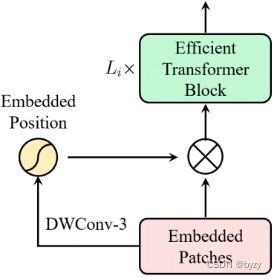
位置编码
使用pixel-wise attention来编码位置,即使用的depth-wise卷积,再通过sigmoid函数。如下图所示。
![]()
四、VOLO
原文链接:https://arxiv.org/pdf/2106.13112.pdf
开始先把图像分割为![]() 的patch。
的patch。
分为两个stage,第一个stage由outlooker组成,生成细粒度特征,第二个stage用Transformer聚合全局信息。每个stage开始时有一个patch embedding生成token。
Outlooker
outlook attention layer(空间)+ MLP(通道)
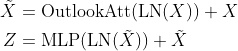
Outlook Attention
 图中Unfold为V取邻域后沿空间拉直为向量,Fold为不同窗口同一位置相加
图中Unfold为V取邻域后沿空间拉直为向量,Fold为不同窗口同一位置相加
Outlook attention计算每个空间位置 和其
和其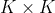 邻域内点的相似度。
邻域内点的相似度。
使用两个线性层分别得到 和,然后把做reshape。
和,然后把做reshape。
即:给定输入
和
)得到
和
。令
表示中心为
将
。则输出
然后将不同窗口中同一位置的输出加起来(Fold操作)。
![]()
最后输出通过线性层。
多头Outlook Attention
设有 个头。将的形状增长倍后平均分为份(即此时
个头。将的形状增长倍后平均分为份(即此时![]() ,得到的划分为份,
,得到的划分为份,![]() )。按照维度平均分成份(
)。按照维度平均分成份(![]() 且
且![]() )。最后对每一对
)。最后对每一对![]() ,
,![]() 分别进行Outlook Attention后拼接。
分别进行Outlook Attention后拼接。