[机器学习与scikit-learn-19]:算法-逻辑回归-概述与原理
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/123438808
目录
第1章 逻辑回归的应用场景
第2章 逻辑回顾在机器学习中的位置
第3章 逻辑回归与线性回归区分
第4章 什么逻辑回归
4.1 概述
4.2 链接函数与Sigmod
第5章 逻辑回顾的数学表达
第6章 sigmod函数的本质是概率吗
第7章 为什么需要逻辑回归:逻辑回归的优势
第8本章 逻辑回归分类
8.1 线性回归
8.2 非线性回归
第1章 逻辑回归的应用场景
在银行借贷场景中,评分卡是一种以分数形式来衡量一个客户的信用风险大小的手段,它衡量向别人借钱的人(受信人,需要融资的公司)不能如期履行合同中的还本付息责任,并让借钱给别人的人(授信人,银行等金融机构)造成经济损失的可能性。
一般来说,评分卡打出的分数越高,客户的信用越好,风险越小。
这些”借钱的人“,可能是个人,有可能是有需求的公司和企业。对于企业来说,我们按照融资主体的融资用途,分别使用企业融资模型,现金流融资模型,项目融资模型等模型。而对于个人来说,我们有”四张卡“来评判个人的信用程度:A卡,B卡,C卡和F卡。
而众人常说的“评分卡”其实是指A卡,又称为申请者评级模型,主要应用于相关融资类业务中新用户的主体评级,即判断金融机构是否应该借钱给一个新用户,如果这个人的风险太高,我们可以拒绝贷款。
备注:
打分是连续的,这个过程是线性拟合、线性回归。
根据打分后的信用评分,先通过线性拟合的手段获得分数,再根据分数进行分类,打分和分类在同一个模型中一次性完成,这就是逻辑回归。
“逻辑” =》 分类
“回归” =》 拟合
第2章 逻辑回顾在机器学习中的位置
![[机器学习与scikit-learn-19]:算法-逻辑回归-概述与原理_第1张图片](http://img.e-com-net.com/image/info8/5bcf884133a54b01ada61a1c0c545dea.jpg)
逻辑回归的目标是分类
逻辑回归的手段是回归
第3章 逻辑回归与线性回归区分
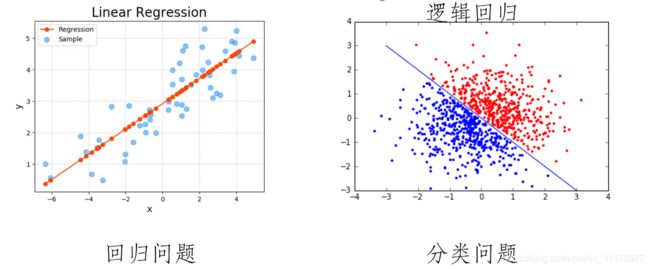
线性拟合回归:用线性的曲线去拟合样本内在的走势。
线性逻辑回归:用线性的曲线去分割样本的类别。
![[机器学习与scikit-learn-19]:算法-逻辑回归-概述与原理_第2张图片](http://img.e-com-net.com/image/info8/7831850964254dbfb15f6f92bf8a11aa.jpg)
![[机器学习与scikit-learn-19]:算法-逻辑回归-概述与原理_第3张图片](http://img.e-com-net.com/image/info8/bd5072589c6b431aa4b9b16c3de6af6a.jpg)
第4章 什么逻辑回归
4.1 概述
逻辑回归,是一种名为“回归”的线性分类器,其本质是由线性回归变化而来的,一种广泛使用于分类问题中的广义回归算法。
要理解逻辑回归从何而来,得要先理解线性回归。
线性回归是机器学习中最简单的的回归算法,它写作一个几乎人人熟悉的方程:
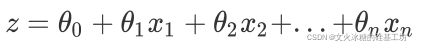
![[机器学习与scikit-learn-19]:算法-逻辑回归-概述与原理_第4张图片](http://img.e-com-net.com/image/info8/7b055a349bfa49e595311343c17eafd4.jpg)
线性回归的任务,就是构造一个预测函数 来映射输入的特征矩阵x和标签值y的线性关系,而构造预测函数的核心就是找出模型的参数:![]() ,著名的最小二乘法就是用来求解线性回归中参数的数学方法。
,著名的最小二乘法就是用来求解线性回归中参数的数学方法。
通过函数 ,线性回归使用输入的特征矩阵X来输出一组连续型的标签值y_pred,以完成各种预测连续型变量的任务(比如预测产品销量,预测股价等等)。
![[机器学习与scikit-learn-19]:算法-逻辑回归-概述与原理_第5张图片](http://img.e-com-net.com/image/info8/f217a859fa67421aa2940c0b64079c15.jpg)
那如果我们的标签是离散型变量,尤其是,如果是满足0-1分布的离散型变量,我们要怎么办呢?
![[机器学习与scikit-learn-19]:算法-逻辑回归-概述与原理_第6张图片](http://img.e-com-net.com/image/info8/d38d22e9c76d4ec4aaf11ed8a35d888a.jpg)
4.2 链接函数与Sigmod
我们可以通过引入链接函数(link function),将线性回归方程z变换为g(z),并且令g(z)的值分布在(0,1)之间,且当g(z)接近0时样本的标签为类别0,当g(z)接近1时样本的标签为类别1,这样就得到了一个分类模型。
逻辑回归的本质是用函数拟合拟合的手段解决分类问题,这在深度学习中得到了极大的体现。
深度学习就是利用大量的线性神经元来拟合复杂的现实世界,并结合非线性的激活函数,把他们组合在一起共同完成分类和拟合。
因此,把回归转换为分类问题的过程中,链接函数起着及其关键的作用。
而这个链接函数对于逻辑回归来说,就是Sigmoid函数:
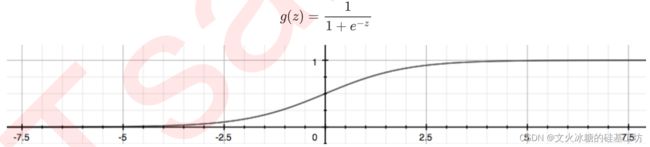
Sigmoid函数是一个S型的函数:
当自变量z趋近正无穷时,因变量g(z)趋近于1,而当z趋近负无穷时,g(z)趋近于0,它能够将任何实数映射到(0,1)区间,使其可用于将任意值函数转换为更适合二分类的函数。
因为这个性质,Sigmoid函数也被当作是归一化的一种方法,与我们之前学过的MinMaxSclaer同理,是属于数据预处理中的“缩放”功能,可以将数据压缩到[0,1]之内。区别在于,MinMaxScaler归一化之后,是可以取到0和1的(最大值归一化后就是1,最小值归一化后就是0),但Sigmoid函数只是无限趋近于0和1。
Sigmoid函数在逻辑回归和打分中的重要意义:
![[机器学习与scikit-learn-19]:算法-逻辑回归-概述与原理_第7张图片](http://img.e-com-net.com/image/info8/83be8e341c804304bba975ba25477aeb.jpg)
(1)把分类1对应的线性拟合出来的所有正数距离值值转换为[0.5, 1) 区间,转为为所谓的[0.5, 1) 的概率值。这样分类化,分类1的标签就是1.
(2)把分类1对应的线性拟合出来的所有正数距离值值转换为[0, 0.5) 区间,转为为所谓的(0, 0.5] 的概率值。这样分类化,分类2的标签就是0.
(3)转换后,就是要找到一个线性直线,使得标签1中所有点到直线的距离d1到分类1的标签值:“1”的距离之和,再加上标签2中所有点到直线的距离d2到分类2的标签值:0的距离之和的loss值最小。如下图示意:
![[机器学习与scikit-learn-19]:算法-逻辑回归-概述与原理_第8张图片](http://img.e-com-net.com/image/info8/e849559076fb4227840c50fc06d0381c.png)
第5章 逻辑回顾的数学表达
![[机器学习与scikit-learn-19]:算法-逻辑回归-概述与原理_第9张图片](http://img.e-com-net.com/image/info8/6f696d74a7804605b22c753b604728b9.jpg)
![[机器学习与scikit-learn-19]:算法-逻辑回归-概述与原理_第10张图片](http://img.e-com-net.com/image/info8/2de2e142854d4746bc4141dbff0bdfbb.jpg)
不难发现,y(x)的形似几率取对数的本质其实就是我们的线性回归z,我们实际上是在对线性回归模型的预测结果取对数几率来让其的结果无限逼近0和1。因此,其对应的模型被称为”对数几率回归“(logistic Regression),也就是我们的逻辑回归,这个名为“回归”却是用来做分类工作的分类器。之前我们提到过,线性回归的核心任务是通过求解 构建 这个预测函数,并希望预测函数 能够尽量拟合数据,因此逻辑回归的核心任务也是类似的:求解 来构建一个能够尽量拟合数据的预测函数 ,并通过向预测函数中输入特征矩阵来获取相应的标签值y。
第6章 sigmod函数的本质是概率吗
经过sigmod函数转换后,距离d被转换成了[0,1] 之间的数值,当给定一个样本,算出其到拟合曲线的距离自然就是[0,1]之间,转换后的特性与概率的特性及其相似,这样就可以利用现成的概率相关的函数用来进行数学计算,因此,大多时候,直接借用概率的概率来阐述了。
但本质上,并非是真正意义上的概率!!!!这一点需要清醒的认知。
![[机器学习与scikit-learn-19]:算法-逻辑回归-概述与原理_第11张图片](http://img.e-com-net.com/image/info8/f122efab213b440f9eb1831b231c4c5a.jpg)
第7章 为什么需要逻辑回归:逻辑回归的优势
有了用于拟合的回归,有了专门用于分类的模型,为啥还需要逻辑回归这一种模型呢?
它相对于普通的分类(如决策树分类),有什么优势与特点呢?
线性回归:对数据的要求很严格,比如标签必须满足正态分布,特征之间的多重共线性需要消除等等,而现实中很多真实情景的数据无法满足这些要求,因此线性回归在很多现实情境的应用效果有限。逻辑回归是由线性回归变化而来,因此它对数据也有一些要求,而我们之前已经学过了强大的分类模型决策树和随机森林,它们的分类效力很强,并且不需要对数据做任何预处理。
何况,逻辑回归的原理其实并不简单。一个人要理解逻辑回归,必须要有一定的数学基础,必须理解损失函数,正则化,梯度下降,海森矩阵等等这些复杂的概念,才能够对逻辑回归进行调优。其涉及到的数学理念,不比支持向量机少多少。况且,要计算概率,朴素贝叶斯可以计算出真正意义上的概率,要进行分类,机器学习中能够完成二分类功能的模型简直多如牛毛。因此,在数据挖掘,人工智能所涉及到的医疗,教育,人脸识别,语音识别这些领域,逻辑回归没有太多的出场机会。甚至,在我们的各种机器学习经典书目中,周志华的《机器学习》400页仅有一页纸是关于逻辑回归的(还是一页数学公式),《数据挖掘导论》和《Python数据科学手册》中完全没有逻辑回归相关的内容,sklearn中对比各种分类器的效应也不带逻辑回归玩,可见业界地位。
但是,无论机器学习领域如何折腾,逻辑回归依然是一个受工业商业热爱,使用广泛的模型,因为它有着不可替代的优点:
(1)逻辑回归对线性分类关系的拟合效果好到丧心病狂
特征与标签之间的线性关系极强的数据,比如金融领域中的信用卡欺诈,评分卡制作,电商中的营销预测等等相关的数据,都是逻辑回归的强项。
虽然现在有了梯度提升树GDBT,比逻辑回归效果更好,也被许多数据咨询公司启用,但逻辑回归在金融领域,尤其是银行业中的统治地位依然不可动摇(相对的,逻辑回归在非线性数据的效果很多时候比瞎猜还不如,所以如果你已经知道数据之间的联系是非线性的,千万不要迷信逻辑回归)
(2)逻辑回归计算快:
对于线性数据,逻辑回归的拟合和计算都非常快,计算效率优于SVM和随机森林,亲测表示在大型数据上尤其能够看得出区别。
(3)逻辑回归返回的分类结果不是固定的0,1,而是以小数形式呈现的类概率数字
在有些分类中,返回的结果是0或1的数值,没有中介结果。而逻辑回归输出的是[0,1]的小数
我们因此可以把逻辑回归返回的结果当成连续型数据来利用。比如在评分卡制作时,我们不仅需要判断客户是否会违约,还需要给出确定的”信用分“,而这个信用分的计算就需要使用类概率计算出的对数几率,而决策树和随机森林这样的分类器,可以产出分类结果,却无法帮助我们计算分数(当然,在sklearn中,决策树也可以产生概率,使用接口predict_proba调用就好,但一般来说,正常的决策树没有这个功能)。
即我们不仅仅需要知道信用的等级或好坏,我们还需要知道好的什么程度,坏到什么程度。如10%, 20%,30%, 40%,50%,60%,70%,80%,90%,100%,如果是而分类,只有0和1,分界点可能是50%。
(4)逻辑回归的灵活性
然而,60%和90%都归为1,但他们程度是不同的。我们还需要对他们进行进一步的划分,如划分为等级A, B, C, D.....等等,这就给逻辑回归的输出 结果的使用带来了极大灵活性,我们可以利用输出,完成二分类,也可以用输出结果大多多分类的效果。
(5)另外,逻辑回归还有抗噪能力强的优点。
福布斯杂志在讨论逻辑回归的优点时,甚至有着“技术上来说,最佳模型的AUC面积低于0.8时,逻辑回归非常明显优于树模型”的说法。并且,逻辑回归在小数据集上表现更好,在大型的数据集上,树模型有着更好的表现。由此,我们已经了解了逻辑回归的本质,它是一个返回对数几率的,在线性数据上表现优异的分类器,它主要被应用在金融领域。其数学目的是求解能够让模型对数据拟合程度最高的参数 的值,以此构建预测函数 ,然后将特征矩阵输入预测函数来计算出逻辑回归的结果y。注意,虽然我们熟悉的逻辑回归通常被用于处理二分类问题,但逻辑回归也可以做多分类。
第8本章 逻辑回归分类
根据拟合函数的类型,分为
8.1 线性回归
线性回归就利用多个线性直线函数叠加作为拟合函数。
![[机器学习与scikit-learn-19]:算法-逻辑回归-概述与原理_第12张图片](http://img.e-com-net.com/image/info8/ce47d4bbaa8f45faa1c8b5ef6aa50484.jpg)
8.2 非线性回归
(1)概述
![[机器学习与scikit-learn-19]:算法-逻辑回归-概述与原理_第13张图片](http://img.e-com-net.com/image/info8/2aabcada6c3d47d3a3a438d92e4baa3e.jpg)
非线性回归就利用多个非线性函数的叠加作为拟合函数:
(2)常见的非线性函数就是多项式函数:
多项式函数,是数学概念。形如f(x)=an·x^n+an-1·x^(n-1)+…+a2·x^2+a1·x+a0的函数,叫做多项式函数,它是由常数与自变量x经过有限次乘法与加法运算得到的。显然,当n=1时,其为一次函数y=kx+b,当n=2时,其为二次函数。
![[机器学习与scikit-learn-19]:算法-逻辑回归-概述与原理_第14张图片](http://img.e-com-net.com/image/info8/d97ae8bbf05a4bfeb750ca3e89e747fc.jpg)
(3)多项式可以处理非常复杂的分类问题:
![[机器学习与scikit-learn-19]:算法-逻辑回归-概述与原理_第15张图片](http://img.e-com-net.com/image/info8/41217d93825b42c98cd31665dcb9534e.jpg)
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址: