【论文笔记】ECCV 2018 || Videos as Space-Time Region Graphs
论文获取地址: https://arxiv.org/abs/1806.01810 (ECCV 2018)
作者: Xiaolong Wang, Abhinav Gupta (CMU)

之所以看到该论文,是在前不久收听中科院B站上的录播内容,就是胡瀚研究员介绍自己的swin transformer的工作时指出这篇论文也很早的尝试了对相对关系建模的实现。可以发现现今计算机视觉邻域大火的transformer的本质也就是这个相对关系的建模。
一、论文概述
1、问题的提出
通过对人与物体的交互动作的分析出:人与物体之间的时序外观动态建模(temporal shape dynamics) 与功能关系建模( functional relationships )对辨别此类动作具有重要意义。
2、创新点与方法
本文提出将视频表示为捕捉上述两条重要线索的时空区域图。
其图结点是由长视频序列中不同时序帧的 对象区域候选框(由目标检测任务完成),这些结点之间通过两种关系连接:
(1)捕捉相关对象之间的远程依赖关系的相似性关系;
(2)捕捉邻近对象之间交互的时空关系。
并且通过图卷积网络对这种图表示进行推理。
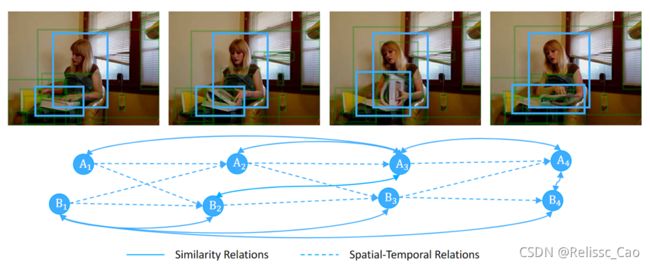
3、小结
在这里,具体的说作者分为了两种图的种类:相似图与时空图:
1)相似图(视觉空间相似与函数空间相似(对象与对象之间的关系):该构建图中将外观相似或语义相关的区域连接在一起。通过该相似图关系。可以模拟同一对象的状态如何变化(不包含时序顺序)以及任意帧中任意两个对象之间的长期依赖关系(不涉及到时序顺序)。该图的重点就是任意两个对象之间的长期依赖;
2)时空图(相对空间关系与(状态变化的顺序)时序关系):将空间重叠、时间相近的对象相互连接,利用该时空关系,可以捕获附近物体之间的相互作用,以及物体状态随时间变化的顺序。该图的重点就是相对空间关系和状态变化时序关系。
总结:这两个图之间的表示也是有重叠部分的,但是重点不一样。比如若是一个物体随时间相对位置和状态变化不大,那么在两个图中其边的连接权重都很大。
二、全局网络

由上图可以看到。首先该网络中有两个流(可以理解为提取出特征后分的流):
先从第一个流说起,对于一个长视频序列,作者以同等时间间隔采样出32帧得到I3D网络的输入,I3D进行特征提取后得到最终的输出特征图尺寸为T*H*W*d;然后进行T*H*W三维的全局平均池化保留d维作为与另一流融合前的特征。该流提取的是原视频特征;
然后便是作者的主要创新点的网络流。该流输入为从上述I3D网络的输入的32帧中在采样为16帧(每两帧采样一帧)用以输入RPN(目标检测子网络)中生成边界框,并将边界框投影(对应)到输出特征中。得到边界框后在每个T特征帧中的边界框都应用独立的RoAlign(将候选框映射到固定大小的特征图,先aligned到7*7*d,最后最大池化为1*1*d),最终维度为d。若有N个对象,泽RoIAlign处理过后特征尺寸为N*d。随后边构建上述两种关系的图:相似图和时空图。构建完成后使用图卷积进行推理,最终得到输出也为N*d。最终平均池化后得到d维特征。
最终将两个流的d维度特征在最后一维进行拼接输入到全连接层进行视频分类。
三、 ResNet-50 I3D网络
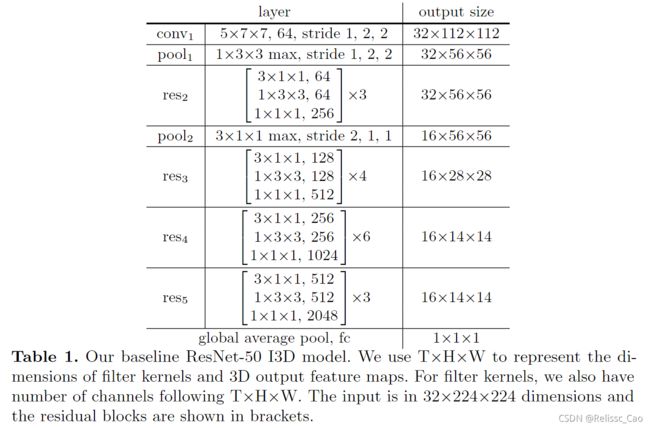
这部分不必细说,便是全局网络图中I3D中的每层网络细节部分。
四、相似图构建
![]() 构建,动机:重点获取任意两个对象之间的长期依赖。
构建,动机:重点获取任意两个对象之间的长期依赖。
作者在特征空间中度量对象之间的相似度来构建相似图,将语义上相关的对象连接起来构造为图结构中的边。其中对于任意一对d维的提取好的边界框中的特征xi,xj(即对象的特征),其相似度计算如下,其中 和分别为词嵌入操作(通常为1*1卷积进行操作):
和分别为词嵌入操作(通常为1*1卷积进行操作):
![]()
最后使用softmax函数来归一化计算出来的相似度:

其实由相似性关系的公式可以看出,其实这个就是和现在的自注意力一致,先对对象进行词嵌入再计算相关性后归一化作为注意力参数。而这里将此注意力参数作为连接边的权重参数而已。

如上图所示相似图不仅捕获了视觉空间的相似度,还包含了函数空间的相似度(即对象间的相关性)。其中查询框维橙色,选择的相似性连接图为蓝色框,未选择的边界框为绿色。
五、时空图构建
![]() 与
与![]() 图构建。动机:重点获取相对空间关系和状态变化时序关系。
图构建。动机:重点获取相对空间关系和状态变化时序关系。
We denote the IoU between object i in frame t and object j in frame t + 1 as σij .
if σij is larger than 0, we will link object i to object j using a directed edge i →j with value σij .
即:通过IoU(交并比)来作为前一帧时序到后一帧时序物体所构造的连接边的边值权重,最后也是将得到的边权值进行归一化:
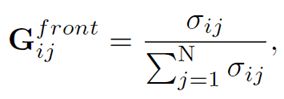
其中上述公式所计算的 ![]() 便作为正向(前一帧至后一帧的有向边)时空图的邻接矩阵,其构建的对象的边与轨迹可视化如下图所示:
便作为正向(前一帧至后一帧的有向边)时空图的邻接矩阵,其构建的对象的边与轨迹可视化如下图所示:

当然除了构造连接对象从帧t至t+1的正向图外,用一致的方法构造了连接对向从t+1帧至t帧的反向图,其邻接矩阵表示为:![]() ;其计算过程与
;其计算过程与![]() 一致。
一致。
思考:为何不直接构建双向无向图?
其实仔细阅读在文中寻找,便不难得出:作者之所以构造时空图,其重点是让时空图获取相对空间关系和状态变化时序关系。而虽然直接构建无向图可以减少构造成本,但是却无法获取到时序关系。
六、图卷积计算
图卷积分为两步:1、邻域信息聚集(就是特征图乘以其图结构的邻接矩阵,便可聚集邻居信息,如下公式所示便指车G*X);2、特征更新(就是乘以可学习的参数,以下公式为例就是X*W)。

而对于有多种构造的图来说,便将不同构造的图卷积结构在一次图卷积中简单进行相加融合:

作者最初是使用上述直接将3种图的卷积直接如上式进行融合发现效果甚至比使用单种图还要差,作者分析后得出,相似图中是有可学习参数的 { 相似图的邻接矩阵权值(邻接矩阵的权值就是存放连接边的权重)计算进行了词嵌入 } ,而时空图(时空图的邻接矩阵权值计算直接使用IoU计算)种却不需要,因此作者最后构造了两个图卷积分支,将他们分别单独学习而在最后进行结果的融合。即如下图红框中分为了原图卷积网络其实拥有两个网络分支,最后融合是相加:

七、动作识别
最终将图卷积后的特征进行全局平均池化,I3D的全局视频特征表示也进行全局平均池化;都得到1*d维度的特征。然后将2个流的特征拼接气力啊输入至全连接层进行视频分类任务。
八、实验结果
动作识别的任务精度:
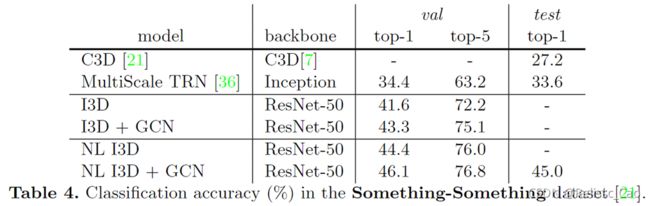
这篇论文在2018年精度已经是state-of-the-art了!