Redis使用Lua脚本:保证原子性【项目案例分享】
文章目录
- 前言
- Lua脚本原子性介绍
- Redis执行Lua的原生EVAL命令
- 案例1:生成雪花算法workerId
-
- 背景
- 技术方案
- Jedis调Lua源码
- 案例2:限制并发更新课件播放进度
-
- 背景
- 技术实现
- Jedis调Lua源码
- 总结
前言
本文主要分享2个项目里使用lua脚本的实战案例,主要使用lua脚本保证原子性. 在正式介绍项目案例之前,我们先对Lua脚本以及如何在Redis中使用有个基本的了解。
Lua脚本原子性介绍
Redis 使用单个 Lua 解释器去运行所有脚本,并且, Redis 也保证脚本会以原子性(atomic)的方式执行:当某个脚本正在运行的时候,不会有其他脚本或 Redis 命令被执行。这和使用 MULTI / EXEC 包围的事务很类似。在其他别的客户端看来,脚本的效果要么是不可见的,要么就是已完成的。
Redis执行Lua的原生EVAL命令
在redis-cli 使用EVAL执行Lua脚本, 语法如下:
EVAL script numkeys key [key …] arg [arg …]
4个参数说明:
script 参数: 要执行的Lua脚本.
numkeys 参数: 用于指定key的个数.
key [key ...] 参数 可变参数, 与java的参数…类似,通过全局变量KEYS 数组,用下标从 1 开始访问( KEYS[1] , KEYS[2] ,以此类推).
arg [arg ...]参数 可变参数, 与java的参数…类似,通过全局变量ARGV 数组,用下标从 1 开始访问( ARGV [1] ,ARGV [2] ,以此类推).
我们使用redis-cli执行一个简单的示例:
eval "return {KEYS[1],KEYS[2],ARGV[1],ARGV[2]}" 2 key1 key2 first second
Lua脚本函数可以返回多个值,每个值以逗号隔开,这点和golang类似, 结果以下:

案例1:生成雪花算法workerId
背景
项目是这样定义雪花算法的id来避免重复的(即datacenterId+workerId保证唯一):
datacenterId:每个服务一个固定id,配置在每个服务的配置中(比如Apollo),这样各服务生成的id肯定是不重复的。
workerId:每个服务内的实例一个固定id,保证同一个服务内的workerId不同。如何保证呢?
这时就需要在服务实例启动时动态生成workerId,因为运维不支持对每个Pod实例配置固定id,另外Pod的ip或name根据hash以后落到0~31之间是可能重复的(hash冲突). 所以我们采用的是使用redis来动态生成并存储datacenterId对应的workerId。
技术方案
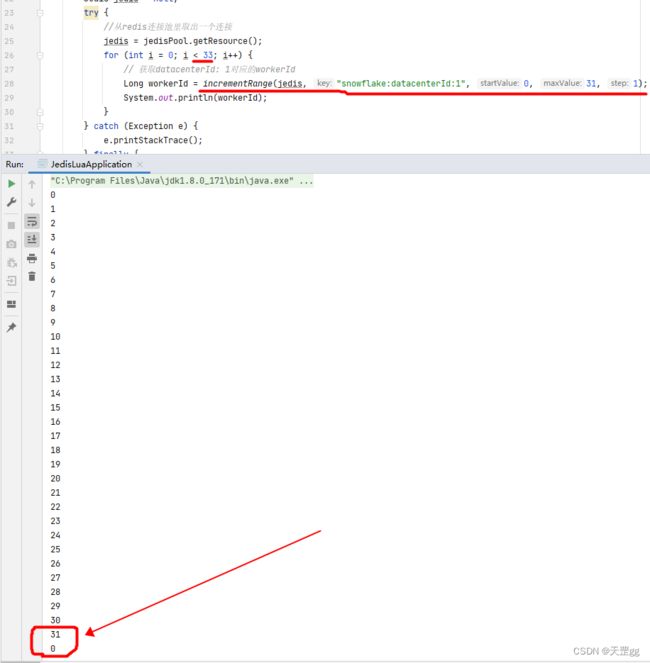
这里我们需要实现的是在Redis记录datacenterId对应的自增长的workerId,在0~31之间(workerId的范围)自增长,多个实例同时请求时保证原子性,另外由于会反复重新部署,所以当达到31以后,我们需要从0重新开始。
相当于实现的效果是从0开始,自增到31以后,再从0开始,以此类推…
Jedis调Lua源码
public static Long incrementRange(Jedis jedis, String key, int startValue, int maxValue, int step) {
// KEYS[1] = key, ARGV[1] = startValue, ARGV[2] = maxValue, ARGV[3] = step
String script = "local v = redis.call('get', KEYS[1]);" +
// 如果有值,并且小于maxValue,自增1
"if (v and tonumber(v) < tonumber(ARGV[2]) ) then " +
"return redis.call('incrby', KEYS[1], ARGV[3]); " +
"end; " +
// 否则设置初始值startValue
"redis.call('SET', KEYS[1], ARGV[1]); " +
"return ARGV[1]; ";
List<String> keys = Collections.singletonList(key);
List<String> args = Arrays.asList(String.valueOf(startValue), String.valueOf(maxValue), String.valueOf(step));
Object result = jedis.eval(script, keys, args);
return Long.valueOf(result.toString());
}
这里的流程大家都懂:先执行get命令,如果key存在且小于31,执行incrby命令,否则直接执行set key 0。
简单介绍几个lua脚本的语法:
- 变量声明
local v
- Lua脚本中调用redis命令
redis.call()
-
tonumber
转数字函数 -
if语法
if(布尔表达式)
then
-- 在布尔表达式为 true 时执行的语句
end
- if else语法
if(布尔表达式)
then
-- 布尔表达式为 true 时执行该语句块
else
-- 布尔表达式为 false 时执行该语句块
end
执行33次我们看下效果:
案例2:限制并发更新课件播放进度
背景
项目里需要记录每个学习课件的人看的视频的播放进度,每隔N秒更新一下最后观看时间,但前端并不能很好的控制频率,因为有各种刷新、多开等情况,所以后端需要限制并发请求更新,1是保证数据正确,2是提高性能,保证不重复更新。
技术实现
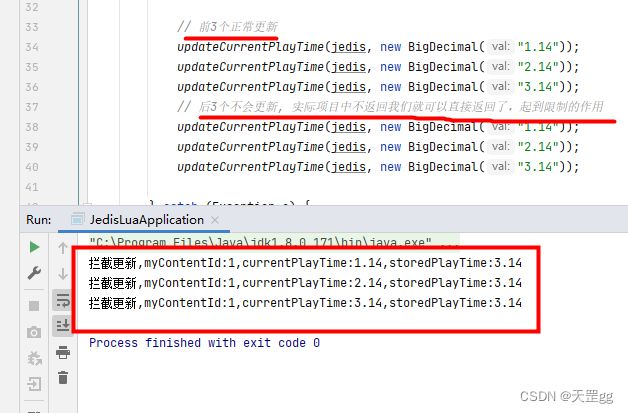
这里我们需要实现的是在Redis里缓存当前播放记录的当前进度,如果缓存不存在或值小于当前值,再更新,否则直接返回Redis的值,相当于限制了重新更新。
Jedis调Lua源码
/**
* 设置如果不存在或小于value,返回生效的value
*
*/
public static BigDecimal setnxOrLT(Jedis jedis, String key, BigDecimal value, long timeout) {
String script = "local v = redis.call('get', KEYS[1]);" +
// 如果为空,或者小于value
"if (not(v) or tonumber(v) < tonumber(ARGV[1]) ) then " +
"redis.call('SETEX', KEYS[1], ARGV[2], ARGV[1]); " +
"return nil; " +
"end; " +
"return v; ";
List<String> keys = Collections.singletonList(key);
List<String> args = Arrays.asList(value.toString(), String.valueOf(timeout));
Object result = jedis.eval(script, keys, args);
return result == null ? null : new BigDecimal(result.toString());
}
调用代码:
private static void updateCurrentPlayTime(Jedis jedis, BigDecimal currentPlayTime) {
BigDecimal storedPlayTime = setnxOrLT(jedis, "myContentId:1", currentPlayTime, 5);
boolean ok = storedPlayTime == null;
if (!ok) {
System.out.println("拦截更新,myContentId:1,currentPlayTime:" + currentPlayTime.toString() + ",storedPlayTime:" + storedPlayTime.toString());
}
}
我们看下效果:
总结
以上全是项目落地实现方案,先写2个,后续持续更新,小伙伴如果觉得有帮助,建议关注+收藏,感谢支持!