第四章 Jetson Nano Unet TensorRT模型推理
Jetson Nano系列学习
第一章 Jetson Nano烧录镜像及jtop安装
第二章 Jetson Nano安装Archiconda、PyTorch、torchvision
第三章 Jetson Nano 虚拟环境中使用PyQt5及TensorRT
文章目录
- Jetson Nano系列学习
- 前言
- 一、使用onnx将.pth文件转化为.onnx文件
- 二、使用onnx2trt工具转engine
-
- 1. 下载并安装onnx-tensorrt
- 2. 将onnx文件转化为tensorrt的engine文件
- 三、模型推理
-
- 1.common.py
- 2. inference.py
前言
由于在Jetson nano上运行pytorch生成的.pth模型文件,推理速度很慢,故需要将模型转化为tensorrt的引擎文件,使用Jetson nano自带的tensorrt进行加速推理。由于tensorrt中未实现Unet网络中上采样采取的bilinear双线性插值操作,故上采样使用ConvTranspose2d实现,将上采样中bilinear值设为False,Unet模型参考Pytorch-Unet
首先使用Unet模型训练好的.pth模型文件利用onnx库转化为.onnx模型文件,然后利用onnx-tensorrt将onnx模型文件转换为tensorrt的engine文件即.trt模型文件,最终使用tensorrt进行推理。参考
一、使用onnx将.pth文件转化为.onnx文件
from src import UNet
import torch
import onnx
# 模型路径
model_path = "best_unet.pth"
if __name__ == "__main__":
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
# input shape尽量选择能被2整除的输入大小
dummy_input = torch.randn(1, 3, 584, 565, device=device)
# 1. Unet模型创建
model = UNet(in_channels=3, num_classes=1, bilinear=False).to(device)
# model = model.cuda()
print("create U-Net model finised ...")
# 2. 加载权重
state_dict = torch.load(model_path, map_location=device)['model']
model.load_state_dict(state_dict)
print("load weight to model finised ...")
# 3. 将torch格式转化为onnx
input_names = ["input"]
output_names = ["output"]
torch.onnx.export(model,
dummy_input,
"best_unet.onnx",
verbose=True,
input_names=input_names,
output_names=output_names)
print("convert torch format model to onnx ...")
# 4. 检查生成的onnx文件
net = onnx.load("best_unet.onnx")
onnx.checker.check_model(net)
onnx.helper.printable_graph(net.graph)
二、使用onnx2trt工具转engine
1. 下载并安装onnx-tensorrt
git clone --recurse-submodules https://gitee.com/Mr_xiaolong/onnx-tensorrt.git
1. cd onnx-tensorrt
2. mkdir build && cd build
3. cmake .. -DTENSORRT_ROOT=/usr/lib/python3.6/dist-packages/tensorrt/
报错1:cmake版本太低
解决:升级cmake版本
pip3 install cmake --upgrade -i https://pypi.mirrors.ustc.edu.cn/simple
报错2: Could NOT find Protobuf (missing: Protobuf_LIBRARIES Protobuf_INCLUDE_DIR)
原因:缺少安装依赖包libprotobuf、protobuf
解决:安装 libprotobuf-dev protobuf-compiler 参考
sudo apt-get install libprotobuf-dev protobuf-compiler
protoc --version
cmake version 3.22.4
4. make -j
报错1: /usr/include/aarch64-linux-gnu/NvInferRuntimeCommon.h:56:10: fatal error: cuda_runtime_api.h: 没有那个文件或目录
解决:配置cuda相关环境环境变量 参考
编辑 ~/.bashrc文件
sudo vim~/.bashrc
export CPATH=/usr/local/cuda-10.2/targets/aarch64-linux/include:$CPATH
export LD_LIBRARY_PATH=/usr/local/cuda-10.2/targets/aarch64-linux/lib:$LD_LIBRARY_PATH
export PATH=/usr/local/cuda-10.2/bin:$PATH
export CUDA_ROOT=/usr/local/cuda-10.2
更新配置文件
source ~/.bashrc
报错2: Makefile:160: recipe for target ‘all’ failed make: *** [all] Error 2
解决:在make -j 后加上VERBOSE=1参数,如执行make -j4 VERBOSE=1,-j后面表示的是CPU核数 解决参考
make命令详解
5. sudo make install
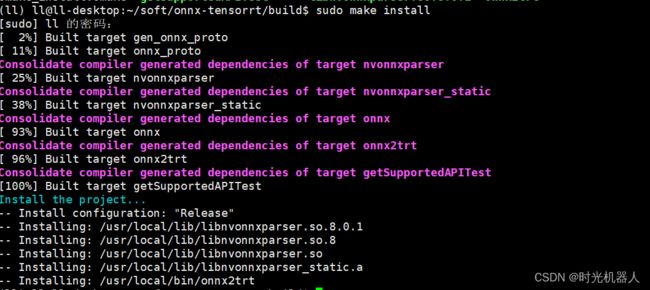
onnx2trt安装成功!!!
onnx2trt
onnx2trt -V

2. 将onnx文件转化为tensorrt的engine文件
onnx2trt best_unet.onnx -o best_unet.trt
三、模型推理
1.common.py
import os
import argparse
import pycuda.driver as cuda
import pycuda.autoinit
import tensorrt as trt
# Allocates all buffers required for an engine, i.e. host/device inputs/outputs.
def allocate_buffers(engine):
inputs = []
outputs = []
bindings = []
stream = cuda.Stream()
for binding in engine:
size = trt.volume(engine.get_binding_shape(binding)) * engine.max_batch_size
dtype = trt.nptype(engine.get_binding_dtype(binding))
# Allocate host and device buffers
host_mem = cuda.pagelocked_empty(size, dtype)
device_mem = cuda.mem_alloc(host_mem.nbytes)
# Append the device buffer to device bindings.
bindings.append(int(device_mem))
# Append to the appropriate list.
if engine.binding_is_input(binding):
inputs.append(HostDeviceMem(host_mem, device_mem))
else:
outputs.append(HostDeviceMem(host_mem, device_mem))
return inputs, outputs, bindings, stream
# This function is generalized for multiple inputs/outputs.
# inputs and outputs are expected to be lists of HostDeviceMem objects.
def do_inference(context, bindings, inputs, outputs, stream, batch_size=1):
# Transfer input data to the GPU.
[cuda.memcpy_htod_async(inp.device, inp.host, stream) for inp in inputs]
# Run inference.
context.execute_async(batch_size=batch_size, bindings=bindings, stream_handle=stream.handle)
# Transfer predictions back from the GPU.
[cuda.memcpy_dtoh_async(out.host, out.device, stream) for out in outputs]
# Synchronize the stream
stream.synchronize()
# Return only the host outputs.
return [out.host for out in outputs]
2. inference.py
from tensorrt import tensorrt as trt
import common
import torch
import time
import numpy as np
from PIL import Image
from torchvision import transforms
# TensorRT logger singleton
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
# 加载tensorrt引擎文件
def load_engine(trt_path):
# 反序列化引擎
with open(trt_path, "rb") as f, trt.Runtime(TRT_LOGGER) as runtime:
return runtime.deserialize_cuda_engine(f.read())
class TRTInference(object):
"""Manages TensorRT objects for model inference."""
def __init__(self, trt_engine_path):
"""Initializes TensorRT objects needed for model inference.
Args:
trt_engine_path (str): path where TensorRT engine should be stored
"""
# TRT engine placeholder
self.trt_engine = None
if not self.trt_engine:
print("Loading cached TensorRT engine from {}".format(
trt_engine_path))
self.trt_engine = load_engine(trt_engine_path)
# This allocates memory for network inputs/outputs on both CPU and GPU
self.inputs, self.outputs, self.bindings, self.stream = \
common.allocate_buffers(self.trt_engine)
# Execution context is needed for inference
self.context = self.trt_engine.create_execution_context()
# 模型推理
def infer(self, img_path):
# 将输入图像转化为RGB图像
original_img = Image.open(img_path).convert('RGB')
# 将输入图像转化为tensor并做标准化处理
mean = (0.709, 0.381, 0.224)
std = (0.127, 0.079, 0.043)
data_transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize(mean=mean, std=std)])
img = data_transform(original_img) # img.shape: (3, 584, 565)
# 增加batch维度
img = torch.unsqueeze(img, dim=0) # (1, 3, 584, 565)
img_height, img_width = img.shape[-2:] # 584, 565
# 输入图片
np.copyto(self.inputs[0].host, img.ravel())
# 开始推理,计算推理时间
t_start = time.time()
trt_outputs = common.do_inference(
self.context, bindings=self.bindings, inputs=self.inputs,
outputs=self.outputs, stream=self.stream)
# print("network output shape:{}".format(trt_outputs[0].shape)) # (659920,)
print("TensorRT inference time: {} ms".format(int(round((time.time() - t_start) * 1000))))
outputs = trt_outputs[0].reshape(-1, img_height, img_width) # (2, 584, 565)
return outputs