【Jetson目标检测SSD-MobileNet应用实战教程】(一)训练环境:win11中配置SSD-MobileNet网络训练境搭建
【Jetson目标检测SSD-MobileNet应用实例】(二)制作自己的数据集–数据集的采集、标注、预处理
【Jetson目标检测SSD-MobileNet应用实例】(三)训练自己的检测模型和推理测试
【Jetson目标检测SSD-MobileNet应用实例】(四)在Jetson上使用CSI摄像头进行视频推理并输出检测结果
【Jetson目标检测SSD-MobileNet应用实例】(五)根据输出的检测结果,使用串口和STM32配合进行电机控制
目标检测作为深度学习在计算机视觉中一个非常成功的应用,我们可以借助很多已经通过验证的深度学习网络进行快速的模型训练和应用搭建。这里选用的TensorFlow-Object-Detection-API是谷歌基于TensorFlow框架设计的集合进年来各个目标检测网络的开源库。使用它可以免去重复造轮子搭建网络的麻烦。只需要装备好要用的数据集,通过修改相关参数就可以完成模型的训练。大大加快了各种不同模型的评估进度。
Windows11平台配置模型训练环境
- 为什么使用TensorFlow-Object-Detection-API的SSD-MobileNet
-
-
- 最终效果
-
- 模型训练平台的环境搭建(Win11中进行训练)
-
- 安装Anaconda,CUDA,cuDNN
-
- 补充指令
- 虚拟环境的搭建(重要)
-
- 下载原版库
- 从TensorFlow模型中下载预训练模型ssd_mobilenet_v3_small_coco_2020_01_14模型
- 设置虚拟环境
-
-
- 设置环境变量
- 编译静态库文件并安装:在tensorflow/models/research/ 目录下执行:
-
- 安装库
- 测试API环境
-
为什么使用TensorFlow-Object-Detection-API的SSD-MobileNet
使用TensorFlow-Object-Detection-API是为了得到Tensorflow的输出格式,便于后续的模型转换和量化
使用SSD-MobileNet是为了在小型移动平台上实现较好的检测效果
目前版本的API已经支持了非常多的模型,但我们这里使用的依然是SSD-MobileNetV3网络,目的是为了后续进一步将模型部署到Jetson或者树莓派亦或者RK3399等带有专用加速核的边缘计算板卡上,使用SSD-MobileNetV3可以保证在一定精度的前提下最大程度的提高图像的处理速度。此外更加便利的是Opencv4.5.0版本中的DNN模块对MobileNet网络进行了适配,使得在Jetson这样的设备中可以仅仅只完成OpenCV的相关配置后就可以快速部署模型。很大程度上避免了复杂的环境配置。
此外如果不考虑适配OpenCV,训练直接得到的模型是可以方便的转化为ONNX模型,进而接入TensorRT或者RKNN等第三方适配的推理加速框架中使用。
我们的目标是在低功耗的嵌入式平台上实现目标检测,所以必须要考虑到低算力情况下精度,速度,图像分辨率之间的平衡。
最终效果
在后续的实际检测中,在960x680分辨率下,仅使用OpenCV的DNN模块加载模型进行前向推理,Jetson nano在开启了GPU加速后可以达到18FPS以上,Jetson NX在开启了GPU加速后可以达到54FPS以上,树莓派4B可以达到6FPS左右。配合单片机进行移动机器人的控制,使用裸代码(一套代码实现目标检测、控制、数据串口交互。不依赖ROS等操作环境),在Jetson nano上可以稳定在14FPS,基本实现了实时控制的实际效果。
模型训练平台的环境搭建(Win11中进行训练)
我们的模型均在带有独立NVIDIA显卡的计算机上实现。我的电脑使用的是i5-8300H,显卡是GTX1050Ti,系统WIN11,硬件条件最好高越好,和我差不多配置的也可以训练,就是比较花时间,慢。
安装Anaconda,CUDA,cuDNN
Anaconda直接安装最新版本就可以,具体安装教程不再重复说明。
CUDA,cuDNN的安装教程不再重复说明,自行百度。
重点强调版本:
#Anaconda创建python版本:
python==3.7.11
CUDA==10.0
cudnn==7.6.0
关于安装顺序,在配置生成虚拟python环境之前需要先安装对应的CUDA和cudnn。然后CUDA和cudnn版本要对应,安装的tensorflow版本也要和CUDA和cudnn版本对应(后续会进一步说明)
补充指令
以下指令在cmd命令行中使用
#Anaconda创建虚拟环境:
conda create -n py37 python=3.7.11
#启动虚拟环境:
activate py37
#关闭虚拟环境
deactivate
#检查CUDA版本
nvcc -V
虚拟环境的搭建(重要)
Github上TensorFlow-API是在Linux系统上发展起来的。为了在Windows上设置TensorFlow以训练模型,需要用几种代替方法来代替在Linux上可以正常使用的命令。TensorFlow物体识别API要求使用其提供在Github仓库内的特定的目录结构。它还要求一些额外的Python库,特定的PATH和PYTHONPATH变量的添加,和一些额外的设置命令以使一切运作或训练一个物体识别模型。
下载原版库
地址:https://github.com/tensorflow/models
下载整个TensorFlow物体识别库,点击“Clone and Download”按钮并下载zip文件。打开下载好的zip文件并解压。解压目录尽可能保持简洁,不要出现中文。注意直接下载最新版本。
解压后有以下文件(可能最新版本会有变化,但总体不会影响使用)
从TensorFlow模型中下载预训练模型ssd_mobilenet_v3_small_coco_2020_01_14模型
注意找对git中的路径:tensorflow/models/blob/master/research/object_detection/g3doc/tf1_detection_zoo.md
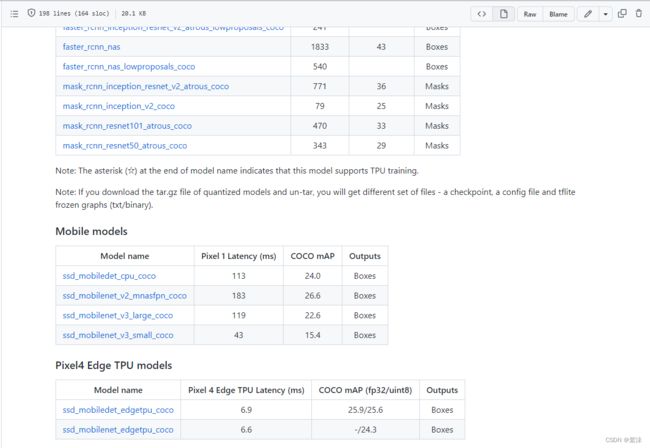
下滑找到对应的模型,在Mobile models中下载ssd_mobilenet_v3_large_coco,small会更快,但是精度更低,按需选择。
下载后解压,注意不能用winrar解压,下载文件后缀是.tar.gz。别的解压软件都可以试一下。将加压后的文件夹移动到先前下载的仓库源码目录:models\research\object_detection\中。
设置虚拟环境
经过前面的CUDA和Anaconda安装之后,新建好python环境,并进入环境。
然后激活这个环境并升级pip:
C:\> activate py37
(py37) C:\>python -m pip install --upgrade pip
安装必要的包:
conda install -c anaconda protobuf
pip install numpy==1.18.5
pip install pillow
pip install lxml
pip install Cython
pip install contextlib2
pip install jupyter
pip install matplotlib
pip install pandas
pip install opencv-python
pip install tensorflow-gpu==1.15.0
pip下载速度慢的,在命令后面加一句:-i https://pypi.mirrors.ustc.edu.cn/simple/换源,例如:
pip install pillow -i https://pypi.mirrors.ustc.edu.cn/simple/
特别强调,要保证numpy=1.18.5,tensorflow-gpu=1.15.0这两个包的版本正确被安装。
设置环境变量
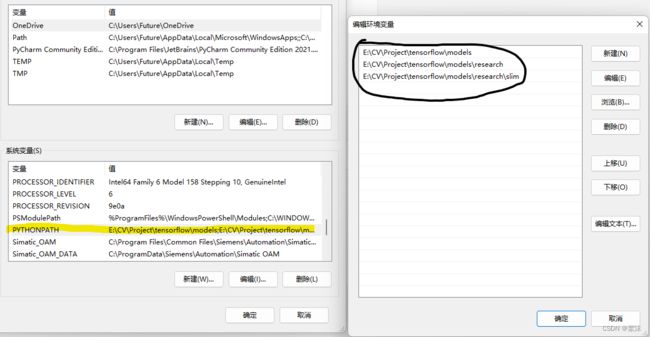
新建环境变量PYTHONPATH指向上面下载的API仓库解压目录的\models,\models\research,和\models\research\slim
例如我的:
编译静态库文件并安装:在tensorflow/models/research/ 目录下执行:
命令行cd到解压的tensorflow/models/research/ 目录下,示例:
(py37) C:\> cd X:\tensorflow\models\research (按照你自己解压的仓库文件路径来)
之后运行:
protoc object_detection/protos/*.proto --python_out=.
执行这一步之后object_detection/protos/路径下所有.proto文件都有一个对应的 _pd2.py,如果哪个没有,就单独编译:protoc --python_out=. .\object_detection\protos\filename123123.proto
(Note:TensorFlow时不时在\protos文件夹下添加新的.proto文件。如果你得到如下错误:ImportError: cannot import name ‘something_something_pb2’,你可能需要将新的.proto文件添加到protoc命令)
安装库
这里的安装要进行两次,第一次在tensorflow/models/research/slim目录下执行:
python setup.py build
python setup.py install
安装完成后将该目录下的setup.py文件复制到tensorflow/models/research文件目录下,在tensorflow/models/research目录下同样执行一遍:
python setup.py build
python setup.py install
这两步情况下可能会产生警告,但不用管继续进行。保证后面测试正常就行。
测试API环境
python object_detection/builders/model_builder_tf1_test.py
如图所示最后提示OK就成功了。
到这里环境配置基本完成,如果没法得到最后的测试结果,注意仔细检查各步骤安装顺序和软件版本