Mask R-CNN翻译
Abstract
我们提出了一个概念简单、灵活和通用的概念对象实例分割框架。我们的方法有效地检测图像中的对象,同时为每个实例生成高质量的分割掩码。这种方法称为Mask R-CNN,扩展速度更快,通过添加一个分支来预测一个对象掩码,与现有分支并行,用于边界框识别。Mask R-CNN是简单的训练,相对于Faster-RCNN只增加了一个小的开销,每秒5帧。此外,Mask R-CNN很容易推广到其他任务中,例如,允许我们在相同的框架中估计人类的姿态。我们显示的结果,在所有三个的可可套件挑战,包括实例分割,边界框对象检测和人的关键点检测。没有技巧,在所有的条目中,Mask R-CNN优于所有现有的,单一模式的模型,包括COCO 2016挑战
赢家。我们希望我们的简单和有效的方法将会作为一个坚实的基础,有助于缓解未来的研究实例级的认可。将提供代码。
1、introduction
在短时间内,视觉社区很快的改进了物体检测和语音分割的结果。在很大程度上,这些提升是在基础的系统的推动下提升的,例如用于图像检测的Fast-RCNN或Faster-RCNN,和用于语义分割的全卷积网络。这些方法在概念上是直观的,并且具有灵活性和健壮性,训练和推理都很快。在这项工作中,我们的目标是开发一个可比较的实例分割框架。
实例分割具有挑战性,因为它需要正确地检测图像中的所有对象,同时精确地分割每个实例。因此,它包含了传统的计算机视觉中的检测任务,目标是对单个对象进行分类,定位每一个边界框然后进行语义分割。
目标是对于每一个像素,将其分类的一系列的没有区分对象实例的类别当中。基于此,人们可能会认为需要复杂的方法才能获得良好的结果。然而,我们展示了一个令人惊讶的简单、灵活和快速的系统,它超越了之前的最先进的实例分割结果。

原则上讲,Mask R-CNN是Faster-RCNN的一个扩展,然而正确的构建mask分支对于正确的结果是至关重要的。更重要的是,Faster-RCNN 不是为了网络输入输出之间的像素对其而设计的,这一点在ROPOOl上尤为明显,事实上的核心操作是支持实例,对特征提取进行空间量化。为了修正偏差,我们提出了一个简单的、没有量化的层,称为ROLALign,它能够保留空间的位置。尽管它看起来是一个微小的变化,ROIAlign有巨大的影响:它将mask的准确性从10%提升到了50%,在更严格的本地量化下得到更大的收益。第二,我们发现分离mask和类的预测是很有必要的:我们独立地预测每个类的二进制掩码,没有类之间的竞争,并依靠网络的RoI分类分支来预测类别。与之相比,FCN通常采用逐像素多类别的分类,它是对图像的分割和分类,在我们的实验中,结果不理想。
没有花哨的东西,Mask R-CNN超越了之前所有的最先进的单一模型在COCO实例分割任务上的结果,包括来自2016年竞赛获胜者的高质量工程作品。作为一个副产品,我们的方法也擅长于COCO对象检测任务。在消融实验中,我们评估了多个基本实例,这使我们能够证明其鲁棒性,并分析核心因素的影响。
我们的模型可以在GPU上以每帧200毫秒的速度运行,而在一台8-GPU机器上进行COCO的训练需要一到两天的时间。我们相信,快速训练和测试速度,以及框架的灵活性和准确性,将有利于和方便未来的研究实例分割。
最后,通过对COCO关键数据集进行人体姿态估计,展示了该框架的通用性。通过将每个关键点视为一个热的二进制掩码,通过最小的修改Mask R-CNN可以应用于检测特定实例的姿态。没有技巧,Mask R-CNN超越了2016年COCO 关键点比赛的冠军,同时以5帧/秒的速度运行。因此,Mask R-CNN可以被更广泛地视为实例级识别的灵活框架,并且可以方便地扩展到更复杂的任务。
我们将发布代码,以方便后来的研究。
2、相关工作
R-CNN: 这个基于区域的CNN(R-CNN)对边界框回归物体检测,是在每个Rol上独立地处理可管理的候选对象区域,和评估卷积网络。R-CNN得到了扩展,允许使用Rol Pool处理特征图上的Rols。这样使其速度快,精度高。Faster R-CNN通过学习区域建议网络(RPN)的注意机制,改进了这个流。Faster R-CNN是灵活的和强健的以许多后续的改进,是目前几个基准中领先的框架。
instance Segmentation: 在RCNN的有效驱动下,许多分割的方法都是在segment proposals的基础上进行的。较早的方法采用自下而上的分割。DeepMask和后续的工作学习提取候选片段,然后Fast R-CNN对它进行分类。在这些 方法中,分割先于识别,这将降低准确度。同样的,Dai等人提出的复杂的多阶段级联方法,该方法用于预测边界框提议的分割提议,然后是分类。相反,我们的方法是基于mask的预测和类标签的并行预测,它更加的简单和灵活。
最近,Li等人将segment proposals系统和物体检测系统相结合,实现了全卷机实例分割(FCIS)。
这个相同的想法是去预测一组位置敏感的全卷积的输出通道。这些通道同时强调物体的类别、框和掩码,使系统快速运行。但是FCIS展示了系统的错误在重叠的实例上,还创造了虚假的边缘(图5),表明它受到分割实例的基本挑战。
3、Mask R-CNN
Mask R-CNN在概念上很简单:Faster R-CNN对于每一个候选物体有两个输出,一个类标签,一个边界框偏离;基于此,我们增加了第三个分支输出物体的mask。Mask R-CNN是一个自然而然的,很直观的想法。但是增加的mask 输出和类别还有框的输出不一样,它需要更加提取更精细的对象空间布局。接下来,我们介绍Mask R-CNN的关键要素,包括像素到像素的对齐,这是fast/faster R-CNN主要遗漏的地方。
Faster R-CNN: 我们首先简要回顾一下Faster R-CNN检测器。Faster R-CNN由两个阶段组成。第一个阶段,称为区域提议网络(RPN),建议候选物体边界框。第二阶段,本质上是Fast R-CNN,从每一个候选框中,使用RolPool提取特征,然后进行分类和边界框回归。这两个阶段的特征可以共享,以实现更快的推理,我们建议读者参考【21】,以获得最新的、全面的Faster R-CNN和其他框架之间的比较。
Mask R-CNN: Mask R-CNN 采用相同的两阶段的进程,第一阶段相同(都是RPN)。在第二阶段,平行的预测类和框的偏移,Mask R-CNN 也会为每一个Rol输出一个二进制的掩码。它与最新的系统形成对比,最新的系统的分类都是依赖于mask 预测。我们的方法遵循Faster R-CNN的精神,即并行的运行边界框回归分类和回归(这在很大程度上简化了原始的R-CNN的多级通道)。
在正式的训练过程中,我们在每个采样的Rol上定义了多任务损失为 L = L c l s + L b o x + L m a s k L = L_{cls}+L_{box}+L_{mask} L=Lcls+Lbox+Lmask。分类损失和边界框回归损失与定义中的相同。对于每一个ROI,这个mask 分支有一个 K m 2 Km^2 Km2维度的输出,每一个对应于K个类别。基于此,我们应用了每像素的sigmoid,并将mask定义为平均的二进制交叉熵损失。对于与ground-truth类相关的k, L m a s k L_{mask} Lmask只是定义在第k个mask上(其他的mask的损失不计算损失)。
我们对于 L m a s k L_{mask} Lmask的定义,允许网络产生mask对于每一个类别不需要类别之间的竞争。我们依赖于专用的分类分支来预测用于选择输出掩码的类标签。这是解耦掩码和类别预测。这与通常将FCNs[29]应用于语义分割的做法不同,后者通常使用每个像素的softmax和多项交叉熵损失。在这种情况下,各个掩码相互竞争。在我们的例子中,和他们不同的是,使用的是每个像素的sigmoid和二进制损失。实验证明,该方法是获得良好的实例分割结果的关键。
Mask Representation: mask编码一个输入物体的空间布局。因此,与不可避免的被全连接层折叠成的短输出向量不同,利用卷积提供的像素对像素的对应关系,可以很自然地提取mask的空间结构。
特别的,我们使用FCN从每一个ROI中,预测一个 m × m m×m m×m的mask。这使得mask分支中的每一层都可以保持显式的 m × m m×m m×m对象空间布局,而不会将其折叠成缺乏空间维度的向量表示。不同于之前的借助于FC层进行mask预测,我们的全卷积层需要更少的参数,实验表明,这样具有更高的精度。
这种像素对像素的方式需要我们的RoI特征,它们自己就是小的特征图,保持良好的对齐,以保持显式的逐像素空间对应。这促使我们去开发接下来的RoIAlign layer,它在mask的预测中扮演了至关重要的角色。
RoIAlign: RolPool是一种标准的,从每一个RoI中,提取小特征图的操作。RoIPool首先将浮点数的RoIl量化为特征图的离散程度,这些量化的RoI被细分为空间的bins,这些bins也被量化,最后,被每一个bin所覆盖的特征值被整合(通常使用max Pooling)。在那些以16为步长的feature map和【.】舍入的地方,在其上的每一个连续的坐标x上通过计算【x/16】,进行量化。量化是在分成bins的时候进行的(eg: 7 × 7 7×7 7×7)。这些量化在RoI和特征提取之间引入了不对齐。尽管它会影响分类,但是它会强化小的偏移,它对预测准确的像素mask有很大的负面的影响。
去强调这些,我们提出了一个RoIlAlign层,它去除了RoIPool的粗糙的量化,准确的将输入的和特征的特征对其。我们的提议其实很简单:我们避免了许多量化的Rol的边界或者bins(我们使用x/16代替【x/16】)。我们使用双线性插值[22]来计算每个RoI bin中四个规则采样点的输入特征的精确值,并将结果聚合(使用max或average).
正如4.2所示,RoiAlign带来了极大的提升。我们在【10】中也比较了RoIWarP的操作,不同于RoIAlign,RoIWarp忽略了对齐问题,它像RoIPool一样,量化了RoI应用于【10】。因此,虽然RoIWarp也采用了[22]激励下的双线性重采样,但实验结果表明,其性能与RoIPool相当(详见表2c),说明了对齐的关键作用。
Network Architecture: 为了演示我们的方法的通用性,我们用多个架构实例化了Mask R-CNN。为了清楚起见,我们区分它们:(i)用于提取整张图像特征的卷积主干结构,(ii)边界框回归的网络(分类和回归)和分别应用于每一个RoI的mask预测。
我们使用命名法网络深度特征来表示主干网络。我们评估深度为50或者101层的ResNet和ResNeXt网络。Faster R-CNN最初使用ResNets,它从第四阶段的最后一个卷积层中提取特征。我们称它为C4。例如,它的主干网络是ResNet-50,我们用ResNet-50-C4来表示。这是一种在【19,10,21,36】中,常用的表示方法。
我们也研究了Lin等人最近提出的更有效的,称之为特征金字塔网络(FPN)的主干网络。FPN使用具有横向连接的自顶向下架构,从单尺度输入构建网络内特征金字塔。Faster R-CNN与FPN骨干网络,从不同层次的特征金字塔中,根据他们的规模提取RoI特征,但其他方面的方法类似于vanilla ResNet。mask R-CNN使用ResNet-FPN为主干提取特征,在精度和速度上都有很好的提高。关于FPN的更多细节,请读者参考[27]。
对于网络,我们严格遵循前面工作中介绍的架构,其中我们添加了一个全卷积掩码预测分支。具体来说,我们从ResNet[19]和FPN[27]论文中扩展了速度更快的R-CNN盒头。细节如图3中所展示的那样。ResNet-C4主干网络的起始,包括第五阶段的ResNet(第九层的‘res5’【19】),这是加强的计算。对于FPN,主干网络已经包括res5,因此,允许一个更有效的头,使用更少的过滤器。
我们注意到我们的mask 分支有一个简单的结构,更多复杂的设计有助于提升性能。但是这不是这项工作的重点。
3.1. Implementation Details
我们遵循已经存在Fast/Faster R-CNN网络【12,34,27】设置超参数。尽管在原始的论文中,这些设置是为了物体检测【12,34,27】,但是我们发现我们的实例分割系统对他们是稳健的。
Training: 正如在Fast R-CNN中,一个RoI,与真实的边界框的IOU大于0.5,那么它就是一个正例,反之,就是负例。mask的损失 L m a s k L_{mask} Lmask只计算正例。mask目标是RoI及其相关的真相mask之间的交集。
我们使用以图像为中心的训练。调整图片的大小,使其尺寸(短边)为800像素。对于每一个GPU,每个小批次有2张图像,每张图像有N个采样roi,正样本与负样本的比例为1:3【12】。对于C4的主架来说,N是64(如【12,34】所示)和FPN为512(如【27】)。我们在8的GPU(有效的小批次大小为16)上训练160K次的迭代,学习率在120k次迭代后减少10倍为0.02。我们使用权重衰减为0.0001,动量为0.9.
RPN anchors 锚包括5个尺寸,3个纵横比,正如[27]。为了方便消融,RPN是经过单独训练的,不与mask R-CNN共享特征,除了特有的。对于本文中的每个条目,RPN和Mask R-CNN都有相同的主干,因此它们是可共享的。
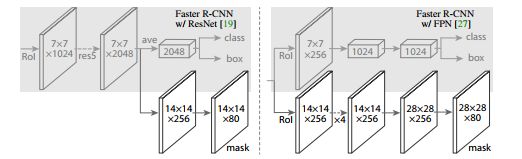
图3. Head 结构:我们扩展了现有的两个Faster R CNN Head[19,27]。左/右面板显示了ResNet C4和FPN主骨架的头部,分别来自[19]和[27],其中添加了一个掩模分支。数字表示空间分辨率和通道。从上下文可以推断,箭头表示conv、deconv或fc层(conv保留空间维度,当deconv增加它的时候)。所有的convs都是3x3,除了输出的conv是1x1, deconvs是2x2的且步长为 2,我们在隐藏层中使用ReLU[30]。左:'res5’表示ResNet的第五个阶段,为了简单起见,我们进行了修改,使第一个conv 运算在7x7 Rol下且步长为1(而不是像【19】中的14x14/ stride 2)。右:“x4”表示由四个连续的conv组成的栈。
Inference: 在测试的时候,C4主架有300个proposal(【34】),FPN有1000个(【27】)。我们运行边框预测分支在这些proposals上,然后是非极大值抑制【14】。mask 分支应用于得分最高的100个检测框。尽管这与训练中是使用的并行计算不同,它加速推理和提升准确性(由于使用更少。更准确的RoIs)。mask分支每个RoI能够预测K个mask,但是我们只使用了第k个mask,k 是类别分支预测的类别。这个 m × m m \times m m×m个浮点数mask 输出调整为RoI 的大小,以阈值为0.5进行二值化。
注意到,我们只计算了前100个检测框的mask。Mask R-CNN 增加边缘运行时与它的配对的Faster R-CN(e.g在典型模型是约20%)。
图4。使用ResNet-101-FPN,以5帧/秒的速度运行,更多Mask R-CNN对COCO测试图像的检测结果,Mask的AP为35.7(表1)。
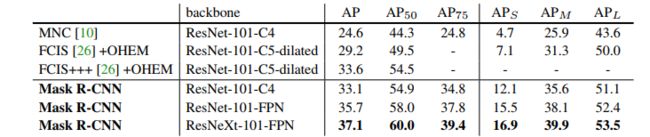
表1。实例分割mask AP在COCO test-dev上。MNC【10】和FCIS【26】分别是2015年和2016年COCO分割
挑战的冠军。没有任何花里胡哨的东西,Mask R-CNN的性能优于更复杂的FCIS+++。其中包括多尺度训练/测试,水平翻转测试,和OHEM【35】。所有条目都是单一模型的结果。
4.实验:实例分割
我们进行了一个全面的比较,mask R-CNN的现状与综合烧蚀实验。我们使用COCO数据集对于所有的实验。我们报告了标准的COCO指标,包括AP(超过IoU阈值的平均), A P 50 , AP_{50}, AP50, A P 75 , h 和 AP_{75},h和 AP75,h和 A P S , AP_{S}, APS, A P M , AP_{M}, APM, A P L , AP_{L}, APL,( A P AP AP在不同的尺寸上)。除非另有注释,AP使用mask IoU进行评估。正如之前的工作【5,27】,我们使用80k张训练的图片的集合,和35k张验证图片的集合(trainval 35k)。并报告剩余5k val图像子集(minival)的消融情况。我们还报告了test-dev【28】,它没有公开的标签。一旦发布,我们将按照建议将测试结果上传到公众排行榜上。
4.1 主要结果
我们将Mask R-CNN与表1中最先进的实例分割的方法进行比较。我们模型的所有瞬时性能都优于前一种最先进模型的基线。这包括MNC 1101和FCIS[26],它们分别是2015年和2016年COCO细分挑战的获胜者。没有花里胡哨的东西,带ResNet-101-FPN骨干的Mask R-CNN优于FCIS+++【26】,其中包括多尺度训练/测试、水平翻转测试和在线难示例 (OHEM)【35】。虽然超出了这项工作的范围,但是我们仍然期待许多这样的改进适用于我们的网络。
Mask R-CNN的输出如图2和图4所示。即使在挑战的条件下,Mask R-CNN仍然取得了良好的效果。在图5中,我们比较了Mask R-CNN基线和FCIS++【26】。FCIS+++在重叠的实例上展示了系统的构件,表明它是由实例分割的基本困难所决定的,而Mask R-CNN没有显示这样的构件。
4.2消融实验
我们进行了一些消融分析Mask R-CNN。结果如表2所示,下面详细讨论。
**Architecture:**表2a展示了不同网络主架的Mask R-CNN。它得益于更深层次的网络(50 vs. 101)和包括FPN和ResNeXt在内的先进设计。我们注意到,并不是所有的框架都能自动从更深层次或更高级的网络中获益(参见【21】中的基准测试)。

图5. FCIS+++【26】(上) vs Mask R-CNN(下,ResNet-101-FPN)。FCIS在重叠的物体上显示出系统性的伪影。
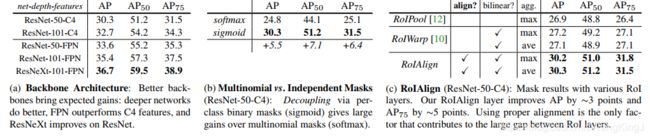

表2。Mask R-CNN的消融。除非另有说明,我们在trainval35k上训练,在minival上测试,并报告mask AP。
多项式与独立掩码: MaskR-CNN耦合mask与类预测:正如现有的box分支预测类标签一样,我们为每个类生成掩码,而类之间不存在竞争(通过每个像素的sigmoid和二进制损失)。在表2b中,我们将其与使用每个像素的softmax和多项损耗进行比较(如FCN【29】中使用的commonly)。这种方法将掩模任务和类预测任务耦合起来,导致mask AP严重下降(5.5分)。这表明,一旦实例被分类为一个整体(通过box分支),就足够预测一个不考虑类别的二进制mask,这使得模型更容易训练。
特定类与不可知类Mask: 我们的默认实例化预测特定的掩码,i.e.,每个类是 m × m m \times m m×m个mask。有趣的是,类不可知论的Mask R-CNN(预测一个单一的 m × m m \times m m×m的输出代替类别)几乎是同样的有效。对在ResNet-50-C4上的类特定副本中,它们的mask AP为29.7 vs 30.3。这进一步突出了我们的方法中的劳动分工,该方法在很大程度上解耦了分类和分割。
RolAlign: 对我们提议的RolAlign层的评估如表2c所示。在这个实验中,我们使用了ResNet 50-C4的主架,它有stride 16。RolAlign改善AP比RolPool高出3点,大部分收益来自高IoU( A P 75 AP_{75} AP75)。RolAlign对max/average pool不敏感;我们在本文的其余部分使用average。
此外,我们还与MNC【10】中提出的采用双线性抽样的RolWarp方法进行了比较。正如§3中所讨论的,RolWarp仍然会量化Rol,失去与输入的对齐。如表2c所示。每个表单的翻转与RolPool相当,但比RolAlign差得多。这突显出正确的对齐的重要性。
我们还评估了使用ResNet-50-C5主架的RolAlign,其步幅更大,为32像素。我们使用与图3(右)相同的头,因为res5头不适用。表2d显示,RolAlign极大地提高了掩模 A P AP AP 7.3点,mask A P 75 AP_{75} AP75提高了10.5点(50%的相对改进)。此外,我们注意到在RolAlign中,使用stride-32 C5特征(30.9 A P AP AP)比使用stride-16 C4功能(30.3 A P AP AP,表2c)更有效。RolAlign在很大程度上解决了长期以来使用大跨度特征进行检测和分割的挑战。最后,在使用FPN时,RolAlign显示了1.5 mask` A P AP AP和0.5 box A P AP AP的增益,FPN具有更精细的多级步长。对于需要更精确对齐的关键点检测,即使使用FPN, RolAlign也可以获得较大的收益(表6)。

表3。对象检测单一模型结果(边界框 A P AP AP),与test-dev的最新技术相比。使用ResNet-101-FPN的MaskR-CNN的性能优于之前所有最先进模型的基本变体(在这些实验中忽略了mask输出)。Mask R-CNNDe收益在【27】上的使用来自于RolAlign (+1.1 A P b b AP^{bb} APbb)、multitask training (+0.9 A P b b AP^{bb} APbb)和ResNeXt-101 (+1.6 A P b b AP^{bb} APbb)。
Mask 分支: 分割是一个像素到像素的任务,我们利用FCN来实现mask的空间布局。在表2e中,我们使用ResNet-50-FPN主架比较多层感知器(MLP)和FCNs。使用FCNs提供2.1掩码 A P AP AP增益超过MLPs。我们注意到,我们选择这个主干,为的是FCN头部的conv层没有预先训练,以便与MLP进行公平的比较。
4.3 边界框回归检测结果
我们将Mask R-CNN与表3中,在COCO数据集上,最先进的边界框物体检测相比较。对于这个结果,即使训练了完整的Mask R-CNN模型,在推断时也只使用分类和框输出(mask的输出被忽略)。使用ResNet-101-FPN的Mask R-CNN优于所有以前的先进模型的基本变体,包括G-RMI【21】的单模型变体,它是2016COCO检测挑战的冠军。使用ResNeXt - 101-FPN。Mask R-CNN进一步提升了结果,与之前最好的单一模型条目【36】(使用inception-ResNet-v2-TDM)相比,框 A P AP AP有3.0分的优势。
作为进一步的比较,我们训练了一个版本的Mask R-CNN,但是没有Mask分支,在表3中用“Faster R-CNN, RolAlign”表示。由于采用了RolAlign,该模型的性能优于【27】中的模型。另一方面,box A P AP AP比Mask R-CNN低0.9个点,因此Mask R-CNN在box检测上的差距仅仅是由于多任务训练的好处。
最后,我们注意到Mask R-CNN在Mask和box A P AP AP之间有一个小的差距,例如,在37.1 (Mask, Table 1)和39.8 (box, Table 3)之间有2.7个点,这说明我们的方法在很大程度上弥补了物体检测和更具挑战性的实例分割任务之间的差距。
4.4 Timing
推论:我们训练了一个ResNet-101-FPN模型,该模型在RPN和Mask R-CNN阶段之间共享特征。跟随Faster R-CNN【34】的4步训练。该模型在Nvidia Tesla M40 GPU上以195毫秒/幅的速度运行(加上调整输出到原分辨率的15毫秒CPU时间)。并在统计上获得与未共享的mask A P AP AP相同的mask A P AP AP。我们还报告了ResNet-101-C4变种需要大约400ms,因为它有一个更重的盒头(图3),所以我们不建议在实践中使用C4变体。
虽然Mask R-CNN速度很快,但我们注意到我们的设计并没有针对速度进行优化,并且可以通过改变图像大小和建议数来实现更好的速度/精度平衡。这超出了本文的范围。
训练: Mask R-CNN也是快速训练。在COCO trainval35k上使用ResNet-50-FPN进行训练,在我们的同步8-GPU实现中需要32小时(每16个图像小批次处理需要0.72秒),使用ResNet-101-FPN需要44小时。事实上,快速原型可以在不到一天的时间内完成在训练集上的训练。我们希望这样的快速训练将消除这一领域的一个主要障碍,并鼓励更多的人对这一具有挑战性的课题进行研究。
5. Mask R-CNN 人体姿态估计
我们的框架可以很容易地扩展到人体姿态估计。我们将一个关键点的位置作为一个one-hot mask,并采用Mask R-CNN来预测K个mask,每个有K个关键点类型(例如,左肩、右肘)。这个任务有助于说明Mask R-CNN的灵活性。
我们注意到我们的系统利用了人类姿态的最小领域知识。由于实验主要是为了证明Mask R-CNN框架的通用性。我们期望领域知识(例如,建模结构【6】)能够补充我们的简单方法,但这超出了本文的范围。
实现细节: 我们对分割系统做了一些小的修改,让它适应关键点。对于实例的每个K个关键点,训练目标是一个单一热点的 m × m m \times m m×m二进制掩码,其中只有一个像素被标记为前景。在训练过程中,对于每个可见的真实边界框的关键点,我们最小化了 m 2 m^2 m2-way 的softmax输出的交叉熵损失(它鼓励单一点的检测)。我们注意到,在实例分割中,K个关键点仍然是独立处理的。
我们采用了ResNet-FPN变体,关键点头架构类似于图3(右)。关键点头由8个3x3 512-d conv层叠加而成,接着是反卷积层和2倍双线性upscaling,输出分辨率为56 × \times × 56。我们发现对于关键点级别的定位精度,需要一个相对较高的分辨率输出(与掩码相比)。

图6.使用Mask R-CNN(ResNet-50-FPN)在COCO测试集上的关键点检测的结果,使用相同的模型预测人体分割mask。该模型的关键点 A P AP AP为63.1,运行速度为5帧/秒。
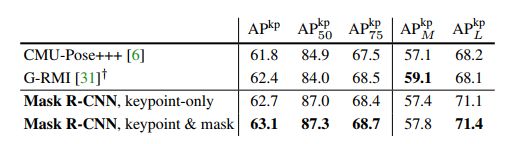
表4.在COCO测试集上的关键点检测 A P AP AP。我们的(ResNet-50-FPN)是一个单一的模式,运行在5 fps。CMU Pose+++[6]是2016年的比赛冠军,它使用了多尺度测试,CPM【39】的后处理和物体检测器的过滤,累计增加了5点(在个人交流中澄清)。G-RMI在COCO + MPII【1】(25k张图片)上训练,使用两个模型(inception- ResNet-v2 + ResNet-101)。当他们使用更多的数据,没有一个直接的与Mask R-CNN的比较。
模型在包含标记关键点的COCO trainval35k图片上训练。由于这个训练集更小,为了减少过拟合,我们随机采样[640,800]像素中的图像尺寸来训练模型,推理是在一个800像素的单一尺度上进行的。我们迭代了90k次来进行训练,从0.02的学习率开始,并在60k和80k迭代中将其减少10倍。我们使用了阈值为0.5的边界框非极大值抑制。其他实现与3.1相同。
人体姿态评估实验: 我们使用ResNet-50-FPN评估人体关键点AP( A P k p AP^{kp} APkp)。我们已经用ResNet-101做了实验,发现它得到了类似的结果,可能因为更深层次的模型受益于更多的训练数据,但是这个数据集相对较小
从表4可以看出,我们的结果(62.7 A P k p AP^{kp} APkp)比使用多级处理路径的,2016年COCO关键点检测冠军【6】高出0.9个百分点(如表4所示),我们的方法相当简单和快速。
更重要的是,我们有一个统一的模型,可以在5帧/秒的速度下同时预测框、分割和关键点。添加一个分割的分支(用于人体类别)提升 A P k p AP^{kp} APkp到63.1在test-dev。在minival上更多的多任务的消融学习如表5所示。在box-only中添加mask分支(例如,Faster R-CNN)或只是关键点,不断改进这些任务。但是,添加关键单分支会稍微减少box/mask的 A P AP AP,这表明虽然关键点检测可以从多任务训练中受益,但它并不能帮助其他任务。然而,联合学习这三个任务可以使一个统一的系统有效地同时预测所有的输出(图6)。
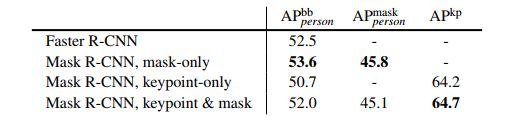
表5.多任务学习的box、mask和关于person类别的关键点,在minival上评估。所有的条目都训练在相同的数据上进行公平的比较。主干是ResNet-50-FPN。在minival上有64.2 A P AP AP的条目有62.7的 A P AP AP在test-dev上。在minival上有64.7的条目,有63.1的 A P AP AP在test-dev(如表4)

表6.ROIAlign vs RoIPool在minival上的关键点检测
我们还研究了RolAlign对关键点检测的影响(表6)。尽管这个ResNet-50-FPN主干有更大的进步(例如,在最细的级别上有4个像素),但RolAlign仍然比RolPool有显著的改进, A P k p AP^{kp} APkp提高了4.4个点。这是因为关键点检测对定位精度更敏感。这再次表明,对齐对于像素级定位的是非常重要,包括mask和关键点。
考虑到Mask R-CNN在提取对象边界框、mask和关键点方面的有效性,我们希望它能够成为其他实例级任务的有效框架。

A.城市景观的实验
我们进一步报告实例分割结果的在城市景观【7】数据集。这个数据集对2975个训练图像、500个验证图像和1525个测试图像有很好的标注。它有20k的粗糙训练图像,没有实例注释,我们不使用。所有图像的固定分辨率为2048x1024像素。实例分割任务包含8个对象类别,在精细训练集上的实例数量为:

实例分割任务的性能是通过COCO-style的mask A P AP AP (IoU阈值的平均值)来衡量的; A P 50 AP_{50} AP50(i.e.,mask AP的IoU值为0.5)也被报告。
实现: 我们应用我们的Mask R-CNN模型与ResNet-FPN-50主干,我们已经测试了101层的副本,发现由于数据集的比较小,它的性能类似。我们使用图像的尺寸(短边)从【800,1024】中随机的采样,这减少过拟合;推理是在1024像素的单一尺度上进行的。我们使用每一个GPU一个图像的小批次(因此在8个GPU上有效的8个),并训练迭代24k次,从0.01的学习率开始,在18k迭代时减少到0.001。其他实现细节与3.1相同。
结果: 表7将我们的结果与val和test 集上的最好的结果进行了比较。在不使用粗训练集的情况下,我们的方法在测试中获得了26.2的 A P AP AP,相对于使用细+粗标签的最佳条目,提高了30%以上。与仅使用细标签的最佳条目(17.4 AP)相比,我们获得了约50%的改进。在一个8-GUP的机器上上训练约4小时来获得这个结果。
对于人员和汽车类别,Cityscapes数据集显示了大量类别内重叠的情况(平均每个图像中有6个人和9辆车)。我们认为类内重叠是立场分割的核心难点。我们的方法显示这两个类别比现有的最佳条目有了巨大的改进(相对于人,从16.5到30.5提高了85%,相对于车,从35.7到46.9提高了30%)。
Cityscapes数据集的一个主要挑战是在低数据体制下的训练模型,特别是卡车、公共汽车和火车的类别,每个类别大约有200-500个训练样本。为了部分解决这个问题,我们进一步汇报使用COCO预训练的结果。为此,我们从一个预先训练的COCO Mask R-CNN模型(rider被随机初始化)中整理了Cityscapes中相应的7个类别。我们对4k迭代进行了微调,在3k迭代时降低了学习速率。它花费了一个小时在COCO上进行训练。
在测试上,COCO预训练的Mask R-CNN模型实现32.0的 A P AP AP,几乎有6 point 的绝对进步,相对于只有良好表现的对手。这说明了训练数据所起的重要作用。这也表明,城市场景的实例分割方法可能受到其低概率学习性能的影响。我们证明使用COCO预训练是一种有效的策略,可以减少涉及到该数据集的有限数据问题。
最后,我们观察到val和test A P AP AP之间存在偏差,这也可以从【23,4】的结果中观察到。我们发现,这种偏差主要是由卡车、公共汽车和火车类别造成的,纯微调模型的val/test A P AP AP分别是28.8/22.8,53.5/32.2,33.0/18.6。这表明,这些类别的领域发生了变化,它们也几乎没有培训数据。COCO预训练最有助于改善这些猫的训练效果;然而,定义域的偏移仍然是38.0/30,1。分别为57.5/40.9和41.2/30.9 val/test AP。请注意,对于人员和汽车类别,我们没有看到任何的偏差(Val/test A P AP AP在± 1 point)。
在Cityscapes上的结果被展示在Figure 7.