从Clickhouse 到 Snowflake(二): MPP 查询层
背景
进入 2021 年,伴随着 Snowflake 的成功,大大小小的创业公司不断创立,各种 OLAP 的开源产品层出不穷,Clickhouse 凭借优秀的性能在这其中脱颖而出,内部各种极致的优化,也被津津乐道,主要包括:
- 向量化思想,业界虽然很早就有向量化的理论,并且在各大公司的产品介绍中 LLVM、向量化、SIMD 这些光鲜的名词也屡见不鲜,但是 Clickhouse 第一次把向量化这项技术在一个系统中做到极致,并被广泛使用,通过一个工程实践证明了向量化在 OLAP 系统内靠谱、可行。
- 高质量的工程实现,数据库是一个系统工程,再好的理论也需要优秀的工程实现才能交付优秀的性能。Clickhouse 把工程实现做到了极致,比如大量的使用模板技术来减少分支预测;Processor 执行框架实现各个算子的异步执行,同时兼顾 CPU Cache 的命中率。相信每个看过 Clickhouse 源码的人都会感叹“原来还可以这么用!”。此外,Clickhouse 的编译依赖做的也非常棒,它把所有的依赖都以源码的形式引入到项目中从头编译,不需要用户下载任何其他第三方依赖,编译完之后是一个完整的、没有任何依赖的二进制库。
毫无疑问 Clickhouse 是一款追求性能极致的产品,但是在使用过程中我们发现它在功能和易用性上离通用的数仓(如 Vertica,Greenplum 等)还有一些差距,主要包括:
- 功能不足,多表 Join 支持差,用户一般需要使用大宽表;复杂的聚合容易 OOM;缺少查询优化器的支持,用户需要手动调优;
- 兼容性不好,对 SQL 标准兼容弱,缺少一些常见的 SQL 语法支持,比如没有 SQL 相关子查询,这样很多现有工具不能直接使用,比如业务原来基于 MySQL 做 BI 报表,如果想迁移到 Clickhouse 上,语法得改写,数据得重新建模。
- 易用性差,查询分为本地表查询和分布式表查询,比如在 Colocate Join 下用户就需要使用本地表,不易用。
为了打造一个媲美 Snowflake 的云原生数仓,为 Clickhouse 增加一个功能强大的的分布式查询层是我们必须要迈过的一道坎。
架构设计
增强 Clickhouse 的分布式查询能力,主要考虑过以下两种方案:
- 方案一,改进现有的查询层,在现在查询层的基础上,增加更多的 SQL 语法支持来兼容 SQL 标准,嵌入实现一个查询优化器,完善现有的数据 Shuffle 逻辑等。这种方式可以复用 Clickhouse 当下优秀的计算能力,但是实现上想在不侵入 Clickhouse 源码的前提下改进扩充非常难,比如 Clickhouse 纯手工打造的 SQL 解析器,想增加一条 SQL 就需要改动很多模块。
- 方案二,实现一个全新的查询层,把 Clickhouse 完全当做单机引擎来用,查询层独立于 Clickhouse,这样分布式查询层可以单独发展,不至于跟 Clickhouse 社区割裂。
与 Clickhouse 社区协同发展是保持产品生命力的重要方式,所以我们选择了方案二,架构如下图所示:
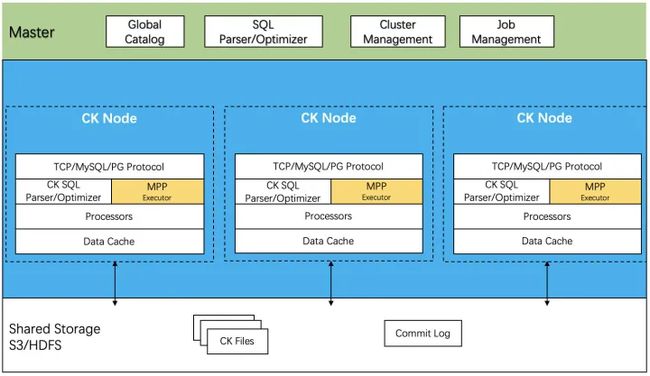
- Master 节点,这个跟存算分离架构中的 Master 节点是一体的,由于在存算分离中,所有的 DDL 语句的执行都是通过 Master 节点来调度执行的,所以 Master 节点在执行 DDL 任务的过程中通过解析 DDL SQL 建立了全局一致的 Catalog; Master 节点内部还包括一个 SQL 优化器,来生成高效的物理查询计划;
- CK 节点, 在 Processor 的执行框架之上,增加了一个 MPP 模块,用来实现一套功能强大的分布式 MPP 查询层;
- 共享存储,实际的数据文件和 CommitLog 文件都存放在对象存储中,对象存储目前仅支持腾讯云对象存储 COS,这部分在存算分离相关文章中有介绍。
在该架构下,查询的执行流程如下图所示:
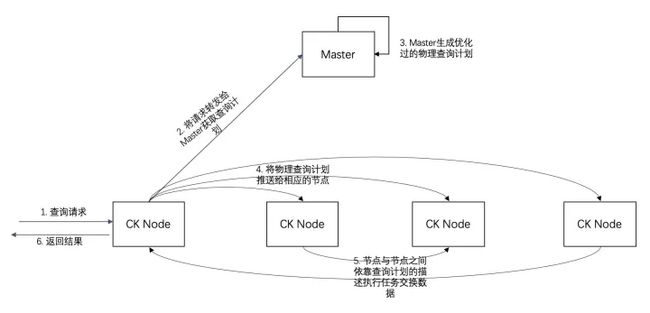
- 用户可以随意连接一个 Clickhouse 节点,发送 SQL 语句;当前这个 Clickhouse 节点作为本次查询的 Initiator,把查询转发给 Master;
- Master 节点根据 Catalog 中的 Schema 做查询 SQL 的解析,根据数据分布来生成物理查询计划;
- Initiator 拿到物理查询计划之后,分发给对应的 Clickhouse 节点执行;
- 各个 Clickhouse 节点通过 MPP 执行模块完成分布式查询的执行,包括调用 Clickhouse 的 Processor 扫描数据, 跟其他节点进行数据交换,执行各种算子(例如 Join,Agg 等);
- 最终的结果返回给 Initiator,Initiator 把结果根据不同的协议进行格式化,返回给客户端;
整个查询的执行过程中,数据流不经过 Master 节点,降低 Master 节点的压力;Master 单节点可以支撑万级 QPS 的查询解析请求,由于 Master 节点多副本,所以可以通过集群的方式进行线性扩展。
资料领取直通车:Golang云原生最新资料+视频学习路线 https://docs.qq.com/doc/DTllySENWZWljdWp4
https://docs.qq.com/doc/DTllySENWZWljdWp4
Go语言学习地址:Golang DevOps项目实战https://ke.qq.com/course/422970?flowToken=1043212
核心特性
功能强大的 MPP 计算引擎
Clickhouse 的执行框架是一个简单的两阶段执行框架(Scatter Gather 模型),Scatter 任务可以由多个节点来完成,Gather 任务只有一个节点来完成,所以它不能执行复杂的查询,比较适合大宽表。
而业界典型高性能查询引擎使用的 MPP 计算框架是一个多阶段的执行框架,一条复杂的 SQL 语句被拆解为多个计算算子,每个计算算子可以分布到多个计算节点上并行完成,计算节点之间通过 RPC 完成数据交换,并以 Pipeline 的方式高效执行。
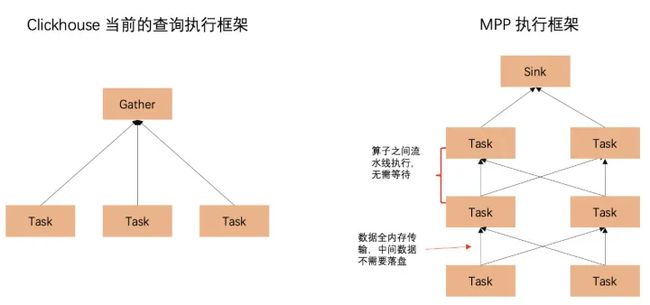
下面可以通过大宽表上的一个简单查询来看一下两者之间的区别,SQL 语句如下:
SELECT age,count(distinct uid) from user_info group by ageClickhouse 的执行流程如下:
- Scatter 阶段 :Initiator 节点向各个 Shard 发送查询,要求其返回执行到 WithMergeableState 的结果,该阶段包含聚合逻辑的前半部分,相同 Key 已在哈希表中聚合,Value 仍保持可聚合的中间状态。该中间状态可以被序列化(Clickhouse 特色的中间结果^-^),并返回给 Initiator。
- Gather 阶段 :Initiator 继续执行聚合逻辑的后半部分,将相同 Key 的所有中间状态合并,并转换成最终的值。合并过程只能在单点完成。
MPP 框架的执行流程如下图所示:
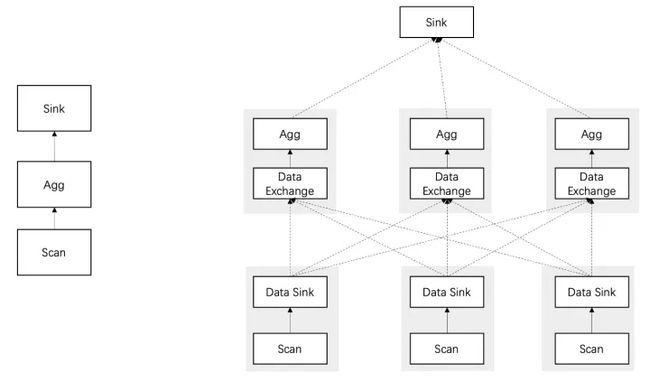
这个查询语句被规划为 3 个阶段, 扫描数据, 聚合计算,返回结果;每个阶段又会被拆分为多个子任务,例如这个查询就被拆分为 7 个任务。
- 阶段一:3 个节点同时执行 Scan 任务,每个任务执行完之后,把数据根据 Age 字段 Hash 分桶,分别发送给 3 个不同的 Agg 任务;
- 阶段二:3 个 Agg 任务根据收到的数据,按照 Age 来做 Group by 计算,把结果发送给 Sink 任务;
- 阶段三:Sink 任务收到的数据已经是聚合好的,所以可以直接对数据进行简单的 Merge,然后返回给客户端。
与 Scatter-Gather 模型相比,上述聚合计算被分配到多个节点上并行执行了,不仅仅可以加快速度,还可以降低内存的使用,避免内存不足。
在具备通用的 MPP 执行框架之后,已经可以跑通 Join 等大多数复杂查询,后续通过查询优化器合理的查询规划,可以进一步提升复杂查询的性能,基于代价的查询优化器(CBO)正在研发中,预计下一个版本发布。
内存零拷贝、全链路向量化的 MPP 实现
业界有很多 MPP 查询引擎的实现,比如 Impala,Presto,Spark 等,我们看到很多公司也在尝试将这些查询引擎对接 Clickhouse,从而让 Clickhouse 具备 MPP 执行的能力,但是从调研分析看,这种方式有以下缺陷:
- 数据传输开销大,Clickhouse 作为存储层与查询层在两个服务进程中(非混部场景中,在两台机器上),数据的传输需要序列化和反序列化,跨网络或者单机多进程之间传输,开销比较大;
- Clickhouse 相比其他 OLAP 系统很大的优势在于它向量化的思想以及高质量的工程实现,当查询层交由别的系统来实现之后,Clickhouse 就只剩下单机的扫描能力,强大的查询能力就发挥不出来了。
而 Clickhouse 最大的优势就是快,这种整合方式会让 Clickhouse 丧失这个优势,产品竞争力就会下降,而且交付给客户的是一个多个组件构成的“全家桶”,使用起来也复杂。所以我们抛弃了这种方式,选择在 ClickHouse 同进程内、Processor 执行框架之上实现 MPP 查询层,如右下图所示:
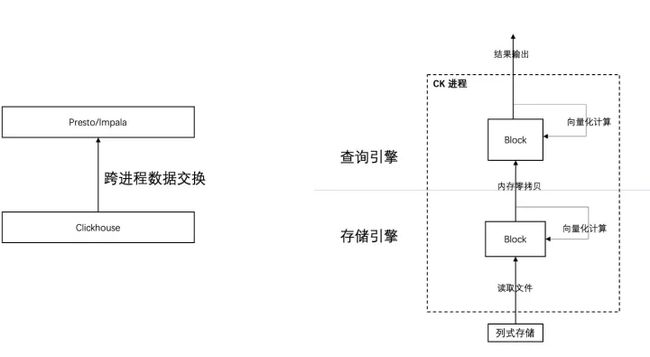
方案的整体思路及优势如下:
- MPP 计算层跟 Clickhouse 在同一个进程内,不需要序列化传输数据;
- MPP 计算层也是用 Block 作为内存数据格式,与存储层之间的数据交换不需要内存拷贝,进一步减少开销。
- MPP 计算层在 Block 的内存结构之上,复用 Clickhouse 的向量化计算的算子,达到跟 Clickhouse 同样的性能;
- MPP 计算层把简单的函数表达式计算、过滤等算子全部下推给 Clickhouse 完成,未来单表上的聚合也会下推给 Clickhouse,充分利用 Clickhouse 的索引、统计信息、并行聚合等优势能力;
这种设计在兼容开源、保持简洁的同时,尽可能做到零序列化、零拷贝,并充分复用 ClickHouse 的向量化算子等能力,保持 ClickHouse 的最大优势 “快”。
兼容 SQL 标准 与 MySQL 连接协议
- 充分利用当前的 SQL 与 MySQL 生态,应用程序无需修改即可切换到 Clickhouse 服务上,享受 Clickhouse 带来的极速的分析能力。
- 目前我们已经能够在不需要改造大宽表模型下,完全跑通 TPC-H 的所有测试语句,TPC-DS 标准也支持了 90%以上。例如 TPC-H Q21 这种复杂的多表 Join 和子查询场景:
select
s_name,
count(*) as numwait
from
supplier,
lineitem l1,
orders,
nation
where
s_suppkey = l1.l_suppkey
and o_orderkey = l1.l_orderkey
and o_orderstatus = 'F'
and l1.l_receiptdate > l1.l_commitdate
and exists (
select
*
from
lineitem l2
where
l2.l_orderkey = l1.l_orderkey
and l2.l_suppkey <> l1.l_suppkey
)
and not exists (
select
*
from
lineitem l3
where
l3.l_orderkey = l1.l_orderkey
and l3.l_suppkey <> l1.l_suppkey
and l3.l_receiptdate > l3.l_commitdate
)
and s_nationkey = n_nationkey
and n_name = 'SAUDI ARABIA'
group by
s_name
order by
numwait desc,
s_name
limit 100;
- 能够支持了常见的 BI 工具,例如业界排名第一的 Tableau,用户可以选择 MySQL 连接,直接当做 MySQL 来使用即可。如下图所示:
持续兼容开源生态
在实现 MPP 查询引擎时,我们仍然遵循着不侵入 Clickhouse 源码的原则,把 Clickhouse 当做一个单机的库,如下图所示:

- 在底层,我们用存算分离替换了 Clickhouse 的本地存储;
- 在上层用 MPP 查询层替换了 Clickhouse 当前的查询框架;
- 此外在周边我们利用 Clickhouse 的 SQL 命令实现了全新的分布式 DDL 框架;
- 屏蔽 Local 表的导入功能正在研发中。
这种架构使得后续的版本升级更加方便,能够随时合并 Clickhouse 社区的最新功能。
兼容开源生态的另外一个方面是新系统允许用户在 MPP 查询引擎和现有的查询引擎之间切换,用户可以通过一个 Setting 完成,如下所示:
SET use_mpp_engine = true用户可以在新场景里使用 MPP 查询引擎,逐步的把 Clickhouse 目前的查询语法废弃,平滑的升级到新的查询引擎,未来我们也会在 MPP 查询引擎中兼容 Clickhouse 的 SQL 语法标准,让用户的迁移更便利。
未来工作
- 本地 Cache 优化,存算分离架构中本地 Cache 实现的好坏对性能有决定性影响,这是我们近期要重点攻克的地方。这部分完成后,我们会发布正式的性能测试报告。
- CBO 查询优化器,这是执行复杂查询必备的一个组件,目前我们正在开发中,预计明年上半年上线。
- 多数据源支持,在 OLTP、对象存储、Elasticsearch、MongoDB 等系统中,存在大量数据需要进行深入分析。借助 Clickhouse 当前的多数据源能力,支持对多数据源、结构化/半结构化数据的统一分析。
- 简单完全的分布式化,消除节点、Shard 等用户概念,给用户暴露一个高度抽象、类单机的分布式系统,屏蔽底层的实现细节,降低用户的使用负担或顾虑。