java内存区域篇:
1.运行时数据的分区,为什么要分区呢?
- 程序计数器、栈、方法区、堆 是干啥的?
- 程序计数器:程序怎么知道下一行该执行哪
- 栈:方法的开始执行和栈有什么关系,为什么方法在栈帧分配多大的空间是一直的(因为局部变量表里存放了编辑期间可知的数据类型)
- 堆:意义,对一定要是连续空间吗(肯定不是啊,如果是的话new对象还有啥意义呢,直接都是静态好了),新生代老年代怎么划分的(年龄,熬过一次gc加一岁)
- 方法区:常量、静态变量都在这,这俩都是gc root的起点,所以方法区一般也不会去做垃圾回收,因为效率不高,还特么费劲。
- 运行时常量池:编辑期间的生成的各种字面量(int i = 1 这个1就是字面量)就在这,符号引用(String s = “123” s就是符号引用)也存在这里。
2. 创建的对象的过程。
- 首先确认一点,类得先初始化了,可以从常量池中看看能不能定位到符号引用,如果不能就先类初始化,如果能 就开始对象初始化。
- 对象初始化三部曲,1.开辟空间 2.初始化对象A 3.对象头添加引用地址 完事儿。
** 详细描述一下:**
1.开辟空间:从堆中找一块空间,这个分配方式可以用指针碰撞或者空闲链表,取决于内存的规整程度,规整程度取决于垃圾回收算法,服务端大部分G1,Android 是 cms。
2.新生对象分配内存,对象的大小在类加载完就知道了(简单说就是从堆中找了一块地方)
3.把分配的内存空间都初始化为0,为了保证对象的实例不赋初值就能用
4.将对象引用指向指向这区域
3.对象内存布局是啥
三个区域:对象头、实例对象、对其填充
对象头:存储自身的一些数据,Gc年龄、哈希code,类型指针确定是哪个的类
4.对象的访问定位
直接指针 和 句柄池
5.为啥不能无限开启线程呢
线程的栈分配越大,反而越容易内存溢出。从操作系统入手,os给进程的空间是优先的,虚拟机系统提供了参数去指定堆、方法区的大小,程序计数器呢有不消耗内存,所以分配到每个线程的栈越大,可建立的线程数量就越少。
6. 栈的为啥不用gc
因为它的生命周期和线程相同。
7.为啥堆需要Gc
多个实现类需要的内存可能不一样,而且只有在程序运行期间才能知道创建哪些对象,所以需要对内存进行回收。如果不gc都创建成静态岂不是更快更好,主要还是空间效率的问题。
8.String Str = “a” 做了什么 ?string +=“b”呢
首先String Str = “a” 是生命了一个string类型的对象,值为‘a’,然后str句柄指向了对象“a”的这块空间。 在+=的时候,又创建了一个string对象,指向现在的“ab”,再让指向“a”的这个失去引用,最后被Gc。
9.string str = “a” + “b”
string类型的 “a” 和 “b” 是存在常量池的(编辑期间完成),所以在str直接指向的“ab”
垃圾收集器和内存分配策略:
概念:
垃圾收集器是针对堆的,因为程序计数器、栈、是线程私有,随着线程的创建而生,毁灭而亡,所以不涉及垃圾回收。栈中的栈帧入栈出栈代表着方法的开始与销毁,没个栈帧分配多少内存基本上在类结构确定的时候就定下来了,不需要针对栈进行垃圾回收。
1.如何判断对象可回收:
引用计数和可达性分析:
引用计数法:当前的对象有引用+1,撤销引用-1,方便快捷,但解决不了循环引用的问题。
可达性分析:以GcRoot为起点,往下搜索,路径称为引用链,不在这个引用链上的回收,完美解决循环引用的问题。 目前常用这个。
gcroot:
- 虚拟机栈中引用的对象,因为栈帧在方法执行完后出栈,栈内的对象在生命周期内算是生命周期比较长的,所以可以作为gcroot
- 方法区的静态变量引用的对象
- 方法区中常量引用的对象。
2.常见的对象引用:
强:gc不被回收,直接 new 的对象都是强引用。
软:在内存不足的情况下,gc 会回收
弱:只要 gc 就能回收
虚:虚无缥缈,啥时候被回收的都不知道,想回收就回收。
3. finalize的存在对象不会直接被回收:
真正确立对象的死亡要经过两个阶段,被gc的对象第一次标记后将会被放入F-queue队列中,稍后gc将对队列中进行小规模标记,只要和引用链重新确立引用关系,就不会被回收。
4.方法区的回收:回收废弃常量 和 无用的类。(GC可选择不回收)
无用的类判别:该类的实例都被回收,java堆中没有该类的实例。加载该类的classload已经被回收。对象没有在任何地方被引用。
5.常见的垃圾收集算法:
- 标记-清楚算法:首先标记出需要清理的对象,然后清理标记的对象。过程简单,但是会在内存空间产生大量不连续的碎片。
- 复制算法:针对新生代而生,把内存分成相等的两块,当一块用完之后把活着的对象移到另一块内存上,在把使用过的内存一次性清除。 因为大部分对象都是朝生夕死,所以预留区没必要那么大。新生代 老年代 预留区 比值一般为8:1:1 的关系。
- 标记-整理算法:针对老年代而生,避免复制算法的频繁移动对象。标记可回收对象,让活着的对象往一边移动,集中清理可回收的对象。
6.常见的垃圾收集器:
- serial收集器:顾名思义,串行垃圾回收器。在它进行垃圾收集的时候其他工作的线程都要停止工作,著名的“stop the world”就出在这里。
- pernew收集器:新生代收集器,基于复制算法。和serial没啥区别,是个多进程版本,能配合cms工作。
- parallel 收集器:新生代、复制算法。目标是吞吐量,增加cpu的利用率。适合后台大量的数据处理,而不需要太多交互的场景。
- cms收集器: 基于标记清楚算法。获取最短垃圾回收时间为目标,服务端常用(Android 就是使用这个)。四个步骤: 初始标记(单线程,找gcroot能直接关联的对象),并发标记(顺着gcroot向下继续标记),重新标记(单线程,解决并发标记期间用户操作引起的变动),并发清楚。
cms缺点也很明显:对cpu资源比较敏感:在并发阶段,虽然不会导致用户线程的停顿,但是会占用线程资源导致程序变慢。cms默认启动的回收线程数量是 (cpu+3)/ 4。 cms也没有办法处理浮动垃圾,而且还是基于 标记-清除算法 会有大量不连续碎片。 - g1:内容较多,但是开一章
7. 内存分配与回收策略:
两个概念:full GC 和 minor Gc。 大对象直接进入老年代,长期存活的对象进入老年代(依靠年龄计数器判别),动态对象年龄判别(当 survivor 空间中相同年龄所有对象的总和大于survivor空间的一半,那这些对象直接进入老年代)
虚拟机类加载机制
概念:类型的加载、初始化都是在程序运行期间完成的(为了灵活性)
类加载的机制: 虚拟机把描述类的数据从class文件加载到内存,并对数据进行校验,转换解析和初始化,最终形成可以被虚拟机直接使用的java类型,这就是jvm的类加载机制。
加载 -> 验证 -> 准备 -> 解析 -> 初始化-> 使用 -> 卸载.
类必须加载的情况:
- 遇到new关键词的时候,读取或设置一个类的静态字段(被final修饰的不行,因为在编译期就把变量放入了常量池)
- 反射
- 初始化一个类的时候,如果父类没被初始化,先初始化父类。
类不会被初始化的集中情况
- 通过子类引用父类的静态字段,不会导致子类的初始化
- 通过数据定义引用类,不会触发类的初始化
- 常量在编译期间会存入调用类的常量池,本质上并没有直接引用到定义常量的类。
类的加载过程
- 加载:通过一个类的全限定名来获取定义此类的二进制字节流,在内存中生成一个代表这个类的java.lang.class对象,作为方法区这个类的各种数据的访问入口。
- 验证:要保证class文件的字节流中符合虚拟机的要求,不会危害虚拟机自身的安全。
- 准备:这个阶段是为类变量复制(都是在方法区中赋值),内存分配进包括类变量(被static修饰的变量)。实例变量在对象实例化的时候随着对象一起分配在java堆中。
pubic static int values = 123;
变量values 在准备阶段的值为0,而不是123. - 解析:将符号引用替换成直接引用
- 初始化:在准备阶段,某些变量已经赋值过一次初始值,在初始化阶段是根据开发者的意思去赋值。
类加载器
概念:加载阶段的动作方法java虚拟机外部去实现。
类相等的条件:一定是同一个类加载器加载,因为每一个类加载器都有一个独立的命名空间。
双亲委派模型
类加载器分为:1. 启动类加载器(加载lib目录下的文件,开发不用) 2.扩展类加载器(lib/ext 下的文件) 3. 应用程序类加载器(默认使用) 4. 自定义类加载器
概念:如果一个类加载器收到了类加载的请求,它首选不会去尝试加载这个类,而是把这请求委派给父类的类加载器去完成,当父类加载器加载不了的时候,子类加载器才会尝试自己去加载。
类加载器的好处:因为类加载器不同,就算同一个class文件也不是不同的类(不同类加载器,命名空间是不同的),双亲委派保证了类的统一性。
早期编译优化
概念:编辑期一般是指一个前端编译器把.java文件编译成.class文件的过程。
编译过程大概分为三个阶段:
- 解析与填充符号表过程
语法分析:将代码的字符流转变为标记(token)集合,单个字符是程序编写的最小元素,而标记则是编译过程中的最小元素,关键字,变量名,字面量,运算符都是标记。如 int a = b + 2 中 int、a、=、b、+、2都是标记,一共六个。 - 插入式注解处理器的注解处理过程
在jdk1.5之后,java语言提供了对注解的支持,这些注解与普通的java代码一样,都是在运行期间发挥作用。可以把注解理解成编译器插件,在这些插件里面,可以读取、修饰,添加抽象语法树中的任意元素。如果语法树修改了,编译器将回到解析及 - 分析与字节码生成过程填充符号表阶段。
就是把上面说的转换成最终的字节码,写到磁盘
泛型与类型擦除
- 在1.5之前hashmap的get方法返回值就是一个object对象,由于java中语言里面所有的类型都是继承于object,那只有程序员和运行期间的虚拟机才能知道object具体是啥。在编译期间无法得知。
- java语言中的泛型则不一样,它只在程序源码中存在,在编译后的字节码文件中,就是原来的object类型,所以对于运行期间的java语言来说,arrayList
和 ArrayList 就是同一个类,java语言中的泛型实现方式成为泛型擦除。 - 方法重载要求方法具备不同的特征签名,返回值并不包括在方法的特征签名之中,所以返回值不参与重载,但是在class文件中,只要描述符不是完全一致的两个方法就可以共存。
例如:
// 这两个方法在同一个类中不能共存。
public void a(ArrayList mList){
log.i("zdf","");
}
public void a(ArrayList mList){
log.i("zdf","");
}
// 这两个方法时可以的
public void a(ArrayList mList){
log.i("zdf","");
return “”;
}
public void a(ArrayList mList){
log.i("zdf","");
return 1;
}
Java内存模型
目的:屏蔽掉各种硬件和操作系统的内存差异。
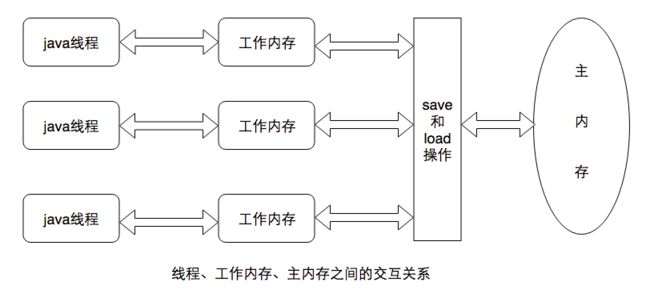
涉及到的变量有:实例字段、静态字段和构成数组对象的元素,但是不包括局部变量(局部变量是线程私有)。
描述 :java内存模型规定了所有的变量都存储在主内存中,每条线程都有自己的工作内存,线程对变量的所有操作都必须在工作内存中完成,不能直接读写主内存。但线程间的变量值传递需要从主内存中读取。
模型图(取自网络资源):
volatile的作用
概念:它是一个轻量级的同步机制。它保证了两点:
- 可见性:对所有线程的可见性,这个可见性是指当一条线程修改了变量值,另一个线程可以立即得知。普通的修改一个变量值做不到这一点(例如线程A修改了一个普通变量的值,然后向主内存回写,另外一条线程B在线程A回写完之后再从主内存进行读取操作,新的值才会对b可见。)
- 防止执行重排:指令重排序
Java语言规范JVM线程内部维持顺序花语义,即只要程序的最终结果与它顺序化情况的结果相等,那么指令的执行顺序可以与代码逻辑顺序不一致,这个过程就叫做指令的重排序。
指令重排序的意义:使指令更加符合CPU的执行特性,最大限度的发挥机器的性能,提高程序的执行效率。
volatile修饰为什么不一定是线程安全的:
因为每次使用之前都需要刷新主存中最新的值,所以它拿到的是当前时刻最新的,但如果有其他线程在之后又修改了这个值,那一次获取的值就不是最新的了。
理解有序性、可见性、原子性
1.顺序性,顾名思义,就是必须保证程序是按照你所预想的逻辑执行的。
- 可见性,写入缓存与从缓存读出是一个完整的动作,保证变化的值即时可见。这是volatile能保证的。
- 原子性,保证一个处理(或一段代码)不被打断地执行完毕,这是原子性。
线程安全与锁优化
线程安全概念:多个线程访问同一个对象的时候,依旧能的到想要的结果,且线程不会死锁,就是线程安全。(final修饰的一定是线程安全)
锁优化
- 自旋锁:如果物理机有一个以上的处理器,能让两个或以上的线程同时并发执行。就可以让后面的锁等待且不放弃处理器的执行时间,达到避免线程切换的开销。如果锁被占用的时间很短,自旋等待的效果就非常好,如果锁占用时间很长,那么自旋的线程只会浪费资源。
- 锁消除:对待不可能发生冲突的变量进行锁消除。如果当前堆上的数据都不会逃逸出去被其他线程访问到,那么就可以把他当做栈上的资源对待。
Ps:逃逸分析的基本行为就是分析对象动态作用域:当一个对象在方法中被定义后,它可能被外部方法所引用,例如作为调用参数传递到其他地方中,称为方法逃逸。
总结:就是当前方法内的某变量能被外部引用了,那就是产生了逃逸。 - 偏向锁:偏向于第一个获得线程,如果接下来在执行的过程中,该锁没有被其他的线程获取,则持有偏向锁的线程永远不需要再同步
乐观锁、悲观锁、可重入锁、公平锁等概念:https://blog.csdn.net/qq_34805255/article/details/101508048
- java接口中定义的变量其实都是常量。
- 静态类为什么不用 new 出来
最大的区别在于内存。
静态方法在程序开始时生成内存,实例方法在程序运行中生成内存,
所以静态方法可以直接调用,实例方法要先成生实例,通过实例调用方法,静态速度很快,但是多了会占内存。
任何语言都是对内存和磁盘的操作,至于是否面向对象,只是软件层的问题,底层都是一样的,只是实现方法不同。
静态内存是连续的,因为是在程序开始时就生成了,而实例申请的是离散的空间,所以当然没有静态方法快,
而且静态内存是有限制的,太多了程序会启动不了。 - 为什么区分基本类型和引用类型
引用类型在堆里,基本类型在栈里。
栈空间小且连续,往往会被放在缓存。引用类型*** miss率高且要多一次解引用。
对象还要再多储存一个对象头,对基本数据类型来说空间浪费率太高