样本不均衡问题
文章目录一瞥
-
- 什么是样本类别分布不均衡?
- 样本类别分布不均衡导致的危害?
- 解决方法:
-
- 1.通过过抽样和欠抽样解决样本不均衡
-
- (1)过抽样(over-sampling):通过增加分类中少数类样本的数量来实现样本均衡,比较好的方法有SMOTE算法。
- (2)欠抽样(under-sampling):通过减少分类中多数类样本的数量来实现样本均衡
- 2.通过正负样本的惩罚权重解决样本不均衡
-
- (1)带权值的损失函数:
- (2)难例挖掘
- (3)Focal loss
-
- python 实现focal loss
- 3.类别均衡采样
-
- Thresholding
- Cost sensitive learning
- One-class分类
- 集成的方法
- 使用其他评价指标
- 如何选择
- 参考文献
今天学习了关于样本类别分布不均衡的处理的一些知识,在此和大家一起分享一下。
什么是样本类别分布不均衡?
举例说明,在一组样本中不同类别的样本量差异非常大,比如拥有1000条数据样本的数据集中,有一类样本的分类只占有10条,此时属于严重的数据样本分布不均衡。
样本不均衡指的是给定数据集中有的类别数据多,有的数据类别少,且数据占比较多的数据类别样本与占比较小的数据类别样本两者之间达到较大的比例。
样本类别分布不均衡导致的危害?
样本类别不均衡将导致样本量少的分类所包含的特征过少,并很难从中提取规律;即使得到分类模型,也容易产生过度依赖与有限的数据样本而导致过拟合问题,当模型应用到新的数据上时,模型的准确性会很差。
解决方法:
- 数据层面:采样,数据增强,数据合成等;
- 算法层面:修改损失函数值,难例挖掘等。
- 分类器层面:
1.通过过抽样和欠抽样解决样本不均衡
采样
随机过采样:从少数类样本集中随机重复抽取样本(有放回)以得到更多的样本;
随机欠采样:从多数类样本集中随机选择较少的样本(有放回/无放回);
随机采样的缺点
过采样对少数样本进行了复制多份,虽然扩大了数据规模,但是也容易造成过拟合;
欠采样中丢失了部分样本,可能损失有用的信息,造成模型对某些特征的欠拟合
(1)过抽样(over-sampling):通过增加分类中少数类样本的数量来实现样本均衡,比较好的方法有SMOTE算法。
1. 基础版本的过采样:随机过采样训练样本中数量比较少的数据;缺点,容易过拟合;
2. 改进版本的过采样:SMOTE,通过插值的方式加入近邻的数据点;
3. 基于聚类的过采样:先对数据进行聚类,然后对聚类后的数据分别进行过采样。这种方法能够降低类间和类内的不平衡。
4. 神经网络中的过采样:SGD训练时,保证每个batch内部样本均衡。
SMOTE算法:简单来说smote算法的思想是合成新的少数类样本,合成的策略是对每个少数类样本a,从它的最近邻中随机选一个样本b,然后在a、b之间的连线上随机选一点作为新合成的少数类样本。具体的过程大家可以自行google。
附上代码示例:(首先展示示例数据,本篇文章都用此数据)
import pandas as pd
from imblearn.over_sampling import SMOTE #过度抽样处理库SMOTE
df=pd.read_table('data2.txt',sep=' ',names=['col1','col2','col3','col4','col5','label'])
x=df.iloc[:,:-1]
y=df.iloc[:,-1]
groupby_data_orginal=df.groupby('label').count() #根据标签label分类汇总
- 1
- 2
- 3
- 4
- 5
- 6
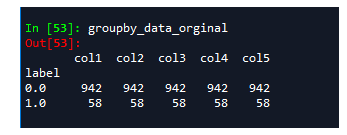
用groupby可以看到该数据label=0的有942个样本,label=1的只有58个,存在严重的不均衡现象,在这里我们用SMOTE算法来解决一下。
model_smote=SMOTE() #建立smote模型对象
x_smote_resampled,y_smote_resampled=model_smote.fit_sample(x,y)
x_smote_resampled=pd.DataFrame(x_smote_resampled,columns=['col1','col2','col3','col4','col5'])
y_smote_resampled=pd.DataFrame(y_smote_resampled,columns=['label'])
smote_resampled=pd.concat([x_smote_resampled,y_smote_resampled],axis=1)
groupby_data_smote=smote_resampled.groupby('label').count()
- 1
- 2
- 3
- 4
- 5
- 6

(2)欠抽样(under-sampling):通过减少分类中多数类样本的数量来实现样本均衡
与过采样方法相对立的是欠采样方法,主要是移除数据量较多类别中的部分数据。这个方法的问题在于,丢失数据带来的信息缺失。为克服这一缺点,可以丢掉一些类别边界部分的数据。
from imblearn.under_sampling import RandomUnderSampler
model_RandomUnderSampler=RandomUnderSampler() #建立RandomUnderSample模型对象
x_RandomUnderSample_resampled,y_RandomUnderSample_resampled=model_RandomUnderSampler.fit_sample(x,y) #输入数据并进行欠抽样处理
x_RandomUnderSample_resampled=pd.DataFrame(x_RandomUnderSample_resampled,columns=['col1','col2','col3','col4','col5'])
y_RandomUnderSample_resampled=pd.DataFrame(y_RandomUnderSample_resampled,columns=['label'])
RandomUnderSampler_resampled=pd.concat([x_RandomUnderSample_resampled,y_RandomUnderSample_resampled],axis=1)
groupby_data_RandomUnderSampler=RandomUnderSampler_resampled.groupby('label').count()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

2.通过正负样本的惩罚权重解决样本不均衡
(1)带权值的损失函数:
简单粗暴地为小样本标签增加损失函数的权值,加权之后可以简单地理解是:对于小样本一个数据顶多个使用,这里的多就是我们要设置的权值,有点类似于对小样本数据进行了过采样的操作;
(2)难例挖掘
难例挖掘:指的就是挖掘出模型预测效果较差的样本,模型预测效果较差即就是在难样本上的预测损失函数值很大,挖掘出这些难训练的样本,然后对这些样本再进行重新训练等。
想一想为什么这个可以部分解决样本不均衡的问题呢?
其实,很简单的可以理解这个方法为什么可以work,难例挖掘,对于我们的小样本数据,模型的预测效果可想而知肯定预测的不好啦,预测的不好,那么不就会被挖掘出来当作难例了吗?模型对这些样本再次处理,对小样本数据就有了特殊的待遇,有种成绩不好的学生被老师带到办公室再学习的感觉,那么成绩不好的学生怎么说也会有点提高吧,模型不也就能够相应的提高performance了!
(3)Focal loss
focal loss 出自于论文Focal Loss for Dense Object Detection
具体的讲解可以去看这篇文章:https://zhuanlan.zhihu.com/p/32423092
此处简单介绍一下:focal loss在原来带权值的loss函数的基础上进行了改进,改进的方向也是损失函数的权值。
再瞅一眼二分类交叉熵损失函数的表达式:
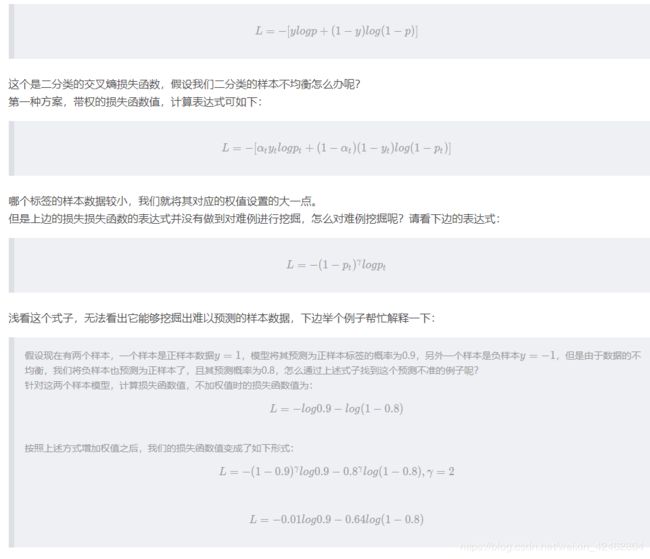
按照上述例子,是否发现我们对于预测错误的样本的损失函数值的权值相比预测正确的权值大了很多,原始两者比例是1:1,现在的比例是1:64,相当于对于预测错误的样本,我们对其处理是权值增加了63倍。
这种对损失函数修改权值的方法,是依据概率而修改的,不像直接修改损失函数的权值,直接修改显得有些生硬。
记住到这里我们挖掘出来的是预测错误的,而没有针对数据不平衡进行操作(当然数据不平衡也会导致预测错误),我们继续对损失函数加上权值,此时的权值就是对类别不平衡的处理,表达式如下:
python 实现focal loss
def focal_loss(labels, logits, gamma, alpha): labels = tf.cast(labels, tf.float32) probs = tf.sigmoid(logits) ce_loss = tf.nn.sigmoid_cross_entropy_with_logits(labels=labels, logits=logits) alpha_t = tf.ones_like(logits) * alpha alpha_t = tf.where(labels > 0, alpha_t, 1.0 - alpha_t) probs_t = tf.where(labels > 0, probs, 1.0 - probs) focal_matrix = alpha_t * tf.pow((1.0 - probs_t), gamma)loss = focal_matrix * ce_loss loss = tf.reduce_mean(loss) return loss
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
**
算法思想:对于分类中不同样本数量的类别分别赋予不同的权重,一般是小样本量类别权重高,大样本量类别权重低。**
这里以SVM为例:
from sklearn.svm import SVC
model_svm=SVC(class_weight='balanced')
model_svm.fit(x,y)
- 1
- 2
- 3
这里的class_weight选项用其默认方法‘balanced’,即SVM会将权重设置为与不同类别样本数量呈反比的权重来进行自动均衡处理。
3.类别均衡采样
把样本按类别分组,每个类别生成一个样本列表,训练过程中先随机选择1个或几个类别,然后从各个类别所对应的样本列表里选择随机样本。这样可以保证每个类别参与训练的机会比较均等。
上述方法需要对于样本类别较多任务首先定义与类别相等数量的列表,对于海量类别任务如ImageNet数据集等此举极其繁琐。海康威视研究院提出类别重组的平衡方法。
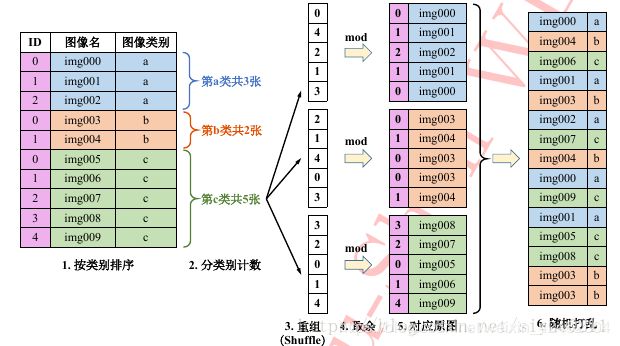
类别重组法只需要原始图像列表即可完成同样的均匀采样任务,步骤如下:
- 首先按照类别顺序对原始样本进行排序,之后计算每个类别的样本数目,并记录样本最多那个类的样本数目。
- 之后,根据这个最多样本数对每类样本产生一个随机排列的列表,
- 然后用此列表中的随机数对各自类别的样本数取余,得到对应的索引值。
- 接着,根据索引从该类的图像中提取图像,生成该类的图像随机列表。之后将所有类的随机列表连在一起随机打乱次序,即可得到最终的图像列表,可以发现最终列表中每类样本数目均等。
- 根据此列表训练模型,在训练时列表遍历完毕,则重头再做一遍上述操作即可进行第二轮训练,如此往复。
- 类别重组法的优点在于,只需要原始图像列表,且所有操作均在内存中在线完成,易于实现。
Thresholding
Thresholding的方法又称为post scaling的方法,即根据测试数据的不同类别样本的分布情况选取合适的阈值判断类别,也可以根据贝叶斯公式重新调整分类器输出概率值。一般的基础做法如下:假设对于某个类别class在训练数据中占比为x,在测试数据中的占比为x’。分类器输出的概率值需要做scaling,概率转换公式为:
fp=apap+b*1-p
a=x’x, b=1-x’1-x
当然这种加权的方式亦可在模型训练过程中进行添加,即对于二分类问题目标函数可以转换为如下公式:
loss=aytruelogypred+b1-ytruelog1-ypred
Cost sensitive learning
根据样本中不同类别的误分类样本数量,重新定义损失函数。Threshold moving和post scaling是常见的在测试过程进行cost调整的方法。这种方法在训练过程计算损失函数时亦可添加,具体参见上一部分。另外一种cost sensitive的方法是动态调节学习率,认为容易误分的样本在更新模型参数时的权重更大一些。
One-class分类
区别于作类别判决,One-class分类只需要从大量样本中检测出该类别即可,对于每个类别均是一个独立的detect model。这种方法能很好地样本极度不均衡的问题。
集成的方法
主要是使用多种以上的方法。例如SMOTEBoost方法是将Boosting和SMOTE 过采样进行结合。
使用其他评价指标
在准确率不行的情况下,使用召回率或者精确率试试。
准确度这个评价指标在类别不均衡的分类任务中并不能work。几个比传统的准确度更有效的评价指标:
混淆矩阵(Confusion Matrix):使用一个表格对分类器所预测的类别与其真实的类别的样本统计,分别为:TP、FN、FP与TN。
精确度(Precision)
召回率(Recall)
F1得分(F1 Score):精确度与找召回率的加权平均。
特别是:
Kappa (Cohen kappa)
ROC曲线(ROC Curves):见Assessing and Comparing Classifier Performance with ROC Curves
如何选择
解决数据不平衡问题的方法有很多,上面只是一些最常用的方法,而最常用的方法也有这么多种,如何根据实际问题选择合适的方法呢?接下来谈谈一些我的经验。
1、在正负样本都非常之少的情况下,应该采用数据合成的方式;
2、在负样本足够多,正样本非常之少且比例及其悬殊的情况下,应该考虑一分类方法;
3、在正负样本都足够多且比例不是特别悬殊的情况下,应该考虑采样或者加权的方法。
4、采样和加权在数学上是等价的,但实际应用中效果却有差别。尤其是采样了诸如Random Forest等分类方法,训练过程会对训练集进行随机采样。在这种情况下,如果计算资源允许上采样往往要比加权好一些。
5、另外,虽然上采样和下采样都可以使数据集变得平衡,并且在数据足够多的情况下等价,但两者也是有区别的。实际应用中,我的经验是如果计算资源足够且小众类样本足够多的情况下使用上采样,否则使用下采样,因为上采样会增加训练集的大小进而增加训练时间,同时小的训练集非常容易产生过拟合。
6、对于下采样,如果计算资源相对较多且有良好的并行环境,应该选择Ensemble方法。
参考文献
如何解决样本不均衡问题
Pytorch中使用样本权重(sample_weight)的正确方式
SMOTE算法(人工合成数据)
如何解决机器学习中数据不平衡问题

样本不均衡分类问题的解决
1.每种分类构建一个模型负样本为少数其他类
2.多个模型融合会产生比较好的结果
3.两个模型都调阈值增强正确的全部预测对 然后再把两个模型融合起来
4.或者直接构建两个欠拟合模型再融合二者
20211010
集成方法——使用所有分类中的小样本量,同时从分类中的大样本量中随机抽取数据来与小样本量合并构成训练集,这样反复多次会得到很多训练集,从而训练出多个模型。例如,在数据集中的正、负样本分别为100和10000条,比例为1:100,此时可以将负样本随机切分为100份,每份100条数据,然后每次形成训练集时使用所有的正样本(100条)和随机抽取的负样本(100条)形成新的训练数据集。如此反复可以得到100个模型。然后继续集成表决
当然常用的是上述集成方法,但是不是直接进行使用,试想训练100个模型进行表决,离线会很麻烦,而且线上使用也不现实。
所以通常会进行修改使用,一般情况下在选择正负样本时会进行相关比例的控制,假设正样本的条数是N,则负样本的条数会控制在2N或者3N,即遵循1:2或者1:3的关系,当然具体的业务场景下要进行不同的尝试和离线评估指标的对比。
