主成分分析(PCA)原理与实现
主成分分析(PCA)是最重要的数据降维的方法之一。针对高维数据的处理时,往往会因为数据的高维度产生大量的计算消耗,为了提高效率,一般最先想到的方法就是对数据降维。与“属性子集选择”的方法(即选择一部分有代表意义的属性直接替代原数据)不同,PCA是通过创建一个由原数据中的属性“组合”而成的,数量较小的变量集合来替代原数据。
PCA的基本思想可以这样描述:找出数据的所有属性中最主要的部分,用这个部分替代原始数据,从而达到降维的目的。显然,降维后的数据肯定会有所损失,而我们的目的,是要尽可能地保留原始数据的特征。所以,PCA的核心在于如何寻找这个“最主要部分”。
比如,现在有一组二维数据集合,如图Fig.1所示,如果要对这些二维数据降维到一维,那很容易想到在这个坐标系中找到一条直线,然后将所有的二维数据点都映射到这条直线上,我们再处理这些映射后的点,就相当于是直接对一维数据做处理了。但是找这样一条线是很讲究的,比如Fig.1中,X轴,Y轴,还有我标出的 l1,l2 l 1 , l 2 四条线,你说映射到哪条线更好呢?显然是 l1 l 1 ,因为样本点的投影在这条直线上能够尽可能地分开,你可以理解为最大限度的保留了数据特征(反过来想,如果投影后,尽可能地分不开,那数据点不都一样了,还有啥特征、区分啊)。
PCA要解决的,就是如何找这样一条直线。当然,如果我们想要将 n n 为空间的数据降到k k 维( n>k>0 n > k > 0 )空间上去,那实际上找的是一个 k k 维的超平面。其实,根据Fig.1我们不难发现:如果数据点集是完全无规律的随机分布,那么PCA的效果不会太好(因为不管找怎样一个超平面都会损失大量特征);而如果数据的维度之间存在相关关系,比如某个属性与另外一个属性或者属性的组合成一定的比例关系(像Fig.1中,X与Y就基本成正比例关系),则使用PCA时非常合适的。
刚才说了,找超平面的理论依据是“在超平面上的投影点要尽可能地分开”,那换句话说,就是要找到超平面,使之具备最大的“投影方差”。下面做一个详细的推导。
PCA原理推导:基于最大投影方差
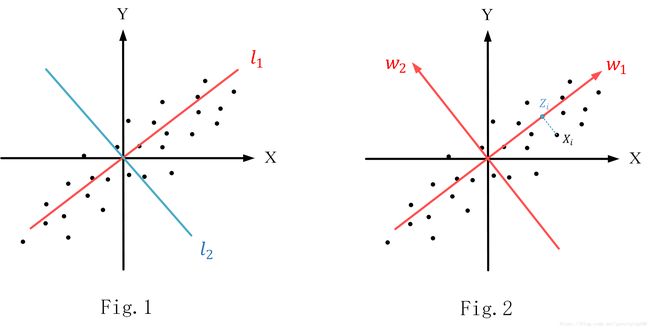
对于m m 个 n n 维数据向量{X1,X2,…,Xm} { X 1 , X 2 , … , X m } ,我们默认他们都已经经过了“中心化”处理,即 ∑mi=1Xi=0 ∑ i = 1 m X i = 0 ,如Fig.2所示。
(1) 假设现在找到了最佳的超平面(维度是 k k ),那我们旋转现有的坐标系,使其中的k k 个坐标轴组成的超平面就是我们要投影的超平面。这个过程相当于做基变换,变换过程中,我们令变换后的基是一组标准正交基,记为 W={w1,w2,…,wn} W = { w 1 , w 2 , … , w n } 。
(2) 现在可以得到,在新的坐标系下,投影后数据元组的坐标表示是:
知道了新坐标系下数据点的坐标,那么接着思考,这些数据点在其中一个或多个新坐标轴构造的超平面上的投影坐标是不是可以得到了,实际上就是直接去除一部分 Z∗i Z i ∗ 中的坐标即可,假设最终保留了 k k 个坐标,可以得到下式:
其中, W0 W 0 是正交基 W W 去除了对应的列向量得到的,WT0 W 0 T 是由 k k 个n n 维行向量构成的矩阵。至于是如何在 Z∗i Z i ∗ 中筛选出这 k k 个坐标的,我在后面讨论,先假设我已知怎么筛选了。这样,我们得到了新坐标系下数据集的投影坐标。现在可以计算投影坐标的方差,然后进行优化计算,使得方差最大。因为Xi X i ( Zi Z i )已经经过了中心化处理,所以方差的计算公式可以写成如下形式:
注意,高维数据集的方差实际上是其每个维度上数据的方差和。我们最终优化的目标是要让方差最大。那么忽略常数系数 1m 1 m ,目标函数可以写成如下形式:
(3) 化简上式:
这样,可得到最终的优化问题:
其中, E E 为k×k k × k 单位矩阵。
(4) 用拉格朗日乘子法求解。先得到拉格朗日方程:
对 W0 W 0 求导,得到:
可见, W0 W 0 为 XXT X X T 的特征向量组成的矩阵。因此,如果要将 n n 维的数据降维到k k 维, tr(WT0XXTW0) t r ( W 0 T X X T W 0 ) 的取值就应该是矩阵 XXT X X T 的最大的 k k 个特征值的和。
综上所述,如果我们事先不知道k k 的取值,可以先计算 XXT X X T 的特征值,选取其中明显较大的 k k 个,并且以这k k 个特征值对应的特征向量组成的矩阵(记做 W0 W 0 )对原始的数据元组进行变换。
以上即为PCA的原理,下面我们根据上述原理,总结一下PCA的具体步骤。
PCA实现步骤
- 预处理:对所有的数据进行中心化处理, Xi=Xi−1m∑mi=1Xi X i = X i − 1 m ∑ i = 1 m X i ;
- 计算样本的协方差矩阵 XXT X X T ,得到一个 n×n n × n 的矩阵;
- 计算 XXT X X T 的特征值及特征向量,取特征值最大的 k k 个特征向量做标准化处理,再作为列向量构成W0 W 0 ( n×k n × k 矩阵);
- 对于每个数据 Xi X i ,计算它在新坐标系 W0 W 0 中的坐标 Zi=XiW0 Z i = X i W 0 ( Zi Z i 为 k k 维向量)
写到这里,你再看看整个这4步,是不是感觉有点眼熟?和我在之前的博客: 奇异值分解 中说的过程可以说几乎一模一样。只不过这里不需要考虑奇异值分解中的左矩阵U U ,而直接使用右矩阵 V V 就行了。其实,本质上PCA就是通过奇异值分解来实现降维的。
那反过来讲,在事先不知道参数k k 的情况下,我们也能先做奇异值分解,再把分解后对角矩阵对角线上较小的 k k 个元素(即较小的k k 个奇异值)直接变为0,而将数据降维。
总结
最后,总结一下PCA的优缺点:
优点:
- 仅仅需要以方差衡量信息量,不受数据集以外的因素影响;
- 各主成分之间正交,可消除原始数据成分间的相互影响的因素;
- 计算方法简单,易实现;
缺点:
- 主成分各个维度的含义模糊,不易于解释;
- 方差小的非主成分也可能含有对样本差异的重要信息,因降维丢弃可能对后续数据处理有影响