CSAPP_Lab3 优化 Optimize
文章目录
- 优化 Optimize
-
- 优化思路:
-
- 一、一般有用的优化:
- 二、面向编译器的优化:障碍
- 三、面向超标量CPU的优化
- 四、面向向量CPU的优化:MMX/SSE/AVR
- 五、CMOVxx等指令
- 六、嵌入式汇编
- 七、面向编译器的优化 (Ox:0 1 2 3 g)
- 八、面向存储器的优化:Cache无处不在
- 九、内存作为逻辑磁盘:内存够用的前提下。
- 十、多进程优化
- 十一、文件访问优化:带Cache的文件访问
- 十二、并行计算:多线程优化
- 十三、网络计算优化
- 十四、GPU编程、算法优化
- 十五、超级计算:有能力有机会的话可以尝试更强的计算机
- 优化任务
- 代码及优化过程讲解
-
- 原代码
- 1. 一般有用的优化
-
- 1) 代码移动
- 2) 循环展开
- 2. 面向编译器优化
-
- Ox O1 O2
- 3. 面向超标量CPU优化
-
- 指令级别并发
- 4. AVX2指令集优化(面向CPU)
-
- 知识准备
- AVX2程序优化
- 4. 面向存储器优化(Cache)
-
- Windows下查看cache
- 时间局部性与空间局部性
- 缓存关联性
- 5. 并行计算
-
- 多线程优化
- 参考文献
优化 Optimize
优化思路:
一、一般有用的优化:
- 名称:代码移动
原理:需要执行多次但计算结果不会改变,放在循环中造成大量冗余的计算
实现方案:将多次重复计算的值放在循环外,用一个新变量表示
也可用O1优化实现 - 名称: 复杂指令简化
原理:
1)复杂指令系统计算机(CISC)方案包含一个丰富的微代码系统,简化了处理器上运行程序的编制。
2)精简指令系统计算机(RISC)方案有一个精简的指令系统。从而提高了微理器的效率,但需要更复杂的外部程序。
实现方案:利用精简指令集实现一些简单常用的操作,提高效率
利用位移代替乘除法等 - 名称:共享公共子表达式
原理:重用表达式的一部分,减少新变量的引入
实现方案: 代码实现或者用O1优化
二、面向编译器的优化:障碍
名称: 函数副作用,函数调用优化
原理:函数副作用是指,当调用函数时,被调用函数除了返回函数值之外,还对主调用函数产生附加的影响。例如,调用函数时在被调用函数内部:
- 修改全局量的值;
- 修改主调用函数中声明的变量的值(一般通过指针参数实现)。
函数副作用会给程序设计带来不必要的麻烦,给程序带来十分难以查找的错误,并且降低程序的可读性。
实现方案:合理的在函数中操作外部变量
名称:内存别名
原理:两个不同的变量指向同一个地址,修改可能出现时间或者逻辑上的问题
实现方案:利用引入局部变量,省去中间变量存储的方法减少这种影响
三、面向超标量CPU的优化
名称:流水线、超线程、多功能部件、分支预测投机执行、乱序执行、多核:分离的循环展开!
原理:只有保持能够执行该操作的所有功能单元的流水线都是满的,程序才能达到这个操作的吞吐量界限
实现方案:同过巧妙利用计算过程中变量之间的关系,把运算没有依赖性的变量分开计算,更大程度的利用流水线,提高工作效率。
可以利用循环展开等方法。
四、面向向量CPU的优化:MMX/SSE/AVR
名称:面向向量CPU的优化
原理:硬件可以并行执行多个指令,使用向量指令使多数据元素并行执行。
实现方案:利用MMX/SSE/AVR等指令集优化程序,可以利用底层硬件的运作方式,充分利用硬件,提高代码性能,如利用cache的按块读取优化程序。
五、CMOVxx等指令
原理:代替test/cmp+jxx,减少条件的判断,直接实现功能
实现方案:利用指令CMOVxx代替test/cmp+jxx
六、嵌入式汇编
名称:嵌入式汇编
原理:通过汇编语言更接近底层,通过对底层直接操作,防止编译器编译出一些冗繁的操作,省去一些不必要的判断
实现方案:利用嵌入汇编的方法,人为的对底层进行优化
七、面向编译器的优化 (Ox:0 1 2 3 g)
名称:面向编译器的优化
原理:期望能提高速度或者能够节省内存,对程序进行有偏向性的编译
实现方案:利用Ox:0 1 2 3 g等优化模式
不同的优化模式,对内存和速度等进行不同程度的优化
八、面向存储器的优化:Cache无处不在
名称:面向存储器的优化
原理:· 重新排列提高空间局部性:尽量优先使用连续空间内的值,因为cache line 载入值时会将其附近的值一同载入
· 分块提高时间局部性: 提高每个cache块的利用率,将反复多次调用的值先运算完再更新cache line
实现方案:充分利用cache的缓存原理,提高空间与时间局部性,减少cache miss的次数,提高cache利用率,从而提高代码访存效率。
九、内存作为逻辑磁盘:内存够用的前提下。
十、多进程优化
进程与线程
名称:多进程优化
原理: fork,每个进程负责各自的工作任务,通过mmap共享内存或磁盘等进行交互。
同一个核处理的进程来回切换,似乎是在同时执行,实际上是交替执行。
实现方案:充分利用多核的性质同时处理多件事情
十一、文件访问优化:带Cache的文件访问
带cache内存
名称:文件访问优化:带Cache的文件访问
原理:cache是高速缓存,是内存的一部分,访问文件时如果可以在cache命中就不用去访问速度慢很多的外设中去读取了。
Write-through(直写)——写操作同时被更新到cache和后端存储。
Write-back(回写)——写操作仅仅被更新到cache中。只有在这个cache将要被更新前,才将旧数据更新到后端存储。
二者各有优缺点:直写模式下,速度较慢,但数据安全。回写模式下,速度快,但数据不安全(设备断电了!)。
实现方案:一般情况下,如果不需要对mem进行平凡的更新,则使用带cache的文件,以文件写回的方式可以更快速的访问内存。
十二、并行计算:多线程优化
名称:并行计算:多线程优化
原理:线程可以同时进行,利用多线程处理一件事可以提高完成速度
·并发:指应用能够交替执行不同的任务,比如单CPU核心下执行多线程并非是同时执行多个任务,如果你开两个线程执行,就是在你几乎不可能察觉到的速度不断去切换这两个任务,已达到"同时执行效果",其实并不是的,只是计算机的速度太快,我们无法察觉到而已.
·并行:指应用能够同时执行不同的任务,例:吃饭的时候可以边吃饭边打电话,这两件事情可以同时执行。
实现方案:充分利用多线程可以同时工作的机制,将一件事拆分为几件小事,每部分之间互不依赖,就可以利用多线程同时执行一件事的每一部分,提高工作效率。
十三、网络计算优化
十四、GPU编程、算法优化
名称:GPU编程
原理:利用GPU多核的特点,拥有更强的算力,可以更快的完成任务
实现方案:利用GPU运行程序
名称:算法优化
原理:相同的任务利用更优的算法,可以降低时间复杂度和空间复杂度
实现方案:寻找更优的算法执行程序
十五、超级计算:有能力有机会的话可以尝试更强的计算机
*优化思路很多,鉴于本人又菜、时间又不够,所以只实现了其中极少一部分
学浅才疏望批评指正
优化任务
一个图像处理程序实现图像的平滑,其图像分辨率为1920*1080,每一点颜色值为64b,
用long img[1920][1080]存储屏幕上的所有点颜色值,颜色值可从0依行列递增,或真实图像。
平滑算法为:任一点的颜色值为其上下左右4个点颜色的平均值,即:
img[i][j] = ( img[i-1][j] + img[i+1][j]
+img[i][j-1] + img[i][j+1] ) /4。
请面向你的CPU与cache,利用本课程学过的优化技术,编写程序,并说明你所采用的优化方法。
代码及优化过程讲解
原代码
首先写一个利用双层
for循环求解的过程作为原始代码
因为后面需要进行代码移动优化,这里就先假装自己很傻,先按列处理再按行处理
Image Smooth ⇒ IS
// 平滑处理原码
void Origin_IS(void) {
// 忽略四个角点
// 忽略所有边缘,因为课程目的是测试程序性能优化
long Last_Image[2][IMAGE_H];// 用来存上一行的数据,从上往下处理,原图被覆盖后还要用到上一行原来的数据
// 四个相邻点
for (int i = 0; i < IMAGE_H; i++) Last_Image[0][i] = IMG[i][0];
for (int j = 1; j < IMAGE_W - 1; j++) {
for (int i = 0; i < IMAGE_H; i++) Last_Image[1][i] = IMG[i][j];
for (int i = 1; i < IMAGE_H - 1; i++) {
// 上 下 左 右
IMG[i][j] = (Last_Image[1][i - 1] + IMG[i + 1][j] + Last_Image[0][i] + IMG[i][j + 1]) >> 2;
}
for (int i = 0; i < IMAGE_H; i++) Last_Image[0][i] = Last_Image[1][i];
}
}
1. 一般有用的优化
1) 代码移动
原理: 充分利用内存连续和cache的空间局限性,降低cache miss率,大大提高程序执行效率所以按行读取要比按列读取快
// 移动代码的执行顺序
void CodeMove_IS(void) {
// 忽略所有边缘,因为课程目的是测试程序性能优化
long Last_Image[2][IMAGE_W];// 用来存上一行的数据,从上往下处理,原图被覆盖后还要用到上一行原来的数据
memcpy(Last_Image[1], IMG[0], sizeof(Last_Image[1]));
for (int i = 1; i < IMAGE_H - 1; i++) {
memcpy(Last_Image[0], IMG[i], sizeof(Last_Image[0]));
for (int j = 1; j < IMAGE_W - 1; j++) {
// 上 下 左 右
IMG[i][j] = (Last_Image[1][j] + IMG[i + 1][j] + Last_Image[0][j - 1] + Last_Image[0][j + 1]) >> 2;
}
memcpy(Last_Image[1], Last_Image[0], sizeof(Last_Image[1]));
}
}

2) 循环展开
原理: 将循环在内部展开,减少分支判断次数,提高运行速度#define BlockWidth 4
// 一般优化——循环展开
void LoopUnrolling_IS(void) {
// 忽略所有边缘,因为课程目的是测试程序性能优化
int WidthRest = (IMAGE_H - 2) % BlockWidth;
for (int i = 1; i < IMAGE_H - 1; i++) {
for (int j = 1; j < IMAGE_W - 1 - WidthRest; j += BlockWidth) {
// 上 下 左 右
IMG[i][j] = ((IMG[i - 1][j] + IMG[i + 1][j] + IMG[i][j - 1] + IMG[i][j + 1]) >> 2);
IMG[i][j + 1] = ((IMG[i - 1][j + 1] + IMG[i + 1][j + 1] + IMG[i][j - 1 + 1] + IMG[i][j + 1 + 1]) >> 2);
IMG[i][j + 2] = ((IMG[i - 1][j + 2] + IMG[i + 1][j + 2] + IMG[i][j - 1 + 2] + IMG[i][j + 1 + 2]) >> 2);
IMG[i][j + 3] = ((IMG[i - 1][j + 3] + IMG[i + 1][j + 3] + IMG[i][j - 1 + 3] + IMG[i][j + 1 + 3]) >> 2);
}
}
}
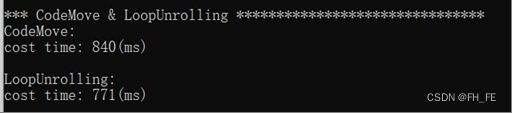
快了一点点
2. 面向编译器优化
Ox O1 O2
Windows10 使用 Visual Studio 进行编译器优化
项目 => 属性 => C/C++ => 优化
一开始应该是自定义,选择优化方式,重新运行代码
1) 禁用优化
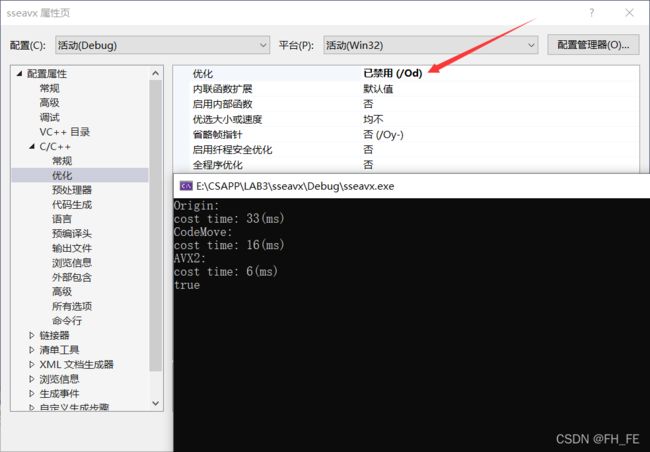

1) O1优化
如果你的VS不能运行优化指令,报错不兼容,点击这里查看解决方案
在这里插入图片描述

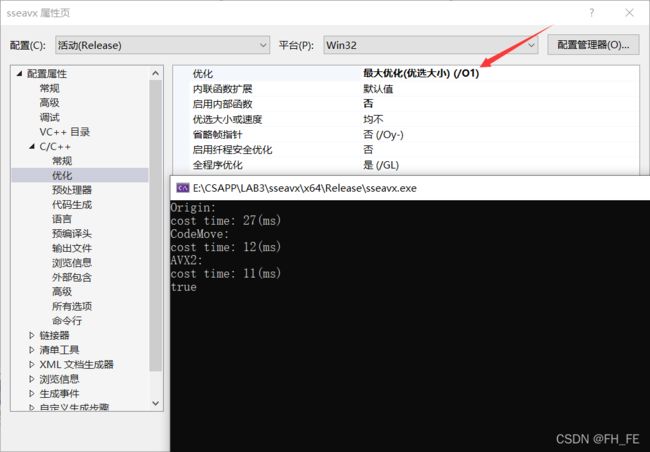
1) O2优化


1) Ox优化


自己上手一尝试就会发现,挺玄学的,似乎快慢会有变动,目前太菜解释不了
3. 面向超标量CPU优化
指令级别并发
下面是指令级并发的一个例子:
#define FOR for(int i = 0; i < 5; i++)
#define N 64 * 1024 * 1024
int arr[N];
printf("step_16: \n");
FOR for (int i = 0; i < N; i ++) arr[0] ++, arr[0]++;
printf("step_1: \n");
FOR for (int i = 0; i < N; i ++) arr[0] ++, arr[1]++;
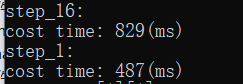
第二个比第一个快了约一倍!
这是由于现代处理器中对不同部分指令拥有一点并发性(跟流水线有关,比如Pentium处理器就有U/V两条流水线)。这使得CPU在同一时刻可以访问L1两处内存位置,或者执行两次简单算数操作。
- 第一个循环中,操作是相互依赖的,后一个需要等前一个执行完才能进行
- 第二个循环中,操作相互独立,可以两条流水一起跑
流水线给自己科普一波
关于CPU的流水线(pipeline)并发性简单说说,Intel Pentium处理器有两条流水线U和V,每条流水线可各自独立地读写缓存,所以可以在一个时钟周期内同时执行两条指令。但这两条流水线不是对等的,U流水线可以处理所有指令集,V流水线只能处理简单指令。
CPU指令通常被分为四类,
- 第一类是常用的简单指令,像mov, nop, push, pop, add, sub, and, or, xor, inc, dec, cmp, lea,可以在任意一条流水线执行,只要相互之间不存在依赖性,完全可以做到指令并发。
- 第二类指令需要同别的流水线配合,像一些进位和移位操作,这类指令如果在U流水线中,那么别的指令可以在V流水线并发运行,如果在V流水线中,那么U流水线是暂停的。
- 第三类指令是一些跳转指令,如cmp,call以及条件分支,它们同第二类相反,当工作在V流水线时才能通U流水线协作,否则只能独占CPU。
- 第四类指令是其它复杂的指令,一般不常用,因为它们都只能独占CPU。
如果是汇编级别编程,要达到指令级别并发,必须要注重指令之间的配对。尽量使用第一类指令,避免第四类,还要在顺序上减少上下文依赖。
图像平滑如何利用指令集并发?
提供一个思路:可以每隔两个平滑处理一次,因为只要不相邻两个操作相互独立,可以在两条流水线中运行
// 原代码
// 移动代码的执行顺序,不考虑图像处理覆盖问题,直接比比较程序性能
void CodeMove_IS_1(void) {
// 忽略所有边缘,因为课程目的是测试程序性能优化
for (int i = 1; i < IMAGE_H - 1; i++) {
for (int j = 1; j < IMAGE_W - 1; j++) {
// 上 下 左 右
IMG[i][j] = (IMG[i - 1][j] + IMG[i + 1][j] + IMG[i][j - 1] + IMG[i][j + 1]) >> 2;
}
}
}
// 消除运算间的相互依赖,单核U/V双流水工作
void Pipeine_IS(void) {
// 忽略所有边缘,因为课程目的是测试程序性能优化
for (int i = 1; i < IMAGE_H - 1; i++) {
for (int j = 1; j < IMAGE_W - 1; j += 8) {
// 上 下 左 右
IMG[i][j] = (IMG[i - 1][j] + IMG[i + 1][j] + IMG[i][j - 1] + IMG[i][j + 1]) >> 2;
IMG[i][j + 2] = (IMG[i - 1][j + 2] + IMG[i + 1][j + 2] + IMG[i][j - 1 + 2] + IMG[i][j + 1 + 2]) >> 2;
IMG[i][j + 4] = (IMG[i - 1][j + 4] + IMG[i + 1][j + 4] + IMG[i][j - 1 + 4] + IMG[i][j + 1 + 4]) >> 2;
IMG[i][j + 6] = (IMG[i - 1][j + 6] + IMG[i + 1][j + 6] + IMG[i][j - 1 + 6] + IMG[i][j + 1 + 6]) >> 2;
}
for (int j = 2; j < IMAGE_W - 1; j += 8) {
// 上 下 左 右
IMG[i][j] = (IMG[i - 1][j] + IMG[i + 1][j] + IMG[i][j - 1] + IMG[i][j + 1]) >> 2;
IMG[i][j + 2] = (IMG[i - 1][j + 2] + IMG[i + 1][j + 2] + IMG[i][j - 1 + 2] + IMG[i][j + 1 + 2]) >> 2;
IMG[i][j + 4] = (IMG[i - 1][j + 4] + IMG[i + 1][j + 4] + IMG[i][j - 1 + 4] + IMG[i][j + 1 + 4]) >> 2;
IMG[i][j + 6] = (IMG[i - 1][j + 6] + IMG[i + 1][j + 6] + IMG[i][j - 1 + 6] + IMG[i][j + 1 + 6]) >> 2;
}
}
}
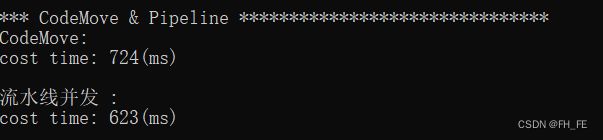
速度有提升!
4. AVX2指令集优化(面向CPU)
知识准备
查看Intel指令集
大佬讲解指令集,tql
那么这些指令集是什么作用呢?下面给出一个例子
Synopsis
Synopsis
__m256i _mm256_maskload_epi64 (__int64 const* mem_addr, __m256i mask)
#include Description
Load packed 64-bit integers from memory into dst using mask (elements are zeroed out when the highest bit is not set in the corresponding element).
该指令将64位(4字节)的long型整数打包,放入dst
Operation
FOR j := 0 to 3
i := j*64
IF mask[i+63]
dst[i+63:i] := MEM[mem_addr+i+63:mem_addr+i]
ELSE
dst[i+63:i] := 0
FI
ENDFOR
dst[MAX:256] := 0
从上面的示例可以看出,每次将4个long型数打包为一个块进行读取256=4*64
我的
X86 -64中long占4个字节,但是一般认为long在64位的电脑上应该是8个字节,(#define long long long,这样就把long变成8个字节),所以我打算按照4个long打包为一个块的形式遍历
实现过程需要的指令如下
// 读取块(4个long打包为1个块)
__m256i _mm256_maskload_epi64 (__int64 const* mem_addr, __m256i mask)
// 对块求和(块中的4个元素对应相加得到一个新的块)
__m256i _mm256_add_epi64 (__m256i a, __m256i b)
// 将块取出赋值给一个临时的块变量
void _mm256_maskstore_epi64 (__int64* mem_addr, __m256i mask, __m256i a)
// 对块实现除法
// 将块 a 中的每个元素都右移 imm8 位
__m256i _mm256_srli_epi64 (__m256i a, int imm8)
[2,4,8,12] >> 1
==>
[1,2,4,6]
// 将一个块赋值给另一个块
void _mm256_storeu_si256 (__m256i * mem_addr, __m256i a)
注意:选择不同的指令集需要导入对应的头文件
| 头文件 | 宏 | 编译器参数 |
|---|---|---|
| avx2intrin.h | AVX2 | -mavx2 |
| avxintrin.h | AVX | -mavx |
| emmintrin.h | SSE2 | -msse2 |
| nmmintrin.h | SSE4_2 | -msse4.2 |
| xmmintrin.h | SSE | -msse |
| mmintrin.h | MMX | -mmmx |
头文件设置
#include 上述头文件中,下一个头文件包含上一个头文件中内容,例如xmmintrin.h为SSE 头文件,此头文件里包含MMX头文件,emmintrin.h为SSE2头文件,此头文件里包含SSE头文件。
VC引入
会自动引入当前编译器所支持的所有Intrinsic头文件。GCC引入 .
在Microsoft官方文档查了一下,AVX2指令可以在#include 中调用


综上,调用#include 就行
AVX2程序优化
思路:
Origin_IS()中每次都要读取上下左右四个数,而且有两个是跨行读取,不够优
可以考虑按块读取,考虑到long是8字节(64位),指令集中一般最多移动256位,于是选择将4个long型的整数打包为一个块,按块读取、计算
计算过程如图所示:

按块读取可以一次跨行读取可以读到4个数,减少了跨行读取次数,提高了运行速度
原理: 硬件可以并行执行多个指令,使用向量指令使多数据元素并行执行
代码如下
// AVX2指令集优化
void AVX2_IS(void) {
int nBlockWidth = 4;
int cntBlock = (IMAGE_W - 2) / nBlockWidth; // 利用长度为4的块,左右两个重叠后长度为6,每次往后移动4,可移动次数为cntBlock
int cntRem = (IMAGE_W-1) % nBlockWidth; // 边缘不需要处理
__m256i output[4];
__m256i loadData_l, loadData_r, loadData_u, loadData_d;
long Last_Image[2][IMAGE_W];// 用来存上一行的数据,从上往下处理,原图被覆盖后还要用到上一行原来的数据
memcpy(Last_Image[1], IMG[0], sizeof(Last_Image[1]));
for (int i = 1; i < IMAGE_H - 1; i++) {
memcpy(Last_Image[0], IMG[i], sizeof(Last_Image[0]));
const long* p_l = &Last_Image[0][0];
const long* p_r = &IMG[i][2];
const long* p_u = &Last_Image[1][1];
const long* p_d = &IMG[i+1][1];
long* p = &IMG[i][1]; // 被处理了的中间块
for (int j = 0; j < cntBlock; j++) {
loadData_l = _mm256_load_si256((__m256i*)(p_l)); // 强转一波
loadData_r = _mm256_load_si256((__m256i*)(p_r));
loadData_u = _mm256_load_si256((__m256i*)(p_u));
loadData_d = _mm256_load_si256((__m256i*)(p_d));
loadData_l = _mm256_add_epi64(loadData_l, loadData_r);
loadData_u = _mm256_add_epi64(loadData_u, loadData_d);
*((__m256i*)p) = _mm256_srli_epi64(_mm256_add_epi64(loadData_l, loadData_u), 2);
p_l += nBlockWidth;
p_r += nBlockWidth;
p_u += nBlockWidth;
p_d += nBlockWidth;
p += nBlockWidth;
}
for (int j = 0; j < cntRem - 1; j++) {
*p = (*p_l + *p_r + *p_u + *p_d) >> 2;
p++;
p_l++;
p_r++;
p_u++;
p_d++;
}
memcpy(Last_Image[1], Last_Image[0], sizeof(Last_Image[1]));
}
}

4. 面向存储器优化(Cache)
Windows下查看cache
百度CPU-Z在Windows下查看cache大小

由于我的电脑是6核的,我有6个
32KB的L1数据缓存,6个32KB的L1指令缓存,还有6个256kB大小L2数据缓存。L1缓存是处理器独享的,L2缓存是成对处理器共享的。
所以我的一级cache能存储
32 * 1024 / 4 == 8 * 1024 == 8192个int型整型
二级cache能存储
128 * 1024 / 4 == 8192 * 4个int型整数
Cache Line可以简单的理解为CPU Cache中的最小缓存单位。目前主流的CPU Cache的Cache Line大小都是64Bytes,即
16个int
当数组小于64Bytes时数组极有可能落在一条Cache Line内,而一个元素的访问就会使得整条Cache Line被填充,因而值得后面的若干个元素受益于缓存带来的加速。而当数组大于64Bytes时,必然至少需要两条Cache Line,继而在循环访问时会出现两次Cache Line的填充,由于缓存填充的时间远高于数据访问的响应时间,因此多一次缓存填充对于总执行的影响会被放大
每次访问
cache line没得到想要的数据,就要从内存移入一次,这个过程叫cache miss
下面比较cache miss对效率的影响
下面代码用于测试
#include 
结果说明跨cache line在L1中访问,访问数据会慢一些
结果说明跨L1、L2访问,L2向L3读取数据,效率会大大降低
时间局部性与空间局部性
面向存储器的优化:Cache无处不在
重新排列提高空间局部性
分块提高时间局部性
缓存关联性(直接映射,N路组关联,完全关联)
- 时间局部性:内存中的值被换入缓存,今后一段时间内会被多次引用
- 空间局部性:该内存附近的值也被换入缓存
今天的CPU不再是按字节访问内存,而是以64字节为单位的块(chunk)拿取,称为一个缓存行(cache line)。当你读一个特定的内存地址,整个缓存行将从主存换入缓存,并且访问同一个缓存行内的其它值的开销是很小的。
理解缓存行对某些类型的程序优化而言可能很重要。比如,数据字节对齐可能决定一次操作接触1个还是2个缓存行。
其实前面移动代码位置的方式也是利用了内存的连续性,读取时由于空间局部性,其附近的值也被存进了cache,所以hit的次数变多了,miss的次数减少,从而提高了代码的运行效率
将运算合理的分块,可以提高时间或者空间局部性,从而优化代码
以矩阵运算为例
A ∗ B A*B A∗B, A A A的横行要与 B B B的每一列相乘,如果乘一次换一行那么每次都要重新载入cache,miss的次数太多导致代码效率低下
27 ms :
#define M (2048)
#define N (1024)
static void naive(float vec_in[M], float mat[M][N], float vec_out[N]){
for(int n = 0; n < N; n++){ // 每次循环算出一个输出
for(int m = 0; m < M; m++){ // M个元素乘累加
vec_out[n] += vec_in[m] * mat[m][n];
}
}
}
可以通过提高时间局部性,让 A A A的一个横行先与 B B B的每列计算完之后,再载入 A A A的下一行,会大大减少cache miss的次数,提高代码运算效率。
6 ms :
#define M (2048)
#define N (1024)
#define BLK_SZ (32)
static void blocking(float vec_in[M], float mat[M][N], float vec_out[N]){
for(int n = 0; n < N; n++){
for(int m0 = 0; m0 < M / BLK_SZ; m0++){ // 外层循环,分为M/BLK_SZ个块
for(int m1 = 0; m1 < BLK_SZ; m1++){ // 内层循环,块内计算
vec_out[n] += vec_in[m0 * BLK_SZ + m1] * mat[m0 * BLK_SZ + m1][n];
}
}
}
}
那么来考虑我们的图像平滑如何能优化
首先我认为分块并不能对我们的程序起到优化作用,证明如下
此时按行处理,每次载入
cache_line都会在接下来被使用,这已经利用到了空间局部性
.
于是考虑时间局部性
寻找被多次重复使用的值,能发现,除了边界像素点,其余像素点都要被访问3次(处理上一行,当前行,和下一行),这也没什么优化空间,于是乎,此处cache 分块不会有效,而且可能由于块的高度太大,导致L2从L3载入像素点的次数变多,从而大大降低程序运行速度
首先我们取分块的宽为
8,也就是一个cache line所能存储的long整型的数量,这样可以在cache line内读取,来测试结果是否会变慢
void CodeMove_IS_2(void) {
// 忽略所有边缘,因为课程目的是测试程序性能优化
int y;
for (int i = 1; i < IMAGE_H - 1; i++) {
for (int j = 1; j < IMAGE_W - 1; j++) {
y = j;
// 上 下 左 右
IMG[i][y] = (IMG[i - 1][y] + IMG[i + 1][y] + IMG[i][y - 1] + IMG[i][y + 1]) >> 2;
}
}
}
// cache优化--(分块优化)
void Cache_IS(void) {
// 忽略所有边缘,因为课程目的是测试程序性能优化
// 块的大小: H * BlockWidth = 8 * 8
int y;
for (int i = 1; i < IMAGE_H - 1; i += BlockHeight) {
for (int j = 1; j < IMAGE_W - 1; j += BlockWidth) {
for (int k_j = 0; k_j < BlockWidth; k_j++) {
for (int k_i = i; k_i < i + BlockHeight; k_i++) {
y = j + k_j;
// 上 下 左 右
IMG[k_i][y] = ((IMG[k_i - 1][y] + IMG[k_i + 1][y] + IMG[k_i][y - 1] + IMG[k_i][y + 1]) >> 2);
}
}
}
}
}

果然,不仅没有优化,还变慢了
缓存关联性
此处更适用于完全底层的优化,尤其是高性
能存储部分,在日常的编码中不是首先要考虑的问题。
缓存设计的一个关键决定是确保每个主存块(chunk)能够存储在任何一个cache line里,或者只是其中一些
有三种方式将内存块映射到cache line中:
-
1.直接映射(Direct mapped cache)
每个内存块只能映射到一个特定的cache line。一个简单的方案是通过块索引chunk_index映射到对应的cache line。被映射到同一cache line的两个内存块不能同时换入缓存。(chunk_index可以通过物理地址/缓存行字节计算得到) -
2.N路组关联(N-way set associative cache)
每个内存块能够被映射到N路特定cache line的任意一路。比如一个8路缓存,每个内存内存块能够被映射到8路不同的cache line。一般地,具有一定相同低bit位地址的内存块将共享16路cache line。(相同低位地址表明相距一定单元大小的连续内存) -
3.完全关联(Fully associative cache)
每个内存块能够被映射到任意一个cache line。操作效果上相当于一个散列表。
直接映射缓存会引发冲突——当多个值竞争同一个缓存行,它们将相互驱逐对方,导致命中率暴跌。另一方面,完全关联缓存过于复杂,并且硬件实现上昂贵。
综上,N路组关联是处理器缓存的典型方案,它在电路实现简化和高命中率之间取得了良好的折中。
5. 并行计算
多线程优化
利用C语言开多线程,需要
pthread.h
利用C++开多线程,需要thread.h
安装pthread.h库参考
gcc xxx.c -lpthread
./a.out
以华为泰山服务器为例
# 查看逻辑CPU的个数
cat /proc/cpuinfo| grep "processor"| wc -l
首先看到服务器有 96 个逻辑核,那我们最好开不超过 96 个线程
![]()
开 4 个线程

开 8 个线程

开 16 个线程

开 32 个线程

开 64 个线程

开 96 个线程

看起来多开几个线程是不错,但是得有个度
芜湖~效果起飞!
参考文献
Microsoft Visual Studio 官方文档
优雅的 cache 讲解
循环优化之循环分块
Wiki cache 讲解
cache优化代码示例1
cache优化代码示例2
cache优化代码示例3(优质)
超级优质的cache讲解
带cache内存与不带cache内存
进程与线程