Meta开源的LLaMa到底好不好用?最全测评结果来了

源|机器之心
Meta 开源的大模型系列 LLaMA 评测出炉,对比结果显示,和 ChatGPT 还是有差距的。
ChatGPT 的持续爆火,早已让各大科技公司坐不住了。
就在刚刚过去的一周,Meta「开源」了一个新的大模型系列 ——LLaMA(Large Language Model Meta AI),参数量从 70 亿到 650 亿不等。因为 LLaMA 比之前发布的很多大模型参数更少,但性能更好,所以一经发布让很多研究者兴奋不已。
例如,130 亿参数的 LLaMA 模型「在大多数基准上」可以胜过参数量达 1750 亿的 GPT-3,而且可以在单块 V100 GPU 上运行;而最大的 650 亿参数的 LLaMA 模型可以媲美谷歌的 Chinchilla-70B 和 PaLM-540B。
参数量的减少对于普通研究者和商业机构来说都是好事,但 LLaMA 真的像论文中说得那样表现那么好吗?和当前的 ChatGPT 相比,LLaMA 是否可以勉强一战?为了解答这些疑问,有些研究者已经对这一模型进行了测试。
还有公司已经在尝试补齐 LLaMA 短板,想看能不能通过添加 RLHF 等训练方法让 LLaMA 表现更好。
LLaMA 初步评测
这份评测结果来自一位名叫 @Enryu 的 Medium 作者。它比较了 LLaMA 和 ChatGPT 在解释笑话、零样本分类和代码生成三个颇具挑战性的任务中的效果。相关博客文章为《Mini-post: first look at LLaMA》。
作者在 RTX 3090/RTX 4090 上运行 LLaMA 7B/13B 版本,在单个 A100 上运行 33B 版本。
需要注意的是,与 ChatGPT 不同,其他模型并不是基于指令微调,因此 prompt 的结构有所不同。
解释笑话
这是谷歌原始 PaLM 论文中展示的一个用例:给出一个笑话,让模型来解释它为什么好笑。该任务需要将世界知识和一些基本逻辑相结合。PaLM 之前的所有模型都无法做到这一点。作者从 PaLM 论文中提取了一些示例,比较了 LLaMA-7B、LLaMA-13B、LLaMA-33B 与 ChatGPT 的表现。

可以看到,结果很糟糕。这些模型 get 到了一些笑点,但无法真正理解,它们只是随机生成一些相关的文本流。ChatGPT 虽与 LLaMA-33B 一样表现很差(其他几个模型更差),但它遵循了不一样的策略:生成了一大堆文本,希望自己的回答至少有一部分是正确的(但大部分显然不是),是不是很像大家考试时应对问答题的策略?
不过,ChatGPT 起码 get 到了关于 Schmidthuber 的笑话。但总的来说,这些模型在零样本笑话解释任务上的效果与 PaLM 相差甚远(除非 PaLM 的示例是精心挑选)。
零样本分类
作者考虑的第二项任务更具挑战性 —— 标题党(clickbait)分类。由于连人类也无法就什么是标题党达成一致,作者在 prompt 中为这些模型提供了一些示例(因此实际上是小样本而非零样本)。如下为 LLaMa 的 prompt:
I will tell whether the following news titles are clickbait:
1) The WORST care homes in England: Interactive map reveals the lowest-rated 2,530 residences - so is there one near you?
Clickbait: yes
2) Netflix's top 10 most-watched movies of all time
Clickbait: yes
3) Peering Through the Fog of Inflation
Clickbait: no
4) You’ll never believe which TV cook this cheeky chap grew up to be
Clickbait: yes下图为 LLaMA-7B、LLaMA-13B、LLaMA-33B 与 ChatGPT 的更多示例结果。

很明显,赢家为 LLaMA-33B,它是唯一一个能够遵循所有请求格式(yes/no)的模型,并且预测合理。ChatGPT 也还可以,但有些预测不太合理,格式也有错误。较小的模型(7B/13B)不适用于该任务。
代码生成
虽然 LLM 擅长人文学科,但在 STEM 学科上表现糟糕。LLaMA 虽然有基准测试结果,但作者在代码生成领域尝试了一些特别的东西,即将人类语言零样本地转换为 SQL 查询。这并不是很实用,在现实生活中直接编写查询会更有效率。这里只作为代码生成任务的一个示例。
在 prompt 中,作者提供表模式(table schema)以及想要实现的目标,要求模型给出 SQL 查询。如下为一些随机示例,老实说,ChatGPT 看起来效果更好。
-- We have a table `events` with columns `event_id`, `timestamp`, `user_id`, `rpc_method`.
-- We want to count how many users issued request "Login" over the last week.
-- SQL query for this is:
-- 7b
SELECT count (*)
FROM events
WHERE user_id IN (SELECT user_id
FROM events
WHERE timestamp >= NOW () - INTERVAL 7 DAY)
AND rpc_method = 'Login';
-- 13b
SELECT COUNT (*) FROM events WHERE rpc_method = "Login"
AND UNIX_TIMESTAMP (timestamp) >= UNIX_TIMESTAMP (CURRENT_DATE - INTERVAL 7 DAY)
-- 33b
SELECT user_id,
COUNT (DISTINCT user_id) AS total
FROM events
WHERE timestamp BETWEEN TIMESTAMP '2013-08-14 00:00:00' AND TIMESTAMP '2013-08-21 00:00:00'
AND rpc_method = 'Login'
GROUP BY user_id
-- ChatGPT
SELECT COUNT (DISTINCT user_id)
FROM events
WHERE rpc_method = 'Login'
AND timestamp >= DATE_SUB (NOW (), INTERVAL 1 WEEK);从测试结果来看,LLaMA 在一些任务上表现还不错,但在另一些任务上和 ChatGPT 还有一些差距。如果能像 ChatGPT 一样加入一些「训练秘籍」,效果会不会大幅提升?
加入 RLHF,初创公司 Nebuly AI 开源 ChatLLaMA 训练方法
虽然 LLaMA 发布之初就得到众多研究者的青睐,但是少了 RLHF 的加持,从上述评测结果来看,还是差点意思。
在 LLaMA 发布三天后,初创公司 Nebuly AI 开源了 RLHF 版 LLaMA(ChatLLaMA)的训练方法。它的训练过程类似 ChatGPT,该项目允许基于预训练的 LLaMA 模型构建 ChatGPT 形式的服务。项目上线刚刚 2 天,狂揽 5.2K 星。

项目地址:
https://github.com/nebuly-ai/nebullvm/tree/main/apps/accelerate/chatllam
ChatLLaMA 训练过程算法实现主打比 ChatGPT 训练更快、更便宜,我们可以从以下四点得到验证:
ChatLLaMA 是一个完整的开源实现,允许用户基于预训练的 LLaMA 模型构建 ChatGPT 风格的服务;
与 ChatGPT 相比,LLaMA 架构更小,但训练过程和单 GPU 推理速度更快,成本更低;
ChatLLaMA 内置了对 DeepSpeed ZERO 的支持,以加速微调过程;
该库还支持所有的 LLaMA 模型架构(7B、13B、33B、65B),因此用户可以根据训练时间和推理性能偏好对模型进行微调。
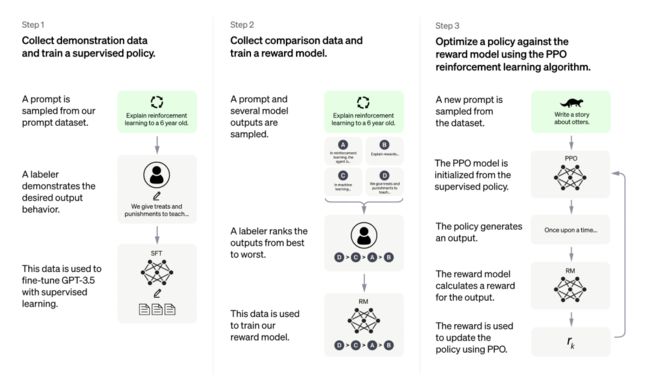 ▲图源:https://openai.com/blog/chatgpt
▲图源:https://openai.com/blog/chatgpt
更是有研究者表示,ChatLLaMA 比 ChatGPT 训练速度最高快 15 倍。

不过有人对这一说法提出质疑,认为该项目没有给出准确的衡量标准。

项目刚刚上线 2 天,还处于早期阶段,用户可以通过以下添加项进一步扩展:
带有微调权重的 Checkpoint;
用于快速推理的优化技术;
支持将模型打包到有效的部署框架中。
Nebuly AI 希望更多人加入进来,创造更高效和开放的 ChatGPT 类助手。
该如何使用呢?首先是使用 pip 安装软件包:
pip install chatllama-py然后是克隆 LLaMA 模型:
git clone https://github.com/facebookresearch/llama.gitcd llama
pip install -r requirements.txt
pip install -e .一切准备就绪后,就可以运行了,项目中介绍了 ChatLLaMA 7B 的训练示例,感兴趣的小伙伴可以查看原项目。
后台回复关键词【入群】
加入卖萌屋NLP、CV、搜推广与求职讨论群
[1] https://www.linkedin.com/posts/activity-7035964259431763970-YdMK/_
[2] https://medium.com/@enryu9000/mini-post-first-look-at-llama-4403517d41a1_
