dolphinscheduler海豚调度升级(1.3.3->2.0.5)及问题总结

更新(2022-07-07)
墙裂不建议更新到2.0.5。我已经将生产环境回退到1.3.3了。2.0.5有个非常大的BUG,影响生产环境调度跑批。详情看问题9。
更新(2022-07-12)
这个BUG,在12号发布的2.0.6已经修复,待测试。
文章写于2022-04-14。早就说更新我们公司海豚了,一直忙拖到现在。
我们公司用的海豚1.3.3版本,这个版本问题有点多。影响到了生产了,所以准备对海豚进行个升级。升级到海豚最新版本是2.0.5。这个版本还是有点坑,毕竟新增了一些东西。不过相对1.3.3,我更喜欢2.x的海豚。接下来,我将升级过程及升级后出现的BUG记录起来。
升级前备份和准备:
- 备份海豚元数据库
- 提前准备好相对应的jar包。如Mysql驱动等
- 保证每个节点之间的网络要通畅(安装需要ssh和scp)
- 保存自己在资源中心和数据源中心的资源。
海豚升级步骤:
官网升级步骤地址:https://dolphinscheduler.apache.org/zh-cn/docs/latest/user_doc/guide/upgrade.html
升级还是比较容易的只需要改一个文件、执行两个脚本即可。
官方2.0.5下载地址:https://dlcdn.apache.org/dolphinscheduler/2.0.5/apache-dolphinscheduler-2.0.5-bin.tar.gz
1、下载到服务器
wget https://dlcdn.apache.org/dolphinscheduler/2.0.5/apache-dolphinscheduler-2.0.5-bin.tar.gz2、解压缩
tar -zxvf apache-dolphinscheduler-2.0.5-bin.tar.gz3、更新当前海豚环境
vim apache-dolphinscheduler-2.0.5-bin/conf/config/install_config.conf
vim apache-dolphinscheduler-2.0.5-bin/conf/env/dolphinscheduler_env.sh注意配置ZK注册信息的时候,registryNamespace="dolphinscheduler2"参数配置名称不要和老海豚相同,方便出问题进行回滚。
dolphinscheduler_env.sh 环境变量需要更新。
4、升级数据库和升级版本
sh ./script/upgrade-dolphinscheduler.sh
sh install.sh5、将Mysql驱动搞到lib下
cp 旧海豚_HOME/lib/mysql-connector-java-8.0.16.jar 新海豚_HOME/lib/以上是官方的步骤,下面需要再多执行下约束,解决BUG问题。
6、对新海豚数据库进行加约束。
这个是为了解决BUG(解决下面的问题1),新版本里对工作流版本控制有BUG,会额外写入数据,造成重复数据,导致页面错误和无法切换版本,具体情况看问题1。
ALTER TABLE `dolphinscheduler`.`t_ds_task_definition` ADD CONSTRAINT task_constraint UNIQUE (`code`, `version`);
ALTER TABLE `dolphinscheduler`.`t_ds_task_definition_log` ADD CONSTRAINT task_constraint UNIQUE (`code`, `version`);安装结束后,打开网页就可以看到新版本了。相对1.3.3 。我喜欢这个界面。
那么下面开始是出现的问题了:
问题大全
问题1:版本切换出现:切换工作流版本出错。
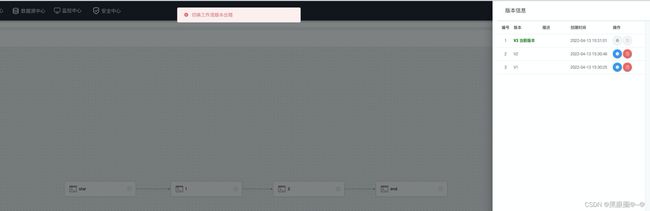
查看日志

这个报错就很明显了。
原因分析:
保存版本的时候触发了某些条件导致异常存在mysql两份相同的数据。
当切换数据的时候,读取到多份相同或者没有返回值的数据。就会报错。
查找t_ds_task_definition和t_ds_task_definition_log实例发现,有两条一模一样的。
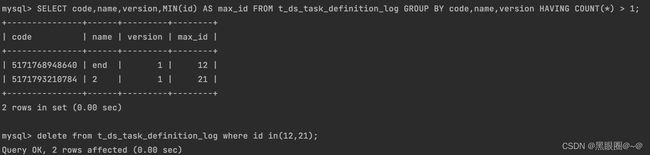
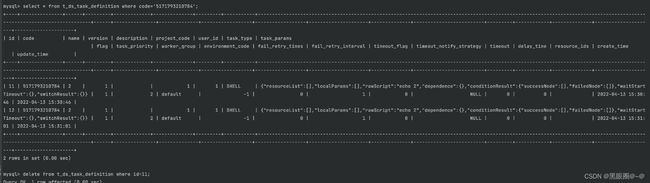
查看并删除重复的数据。然后就可以恢复了。
彻底解决就是加约束:
ALTER TABLE `dolphinscheduler`.`t_ds_task_definition` ADD CONSTRAINT task_constraint UNIQUE (`code`, `version`);
ALTER TABLE `dolphinscheduler`.`t_ds_task_definition_log` ADD CONSTRAINT task_constraint UNIQUE (`code`, `version`);问题2:保存工作流后,出现报错。
这个问题和问题1是一样的,问题1解决,问题2就解决了。
问题3:数据源配置Mysql,提示缺少驱动程序
Failed to load driver class com.mysql.cj.jdbc.Driver in either of HikariConfig class loader or Thread context classloader

因为缺少驱动。 根据官网提示是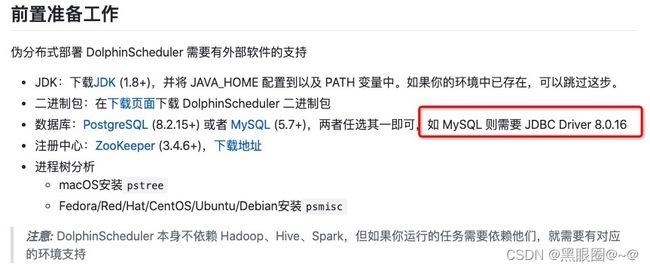
所以去Mysql官网下载:MySQL :: Download MySQL Connector/J (Archived Versions)
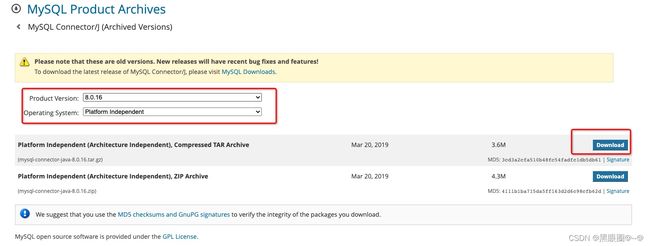
下载完,放到每个海豚节点目录下的lib即可。
问题4:老海豚(1.3.3)项目导入新海豚(2.0.5)异常,无法导入

根据下载的json对比。两边的参数不一样。应该是版本不同参数不同。
问题5:读取元数据发现时间不对
如果需要获取元数据库数据,需要注意时区问题。
jdbc需要加上:serverTimezone=Asia/Shanghai
jdbc:mysql://xxxx:3306/table_name?serverTimezone=Asia/Shanghai&useUnicode=true&charact
或者
Mysql读取时候加上 date_add(时间字段,interval 13 hour)
注意夏季会差13个小时、冬季会差14个小时。
元数据库
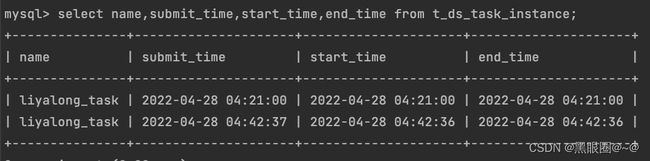
实际执行时间
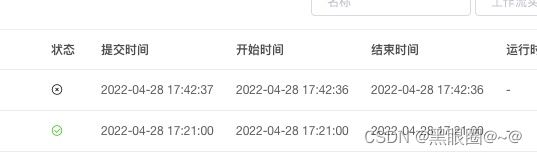
问题6:元数据库升级异常
这个错误挺致命的,这个错误升级会导致升级到2.0.x后,进入到项目界面后,所有的工作流不见了。日志报错信息是: 分页查询工作流定义列表错误。
issues地址:[Bug] [UI] Authorization display exception · Issue #9632 · apache/dolphinscheduler · GitHub
因为元数据库升级是每个版本一层一层升级的,它的升级顺序是
1.3.3->1.3.5->1.3.6->1.3.7->2.0.0->2.0.1->2.0.2->2.0.3->2.0.4->2.0.5。
2022-06-28 16:54:07.155 ERROR 838128 --- [ main] o.a.d.dao.upgrade.UpgradeDao : json split error
java.lang.NullPointerException: null
at org.apache.dolphinscheduler.dao.upgrade.UpgradeDao.splitProcessDefinitionJson(UpgradeDao.java:473) [dolphinscheduler-dao-2.0.5.jar:2.0.5]
at org.apache.dolphinscheduler.dao.upgrade.UpgradeDao.processDefinitionJsonSplit(UpgradeDao.java:405) [dolphinscheduler-dao-2.0.5.jar:2.0.5]
at org.apache.dolphinscheduler.dao.upgrade.UpgradeDao.upgradeDolphinSchedulerTo200(UpgradeDao.java:149) [dolphinscheduler-dao-2.0.5.jar:2.0.5]
at org.apache.dolphinscheduler.dao.upgrade.DolphinSchedulerManager.upgradeDolphinScheduler(DolphinSchedulerManager.java:111) [dolphinscheduler-dao-2.0.5.jar:2.0.5]
at org.apache.dolphinscheduler.dao.upgrade.shell.UpgradeDolphinScheduler$UpgradeRunner.run(UpgradeDolphinScheduler.java:55) [dolphinscheduler-dao-2.0.5.jar:2.0.5]
at org.springframework.boot.SpringApplication.callRunner(SpringApplication.java:791) [spring-boot-2.5.6.jar:2.5.6]
at org.springframework.boot.SpringApplication.callRunners(SpringApplication.java:775) [spring-boot-2.5.6.jar:2.5.6]
at org.springframework.boot.SpringApplication.run(SpringApplication.java:345) [spring-boot-2.5.6.jar:2.5.6]
at org.springframework.boot.builder.SpringApplicationBuilder.run(SpringApplicationBuilder.java:143) [spring-boot-2.5.6.jar:2.5.6]
at org.apache.dolphinscheduler.dao.upgrade.shell.UpgradeDolphinScheduler.main(UpgradeDolphinScheduler.java:39) [dolphinscheduler-dao-2.0.5.jar:2.0.5]
问题就是出在升级1.3.7->2.0.1之间,因为这个阶段新增了表t_ds_task_definition。而这张表在1.3.X的时候是在t_ds_process_definition表里的process_definition_json字段里。2.0.x是从将json字段解析出来放到t_ds_task_definition里。而解析又报错。社区里有人说已经解决了这个问题,但是不太清楚为何我又遇到。
目前我是生产阶段升级遇到这个问题,还好升级使用了双系统,没有影响生产。目前问题正在解决中。
2022-06-28更新:公司618平安度过,没发生啥大幺蛾子。期间做了个海豚的服务监控,如果出现服务宕机直接打电话给负责人。今天有空来解决这个问题了。目前问题已经解决了。
解决思路:查看源码,增加log日志,打印出信息。
问题原因:获取了t_ds_process_definition表的id和信息,传入一个map中
让所有t_ds_process_definition表的json中子依赖SUB_PROCESS的ID去关联map中的Key
因为t_ds_process_definition表的id被删除了,所以map中没有这个id。会关联失败
会显示空指针。来看代码。
下图红框73是指的t_ds_process_definition的id是73.因为工作流被删除了,但是图中工作流子节点依赖没有更改,导致的在map中找不到。

解决方法:将没有上线的都删掉(谨慎,记得要有备份)。保证线上执行的没问题。
delete from t_ds_process_definition where release_state=0;删掉之后再执行升级程序。最终升级成功。
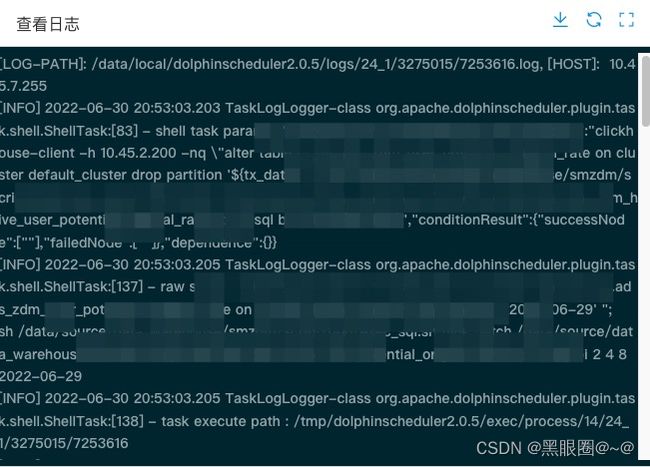
问题7:海豚任务实例只显示LOG-PATH]和HOST。
这种情况一般发生在相同节点启动两套不同版本的海豚。比如我们公司,升级怕影响生产,所以整两套。出现了日志无法看详情。查看日志发现下面报错
这种问题说明了端口冲突。通过lsof-i:50051查看。发现这个端口是被海豚1.3.3使用,导致海豚2.0.5无法使用logger-server端口。

经过查看配置文件没有发现可以修改rpc通信端口的。
这种情况只能通过修改源码了。
org/apache/dolphinscheduler/common/Constants.java

里面50051和50052修改为 50053和50054
然后使用到的服务(下图)重新打包。上传所有海豚节点,替换后重启服务!
有需要打好的包可以私密找我要(如果我还留着的话)。
再查看就正常了。
问题8:工作流实例已上线,但是重跑提示不是上线状态

![]()
看社区的Issue吧 。[Bug] [Workflow Instance] The process definition not on line · Issue #9686 · apache/dolphinscheduler · GitHub
出现这个问题一般是对工作流离线后重新修改再上线。这时候就不识别了。
问题9:海豚调度DEPENDENT组件重大BUG。导致无法依赖。
这个问题特别严重,因为这个问题,我们的生产环境从海豚2回退到海豚1了。
[Bug] [dependent node] Dependent nodes are always blocked · Issue #10443 · apache/dolphinscheduler · GitHub
上游工作流完成的情况下,下游会不断的等待依赖。完全找不到上游任务状态。这个情况导致我们个别生产延迟了6个小时(完犊子了,我这是要被优化的节奏)。
查看master日志发现。完全找不到key。
![]()
原因我直接复制git上大佬的回答
The reason is that all
WorkflowExecuteThreadshare the sametaskRetryCheckListand dependent task checking rely on thetaskRetryCheckList. When a workflow run withfailedstrategy:end tasksand some task failed in the workflow, thetaskRetryCheckListwill be clear including the dependent tasks belong to another workflow. Beacause thetaskRetryCheckListis empty, theStateWheelExecuteThreadcan not generateTASK_STATE_CHANGEany more then the dependent tasks will not be checked any more. So in the UI, the dependent task node are always running and waiting.
翻译:所有
WorkflowExecuteThread共享相同taskRetryCheckList且依赖的任务检查依赖于taskRetryCheckList ,当工作流与工作流一起运行failedstrategy:end tasks并且工作流中的某些任务失败时,taskRetryCheckList将明确包括相关任务属于另一个工作流。因为taskRetryCheckList是空的,所以StateWheelExecuteThread不能再生成TASK_STATE_CHANGE依赖的任务就不会再检查了。所以在 UI 中,依赖的任务节点一直在运行和等待。
简单的说:Master工作流线程有个taskRetryCheckList,这个taskRetryCheckList里有task状态变化和依赖状态。
当任务完成和准备停止状态。都会清空这个taskRetryCheckList。顺带会把依赖检查会清空,贴下2.0.5的源码。
位置:org/apache/dolphinscheduler/server/master/runner/WorkflowExecuteThread.java


这东西每次随机清空的依赖检查。不知道啥时候正好就给清空了依赖。这种不可预测影响生产的肯定不能上线。感觉好像定时炸弹一样。
复现:
1、准备工作:设置3个工作流 A B C
工作流A里有TaskA
工作流B里有TaskB,dependend依赖TaskA
工作流C里有TaskC,是个长任务
2、开始复现
开启工作流B
开启工作流C
关闭工作流C
开启工作流A 等A完成。
B会一直转圈圈。
BUG总结:
1、项目界面,管理员更改所属用户会导致一系列异常展示。
我已经在社区里提issue了。地址:[Bug] [UI] Authorization display exception · Issue #9632 · apache/dolphinscheduler · GitHub
复现方式:
1.使用admin新建项目
2.admin修改用户为普通用户A
3.管理员进入安全中心-用户管理-普通用户A-授权项
4.发现授权项显示异常。有多个相同的项目,它不是真正的权限显示。
5.发现工作流中的依赖显示异常,虽然选择的时候是正确的名字,但是执行后会变成一系列数字。



解决:通过项目页面将用户更改回来,则恢复正常。
这个BUG不影响生产。只是展示有点让大家看不懂。
2、工作流关系图有栈溢出BUG。
复现:工作流之间的依赖会导致这个BUG。比如A->B->C->A
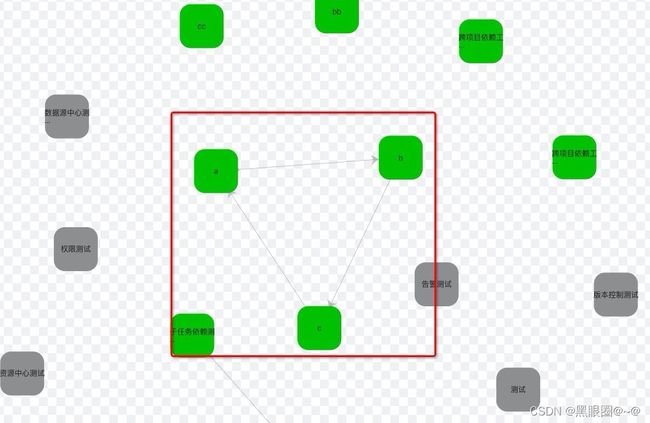
从日志里看应该是自己迭代自己导致了死循环。具体代码没有翻。
3、查看工作流关系图不准确


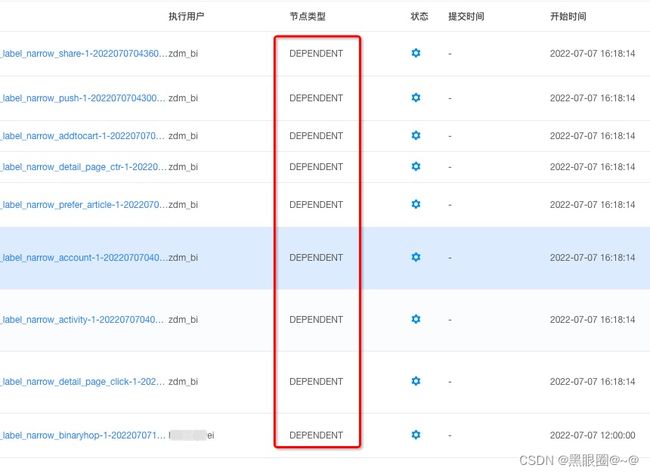
4、升级后DEPENDENT模块依赖显示有问题。
查看依赖是发现是数字。一般这种情况发生在工作流id找不到的情况才会发生。

所以查看元数据。任务流依赖的确是指向的工作流信息
查看工作流表,发现信息没有问题。但是为什么没有找到呢。这个挺奇怪的。
 手动新建一个DEPENDENT,发现无法显示。
手动新建一个DEPENDENT,发现无法显示。
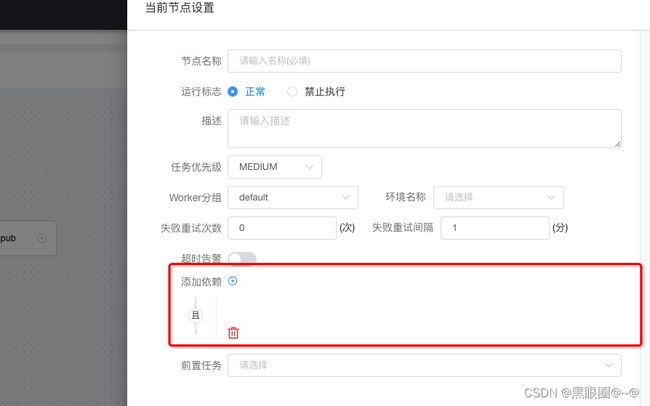
好嘛~~发现规律了,admin创建和执行的,都无法添加依赖,只要是别的普通用户都可以创建依赖。admin用户执行的带有依赖的,也都执行不过去。

目前发现这些问题。后续有问题我更新进来~