LF-Net:Learning Local Features from Images
LF-Net: Learning Local Features from Images
主要贡献
1、无监督,利用利用深度和相对的相机姿态线索来创建一个虚拟目标,网络应该在一张图像上实现这个目标。本来此过程是不可微的。结果表明,该方法可以在保证一个分支可微性的前提下,将网络限制在另一个分支上,从而实现网络的优化。
2、提出稀疏匹配方法,LF-Net,局部特征提取网络;端到端的网络,不需要使用手工提取检测器去生成训练集。我们使用图像对,知道相对姿态和相应的深度映射,在没有任何注释情况下,可以用激光扫描仪或形状结构算法得到。
3、给定密集的对应数据,我们可以训练一个特征提取网络,方法是在两幅图像上选择若干个关键点,计算每个关键点的描述符,使用ground truth确定哪些关键点在图像中正确匹配,并使用这些关键点学习良好的描述符。但这种方法不可行,第一,提取多个分数图的最大值本质上不可微;第二,生成很少ground-truth。因此,建立一个虚拟目标响应,使用不可微ground-truth。特别地,我们在第一张图像上运行检测器,找到最大值,然后优化权重,这样当在第二张图像上运行时,它就会在正确的位置生成一个清晰的响应映射,其中包含清晰的最大值。然后,我们使用ground truth将以这种方式选择的关键点扭曲到另一个图像上,从而保证大量的ground truth匹配。当我们在一个分支中打破可微性时,另一个分支可以端到端进行训练,这让我们通过整个网络来学习有区别的特征。
相关工作
特征提取与匹配主要分为三个阶段:找兴趣点,评估它们的方向,创建特征描述符。SIFT等实现匹配全过程。很多方法由几部分组成,特征点提取,方向评估,特征描述子生成。这种方法的一个问题是,提高一个部分的性能并不一定转化为全面的改进。
Hand-crafed SIFT, SURF[5]使用Haar滤波器和积分图像来快速检测关键点和提取描述符。DAISY[41]通过梯度方向图的卷积高效地计算了稠密描述符。
Learned FAST使用机器学习提取特征,很多早期工作针对特征描述符使用度量学习或凸优化Keypoints 用可重复行来评估,可能会产生误匹配。Descriptors 对光照和几何变化具有鲁棒性,但基准饱和时时不必要的。
本文方法
Detector网络生成一个尺度空间分数图和密集的方向估计,用于选择关键点。用可微采样器(STN)对所选关键点周围的图像块进行裁剪,并将其反馈给Descriptor,对每一个patch产生一个描述符。
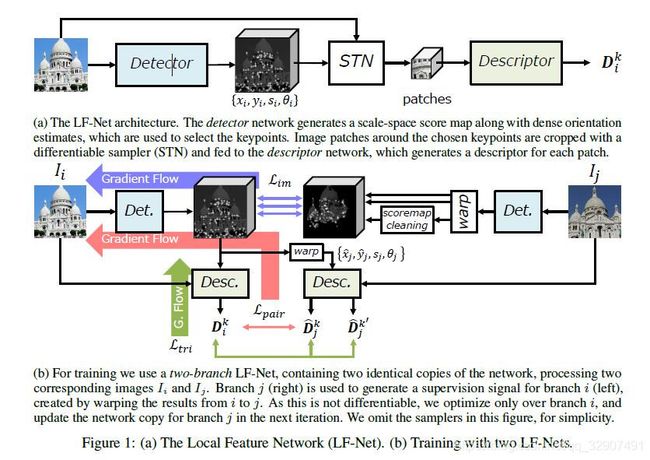
LFNet:a Local Feature Network
LFNet由两部分组成,第一个是一个密集的、多尺度的、fully convolution的网络,它返回关键点位置、尺度和方向。第二个是输出local descriptors的网络,通过给定由第一个网络生成的围绕关键点裁剪的patches。我们称其为detector和descriptor。在本节的其余部分中,我们假设使用相机校准数据的图像没有失真。为了简单起见,我们将它们转换为灰度,使用它们的均值和标准差分别对它们进行标准化。我们将在4.1节中讨论,深度地图和相机参数都可以使用现成的SfM算法获得,由于深度测量常常在三维目标边界附近丢失,特别是当计算的SfM算法,在训练过程中,没有深度测量的图像区域被掩蔽和丢弃。
Feature map generation 我们首先使用fully convolution networks从image I中生成一个丰富的feature map o,这个feature map o可以用来提取关键点的位置及其属性,即尺度和方向。这样做的原因,使用mid-level表征去评估多个量有助于提高深度网络的预测;其次,它允许更大的批次处理,即同时使用更多的图像,这是训练一个鲁棒detector的关键。
实际上,我们采用一个简单的带有三个block的ResNet层,每个Block 包含一个5×5的卷积核并进行BN, leaky-ReLU激活,其他设置为5×5的卷积。所有卷积都是zero-padded的,以具有与输入相同的输出大小,并有16个output channels。在我们的实验中,被证明比依赖与步长卷积和pixel shuffling的结构更有效。
Scale-invariant keypoint detection 为了检测尺度不变的关键点,提出了一种新的基于特征映射o的尺度空间检测方法。为了生成一个尺度空间响应,我们调整了N次大小,在1/R和R之间的均匀间隔,我们的实验中N=5,R = .用N个5×5的卷积核卷积,产生了N个score maps ,1,每个尺度对应一个score map。为了提高关键点的凸性,我们采用卷积的方式在15×15个窗口上应用一个softmax算子来执行非最大抑制的可微形式,这会产生N个更清晰的score maps, 。由于非最大抑制结果与尺度有关,我们重置每一个为原始图像大小,产生我们用一个类似于softmax的操作将所有合并到一个最终的尺度空间score map S中。从而:
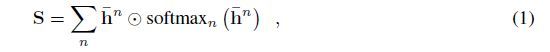
ʘ为哈达玛积。
从这个尺度不变的映射中,我们选择顶部K个像素作为关键点,并进一步应用局部softargmax[8]实现亚像素精度。选择顶部K关键点是不可微的,但通过关键点选择不会阻断反向传播梯度。此外,通过softargmax进行的亚像素细化也使得关于关键点坐标的Graients flow。为了预测每个关键点的尺度,我们只需在的尺度维度上应用一个softargmax操作。一个更简单的替代方法是,一旦检测到一个关键点,就直接regress尺度。但是这个确并没有那么有效。
Orientation estimation 为了学习方向,我们采用了[48,50]的LIFT。方法,但是使用的是共享特征表示o,而不是图像。我们对o应用一个5×5卷积,每个像素输出两个值。它们是方向的正弦和余弦并用arctan函数计算稠密方向图Ɵ。
Descriptor extraction 如上所述,我们从score map S中提取K个得分最高的特征点及其图像位置。通过scale map和orientation map Ɵ ,我们得到了K个四分体,从而可以计算descriptors。
最后,我们考虑选择的关键点位置周围的image patches。我们从标准化的图像中crop它们,并将它们调整为32×32。为了保持可微性,我们采用STN[18]双线性sampling方案进行cropping。我们的descriptor network由3个3×3个卷积滤波器组成,它们的步长为2,通道数分别为64、128和256。每一个卷积进行BN和RELU激活。在卷积层之后,我们有一个fully-connected的512通道层,进行batch归一化,ReLU,一个fully-connected layer将维数降低到M=256。这个descriptors 是L2 normalized,称为D.
Learning LF-Net
我们提出了一个两分支结构的学习问题,该结构以同一场景的两幅图像为输入,和, 以及各自的深度图和摄像机的内、外特性,这些都可以通过传统的SfM方法得到。通过给予这些数据,我们可以对scope maps进行变形,以确定图像之间的ground-truth对应关系。我们的设置的一个显著特征是分支j包含打破可微性的部分,因此不会反向传播,相比传统的Siamese 结构。
我们将训练目标定义为两种类型的损失函数的组合:image-level和patch-level。Keypoint detection 需要image-level操作,还会影响patches的提取,因此我们需要image-level和patch-level损失。对于descriptor网络,我们只使用patch-level的损失,因为一旦选择了关键点,它们将独立地对每个patch进行操作。
Image-level loss 我们warp一个score map用一个刚性变化,使用投影相机模型。我们将其称为SE(3)模块w,除了score maps外,该模块还将摄像机姿态P,校正矩阵K和深度图Z作为输入,对于这两幅图—我们省略了后三幅图,为了简洁。我们提出选择K个关键点从标准的、不可微的、非极大值抑制的 的warped score map中,并生成一个clean score map通过在这些位置放置标准差为0.5的高斯核,。这个操作称为 。值得注意的是,虽然它是不可微的,但它只发生在branch j上,因此对优化没有影响。数学式为:
![]()
Patch-wise loss 在现有方法[3,25,36]中,假设给定一个detector,则在训练前预定义成对关系pool。更重要的是,从两个不相连的关键点集合形成这些pairs将产生太多的异常值,以至于训练无法收敛。最后,我们希望gradients flow回到关键点dectector network,这样我们就能够学习适合匹配的关键点。
为了解决这一问题,我们提出了利用ground truth摄像机的运动和深度,通过warp检测到的关键点,形成稀疏的patch对应。注意,我们只能这样做,当我们warp通过分支j和反向传播通过分支i。
更具体地说,一旦从中选择了K个关键点,我们将它们的空间坐标warp为,就像我们对score map所做的那样,计算image-level的损失,但方向相反。注意,我们从branch j开始用scale和orientation来形成关键点,因为它们不像location那么敏感,我们通过经验发现,这有助于优化。然后我们提取这些对应区域的描述符。如果一个关键点在warping后落在闭塞区域上,我们将其从优化过程中删除。利用这些对应区域及其相关的descriptors ,形成,用于训练detector网络,即关键点、方向和尺度组成。从而:
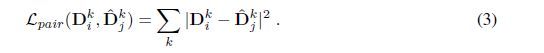
类似地,除了descriptors之外,我们还对检测到的方向和warped点强制进行geometrical consistency(几何一致性)。
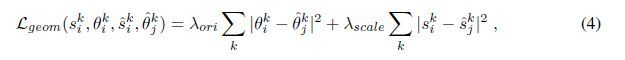
其中和分别表示关键点的warped scale和orientation,利用两幅图像之间的相对相机位姿,为权重。
Triplet loss for descriptors 为了学习descriptor,我们还需要考虑不对应的patch对。我们使用一个triple loss,去学习patches的理想嵌入空间。然而,对于positive pair,我们使用ground-truth几何体来找到匹配,如上所述。对于负的非匹配对,我们采用progressive mining strategy来获取尽可能多的信息patches。具体地说,我们将每个样本的negatives按损失递减的顺序排序,并在M上方随机抽取样本,,k为当前迭代数。我们从64个最困难的样本开始,随着网络的收敛,我们将其减少到最少5个。信息patches采样是学习判别descriptors的关键,random sampling容易产生大量的负样本。
通过匹配对和非匹配对,我们得到triplet loss为:

在这里,,它可以是任何不对应的样本,C=1是边缘。
Loss function for each sub-network.
Detector loss:
Descriptor loss:
Technical details
为了使优化更加稳定,我们在每个分支上翻转图像,并在更新之前合并梯度。我们在这里强调,使用我们的损失,patch-wise loss的梯度可以安全地通过分支i(包括顶部的K选择)反向传播到image-level网络。同样,用于关键点提取的softargmax操作根据关键点的位置允许优化可微的patch-wise loss。
我们保留了网络的一个副本,fig1-(a),简单运行了branch i的可微部分。虽然可微性不再是一个问题,但为了简单起见,我们仍然依赖于空间SoftMax进行非最大值抑制,而softargmax和spatial transformers进行patch采样。
在训练过程中,我们提取了512个关键点,因为较大的数会由于内存限制而产生问题。这还允许我们获得一个包含多个图像对(6)的批处理,这有助于收敛。注意,在测试时,我们可以根据需要选择任意多的关键点。由于带有自然图像的数据集主要由竖直图像组成,因此在方向上存在较大偏差,因此我们通过随机旋转输入patch 正负180度,并相应地变换相机的滚动角度来进行数据增强。我们还通过将输入patches的大小调整到来实现缩放,并相应地转换焦距。这使我们能够训练与传统关键点提取结构类似的模型,即,具有内置的旋转和缩放不变性。然而,在实践中,我们的室内和室外示例中的许多图像是垂直的,通过完全禁用这些增强以及方位ans尺度估计,可以获得性能最好的模型。在下一节中讨论这两种策略。
为了优化,我们使用ADAM,学习率为。为了平衡检测器网络的损耗函数,我们使用了= 0.01和= 0.1。我们的实现是用TensorFlow编写的,并且是公开可用的
Conclusions
我们提出了一种新的学习局部特征的深度架构LF-Net。它嵌入了整个特征提取结构中,并且可以使用一组图像进行端到端的训练。为了让从头开始的训练不需要手工提取,我们设计了一个两分支设置,并迭代地创建虚拟目标响应。我们在一个分支上运行这个不可微过程,同时对另一个分支进行优化,保持可微性,并证明它们收敛于最优解。