【AIGC】3、Visual ChatGPT | 支持图像/文本双输入的对话系统开源啦

文章目录
-
- 一、背景
- 二、Visual ChatGPT
-
- 2.1 对系统规则的提示管理
- 2.2 基础模型的提示管理
- 2.3 . 用户提问的提示管理
- 2.4 基础模型输出的提示管理
- 三、实验
-
- 3.1 实验设置
- 3.2 多轮对话的完整案例
- 3.3 Case Study of Prompt Manager
- 四、当前的局限性
- 五、总结
论文:Visual ChatGPT :Talking, Drawing and Editing with Visual Foundation Models
代码:https://github.com/microsoft/visual-chatgpt
出处:Microsoft Research Asia
时间:2023.03
Visual ChatGPT 是一个能够调动多个不同基础视觉模型来理解视觉信息并生成对应回答的系统。
一、背景
近期, Large Language models(LLMs)发展非常快,如 T5[32]、BLOOM[36]、GPT-3[5] 等。
尤为引起人们注意的是 ChatGPT(基于 Instruct-GPT[29] 而来),能够以真实对话的方式实现和人类的交互。
但是 ChatGPT 是使用语言模型训练的,不适用于图像方面的生成任务。
图像方面,Visual Foundation Models (VFMs) 也有很好的效果,BLIP[22] 能够很好的理解图像并输出对图像的描述, Visual Transformer 和 Stable Diffusion[35] 在图像理解和生成方面有很好的效果。
但上述的先进的语言模型和图像模型只能接收特定模态的输入和输出。而且图像模型有较高的固定输入输出格式,使得图像模型没有语言模型灵活。
能否构建一个类似于 ChatGPT 的系统来实现图像的理解和生成呢?
本文作者提出了一种 Visual ChatGPT,不需要从头开始训练多模态 ChatGPT,而是基于 ChatGPT 和多种 VFMs。
为了弥补 ChatGPT 和这些 VFMs 的 gap,作者又构建了一个提示管理器(Prompt Manager)来支持如下的功能,通过 Prompt Manager 来指导 ChatGPT 使用这些 VFMs,并迭代反馈 :
- 直观的告诉 ChatGPT 这些 VFMs 的能力和输入输出形式
- 将不同的视觉信息,如 png 图像、深度图像、掩码矩阵转换为语言形式的信息帮助 ChatGPT 进行理解
- 处理不同 VFMs 的优先级和冲突
Visual ChatGPT 能够通过如下三步来实现图像模型和语言模型的交互:
- 能够同时接收语言和图像作为输入
- 提供需要多个人工智能模型与多个步骤协作的复杂视觉问题或视觉编辑指令
- 提供反馈意见并告诉系统纠错后的结果,即可以将视觉模型信息注入到 ChatGPT 中,并考虑多个输入/输出的模型和视觉反馈的模型
示例如图 1 所示:
- 用户上传一张黄色花的图片并输入:“请根据预测的图像深度,生成一朵红色的花,然后逐步变成卡通的样子”
- Prompt Manager 可以帮助 Visual ChatGPT 启动相关 VFMs 的执行链,首先使用深度估计模型来检测深度信息,然后利用深度图像模型生成一个红花的深度信息,最后使用风格迁移模型将风格转换为卡通
- Prompt Manager 通过提供可视化的类型和记录信息来记录转换过程,当获得 “卡通” 的提示后,结束整个过程

本文贡献:
- 提出了 Visual ChatGPT,打开了 ChatGPT 和 VFMs 结合的大门,让 ChatGPT 能够处理更复杂的视觉问题
- 设计了一个 Prompt Manager,包含 22 个不同的 VFMs 并且定义了它们之间的内部相关性,以便更好的互动和结合
- 验证了 Visual ChatGPT 对视觉的理解和生成能力
二、Visual ChatGPT
假设一个有 N N N 个 question-answer pairs 的对话系统为 S = { ( Q 1 , A 1 ) , ( Q 2 , A 2 ) , . . . , ( Q N , A N ) } S=\{(Q_1, A_1),(Q_2, A_2),...,(Q_N, A_N) \} S={(Q1,A1),(Q2,A2),...,(QN,AN)}
为了从第 i i i 轮对话中得到响应 A i A_i Ai,需要使用一系列的 VFM 和这些模型的中间输出 A i ( j ) A_i^{(j)} Ai(j)。 j j j 表示第 j j j 个 VFM ( F F F) 的输出。
也就是说在时域 Prompt Manager M M M 协调时, A i ( j ) A_i^{(j)} Ai(j) 的形式需要不断修改来满足每个 F F F 的输入。
最后,如果表示为最终响应,则系统输出 A i ( j ) A_i^{(j)} Ai(j) ,不再执行 VFM。
Visual ChatGPT 的表达形式如下:

- System Principle P P P:系统规则为 Visual ChatGPT 提供了基础规则,需要对图像文件名敏感,能够使用 VFM 来处理图像。
- Visual Foundation Model F F F:Visual ChatGPT 能够很好的组合不同的 VFM( F = { f 1 , f 2 , . . . , f N } F=\{f_1, f_2, ..., f_N\} F={f1,f2,...,fN}),每个基础模型 f i f_i fi 都是具有显式输入和输出的确定函数
- History of Dialogue H < i H_{
- User Query Q i Q_i Qi:Visual ChatGPT 的用户查询包括语言查询和视觉查询
- History of Reasoning R i < j R_i^{
- Intermediate Answer A ( j ) A^{(j)} A(j):复杂查询问题中,Visual ChatGPT 会调用多个不同的 VFM 来逐步获得中间答案,也就会产生多个中间答案
- Prompt Manager M M M:提示管理器会将所有视觉信号转换为语言以便于 ChatGPT 的理解
Visual ChatGPT 的基础视觉模型如下,共 22 个:

2.1 对系统规则的提示管理
Prompt Managing of System Principles M ( P ) M(P) M(P)
Visual ChatGPT 是一个能够调动多个不同 VFMs 来理解视觉信息并生成对应回答的系统。故此,需要很多准则来指导管理器将信息转换为 ChatGPT 能理解的信息。
Prompt Managing (提示管理器)有如下几个作用:
- Visual ChatGPT 的作用:协助完成一系列文本和视觉相关的任务,如视觉问答、图像生成和编辑等
- VFMs 的易用性:Visual ChatGPT 可以访问 VFM 的列表来解决各种 VL 任务。决定使用哪个基础模型完全由 ChatGPT 模型本身决定,因此很容易支持新的 VFM 和 VL 任务。
- 文件名敏感性:Visual ChatGPT 根据文件名访问图像文件,所以,使用精确的文件名很重要,可以避免歧义,因为一轮对话可能包含多个图像及其不同的更新版本和文件名的滥用将导致混乱。因此,Visual ChatGPT 需要使用严格的文件名,以确保它检索和操作正确的图像文件。
- 链式思想:如图 1 所示,要处理一个看似简单的命令,可能需要多个 VFM,例如,查询 “根据预测的图像深度生成一朵红花,然后使其像卡通一样” 需要深度估计、深度到图像和风格转移 VFM。为了通过将查询分解为子问题来解决更具挑战性的查询,在 Visual ChatGPT 中引入了 CoT,以帮助决定、利用和分派多个 VFM。
- 推理格式严格:Visual ChatGPT 必须遵循严格的推理格式。因此,需要用复杂的正则表达式匹配算法来解析中间推理结果,并为 ChatGPT 模型构造合理的输入格式,以帮助它确定下一次执行,例如,触发一个新的 VFM 或返回最终的响应
- 可靠性:作为一种语言模型,Visual ChatGPT 可能会伪造虚假的图像文件名或事实,从而使系统不可靠。为了处理这些问题,Visual ChatGPT 忠实于视觉基础模型的输出,而不是制作图像内容或文件名。此外,多个 VFM 的协作可以提高系统的可靠性,因此构建的提示将指导 ChatGPT 优先利用 VFM,而不是基于对话历史生成结果。

2.2 基础模型的提示管理
Prompt Managing of Foundation Models M ( F ) M(F) M(F)
Visual ChatGPT 中有多个 VFM 来处理各种 VL 任务。这些不同的 VFM 有相似之处,例如:
- 替换图像中的目标可以被视为生成一个新的图像
- Image-to-Text(I2T)任务和图像问题回答(VQA)任务可以理解为根据输入的图像来产生对应的响应
如图 3 所示,提示管理器明确定义了以下各个子提示符,以帮助 Visual ChatGPT 准确地理解和处理 VL 任务:
- Name:名称提示符为每个 VFM 提供了全局函数的抽象,例如,回答关于图像的问题,它不仅能够帮助 Visual ChatGPT 以简洁的方式理解 VFM 的目的,而且也是 VFM 的 entry。
- Usage:使用提示符描述了应该使用 VFM 的特定场景。例如,Pix2Pix 模型[35] 适合于更改图像的样式。提供这些信息有助于Visual ChatGPT 对特定任务使用哪个 VFM 做出决定。
- Inputs/Outputs:输入和输出提示反应了每个 VFM 所需的输入和输出的格式,因为格式可能变化很大,对 Visual ChatGPT 能否正确执行 VFM 有很重要的指导作用
- Example(可选):示例提示符是可选的,但它有助于 Visual ChatGPT 更好地理解如何在特定的输入模板下使用特定的 VFM 并处理更复杂的查询
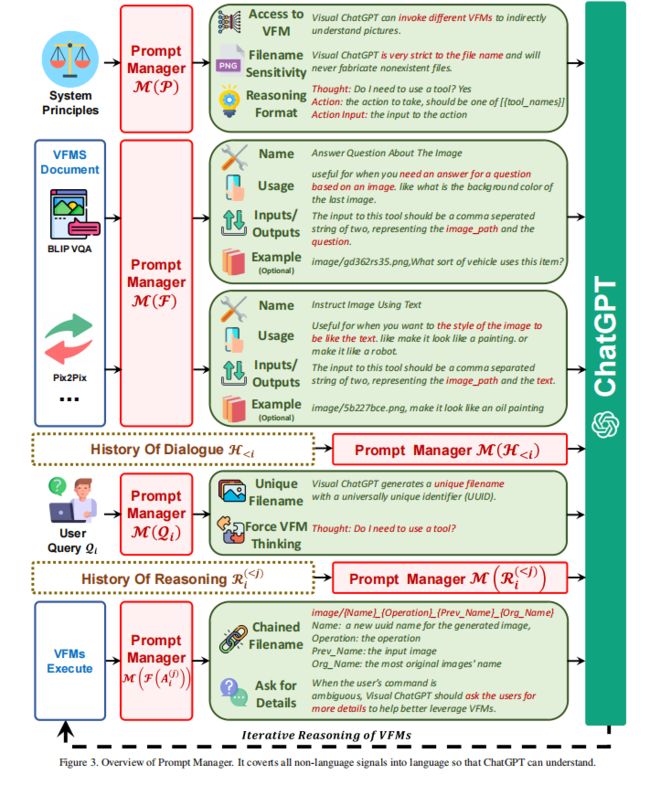
2.3 . 用户提问的提示管理
Prompt Managing of User Querie M ( Q i ) M(Q_i) M(Qi)
Visual ChatGPT 能够支持多种的查询,包括语言和图像的,简单的和复杂的,Prompt 通过如下两个方面来处理用户的查询:
-
Generate Unique Filename
Visual ChatGPT 可以处理两种与图像相关的查询:一种涉及新上传的图像,另一种涉及对现有图像的引用。
对于新上传的图像,Visual ChatGPT 生成一个具有普遍唯一标识符(UUID)的唯一文件名,并添加一个表示相对目录的前缀字符串 “image”,例如,“image/{uuid}.png”。
虽然新上传的图像不会被输入 ChatGPT,但会生成一个虚假的对话历史,其中有一个问题说明图像的文件名,还有一个答案表明图像已经收到。这段虚假的对话历史有助于之后的对话。
对于涉及引用现有图像的查询,Visual ChatGPT 会忽略文件名检查。这种方法已经被证明是有益的,因为 ChatGPT 能够理解用户查询的模糊匹配,如 UUID 名称。
-
Force VFM Thinking
为了确保 Visual ChatGPT 的成功触发 VFM ,在(Qi)中添加了一个后缀提示:“由于 Visual ChatGPT 是一种文本语言模型,Visual ChatGPT 必须使用工具来观察图像,而不是想象。这些思想和观察只在 Visual ChatGPT 中可见,Visual ChatGPT 应该记住在人类的最终反应中重复重要的信息。也会反复思考:我需要使用一个工具吗?”。
这个提示有两个目的:
- 它提示 Visual ChatGPT 使用基础模型,而不是仅仅依赖于它的想象力;
- 它鼓励 Visual ChatGPT 提供由基础模型生成的特定输出,而不是像 “你在这里” 这样的通用响应。
2.4 基础模型输出的提示管理
Prompt Managing of Foundation Model Outputs M ( F ( A i ( j ) ) ) M(F(A_i^{(j)})) M(F(Ai(j)))
对于来自不同 VFM F ( A i ( j ) ) F(A_i^{(j)}) F(Ai(j)) 的中间输出,Visual ChatGPT 能够隐式地总结并将它们提供给 ChatGPT 进行后续交互,即调用其他 VFM 进行进一步的操作,直到达到结束条件或反馈给用户。内部的步骤可以总结如下:
-
Genarete Chained Filename:
由于 Visual ChatGPT 的中间输出将成为下一轮隐式对话的输入,故应该使这些输出更合乎逻辑,以帮助 LLMs 更好地理解推理过程。
具体来说就是从视觉基础模型生成的图像被保存在路径 “image/” 文件夹下。
之后,image 的命名为 :“{Name} {Operation} {Prev Name} {Org Name}”
例如 “image/ui3c_edge-of_o0ec_nji9dcgf.png” 表示输入 o0ec 的一个名为 ui3c 的 canny edge image,且该图像的元素名称为 nji9dcgf。
这样的命名规则可以让 ChatGPT 了解是如何生成的这个图像
-
Call for More VFMs:
Visual ChatGPT 的一个核心是可以自动调用更多的 VFMs 来完成用户的命令。也就是 ChatGPT 会不断询问自己,它是否需要 VFM 来解决当前的问题,在每一阶段结束时扩展一个 VFMs 的后缀。
-
Ask for More Details:
当用户的命令模棱两可时,Visual ChatGPT 应该向用户询问更多的细节,以帮助更好地利用 VFM。这种设计是为了安全考虑,因为 LLMs 不允许毫无根据地任意篡改或推测用户的意图(特别是当输入信息不足时)。
三、实验
3.1 实验设置
使用 ChatGPT [29](OpenAI“文本-数据-003”版本)实现 LLM(Large Language Model),并用 LangChain[7] 指导 LLM。
从 HuggingFace Transformers [43], Maskformer [10] 和 ControlNet [53] 来收集基础模型。
所有 22 个 VFM 全部部署需要 4 个 Nvidia V100 GPU,但用户可以部署更少的基础模型,以灵活地节省 GPU 资源。
聊天历史记录的最大长度为 2000,多余的令牌被截断以满足 ChatGPT 的输入长度。
3.2 多轮对话的完整案例
如图 4 所示,展示了 Visual ChatGPT 的 16 轮多模态对话

3.3 Case Study of Prompt Manager
图 5 展示了 Prompt Manager 相关案例研究
为了验证系统的效率,会从中删除不同的部分来比较模型的性能,每次去除都会导致不同的容量退化。

1、Case Study of prompt managing of foundation models
VFM 的名称是最重要的:
名称需要有明确的定义,当名称缺失或不明确时,Visual ChatGPT 会多次猜测,直到它找到一个现有的 VFM,或遇到一个错误,如图 6 的左上部分所示。
VFM 的使用:
应该清楚地描述应该使用模型以避免错误响应的特定场景。右上角显示了样式转换对替换对象的处理不当。
应准确提示输入和输出格式,以避免参数错误,如左下角所示。
虽然右下角删除了示例提示,但 ChatGPT 也可以总结对话历史和人类意图来使用正确的 VFM,如右下角所示。

2、 Case Study of prompt managing of user query
图 7 上半部分分析了用户查询的提示管理器案例
输入的图像需要有唯一的命名,以避免被覆盖
3、Case Study of prompt managing of model outputs
如图 7 下半部分所示
左下角的图片比较了删除和保留链式命名规则的性能。使用链式命名规则,Visual ChatGPT 可以识别文件类型,触发正确的VFM,并得出文件依赖关系命名规则。
链式命名规则确实有助于 Visual ChatGPT 的理解。
右下角的图片给出了一个当项目推断不明确时要求更多细节的例子,这也表明了系统的安全性

四、当前的局限性
1、强依赖于 ChatGPT 和 VFMs
2、需要不断的提示,会比较耗时,并且学专业的语言和图像的知识
3、实时能力有限
4、token 长度限制可能会限制可使用的语言模型的数量
5、因为 Visual ChatGPT 能够方便的使用基础模型,可能还包括一些远程模型,可能会导致敏感数据泄露
五、总结
本文算是首次将 ChatGPT 和多种计算机视觉基础模型进行结合的案例,通过设计一系列的提示,能够逐步将视觉信息注入 ChatGPT 中,实现对视觉输入的理解和生成。但也有很多限制,比如耗时较长,很依赖于基础模型,执行结果和人类期望是否一致等。


