车万翔:ChatGPT时代,NLPer 的危与机
来自:智源社区
要点速览:
ChatGPT的诞生,源于研究者「暴力美学」的手段。
如果大胆预测,ChatGPT能火几年,我猜可能是2到3年的时间,到2025年大概又要更新换代了。
工业界相较于学术界拥有巨大优势。这种「AI 的马太效应」会造成胜者通吃的局面。更加危急的是,任务、甚至研究领域之间的壁垒被打破了,所有的问题都可以转化为一个「Seq2Seq」问题,计算机视觉等领域的研究者也会逐渐涌入该领域。
与搜索引擎时代类似,如果将 OpenAI 比作当年的 Google,国内也一定会出现 ChatGPT 时代的「百度」。在这之前,许多机构和企业都有机会放手一搏,做出自己的大模型。相较于其它领域的研究者,NLPer 的真正优势可能在于更加了解语言。

车万翔
车万翔博士,哈尔滨工业大学计算学部长聘教授、博士生导师,人工智能研究院副院长,社会计算与信息检索研究中心副主任。国家级青年人才,黑龙江省“龙江学者”青年学者,斯坦福大学访问学者。现任中国中文信息学会计算语言学专业委员会副主任兼秘书长;国际计算语言学学会亚太分会(AACL)执委兼秘书长;中国计算机学会高级会员、曾任YOCSEF哈尔滨主席(2016-2017年度)。在ACL、EMNLP、AAAI、IJCAI等国内外高水平期刊和会议上发表学术论文100余篇,其中AAAI 2013年的文章获得了最佳论文提名奖,论文累计被引6,000余次(Google Scholar数据)。
从NLPer视角大胆预测:ChatGPT还能火多久
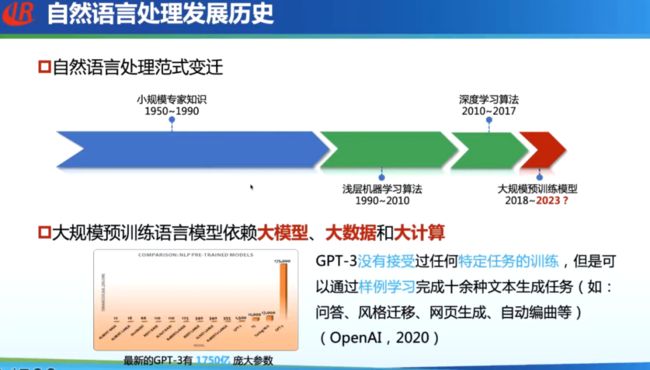
自然语言处理领域的发展历史大致可以分为四个阶段:
基于规则的小规模专家知识(1950-1990)
浅层机器学习算法(1990-2010)
深度学习算法(2010-2017)
大规模预训练模型(2018-2023)
ChatGPT正是遵循着这样一条路,时间线上有一个有趣的预测,每一个阶段的发展的时间,大概是上一个阶段发展时间的一半,基于规则发展了40年,浅层学习做了20年,之后深度学习做了10年,所以预测大规模训练模型发展的时间是5年,恰好到2022年底2023年初,产生了ChatGPT,以及GPT-4即将发布,标志着一个时代的结束。如果大胆预测,ChatGPT能火几年,我猜可能是2到3年的时间,到2025年大概又要更新换代了。当然这是半开玩笑的说法。
ChatGPT效果惊艳的原因:
暴力美学的胜利
大规模预训练模型依赖于大模型,大数据、大算力。以 GPT-3 为例,该模型在没有经受过任何特定任务训练的情况下,可以通过样例学习完成十余种文本生成任务。

然而,相较于 ChatGPT,OpenAI 两年前发布的GPT-3 并没有引起如此之大的关注度。究其原因,其中之一可能是该模型缺乏知识推理能力,可解释性也欠佳。该模型的原始论文指出,该模型在「故事结尾选择」任务上的能力比哈工大丁效老师等人所提出的具有知识推理能力的模型性能低 4.1%。GPT-3 此类预训练语言模型在深层次语义理解能力上与人类认知水平还有很大差距。
为了解决该问题,一些研究者考虑向模型中引入知识;另一些研究者则采取「暴力美学」的手段,并发展出了如今的 ChatGPT。
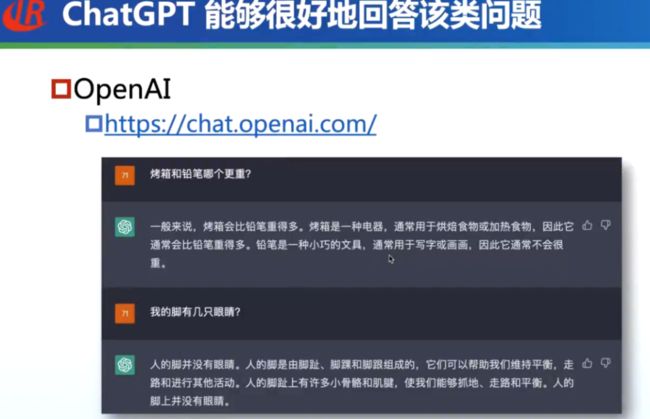
如上图所示,ChatGPT 的效果惊艳,不仅能够给出正确的答案,还具有一定的可解释性。
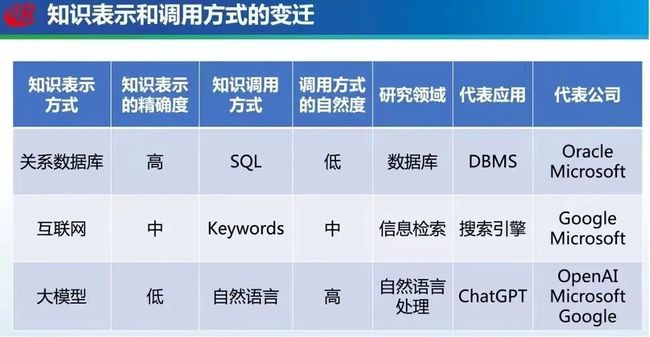
ChatGPT 的成功本质上反映了人们对知识的表示和调用方式产生了重大变革。
在关系型数据库时代,符号化的知识表示精度很高,但是需要使用 SQL 语句调用,较为复杂且不自然,代表性的应用为 DBMS,代表公司为Oracle和微软。
在互联网时代,知识以文字、图像、音频、视频等形式存在,我们通过输入查询关键词来调用知识,代表性的应用为搜索引擎,这个阶段代表公司有谷歌和微软。
在大模型时代,知识表示为大模型及其参数,大模型相当于一个知识库,其知识表示精度较低。在 GPT-3 刚出现时,尽管蕴含大量的知识,但是其调用方式并不自然(构建 Prompt)。ChatGPT 则实现了使用自然语言指令调用知识,这种知识的表示和调用方式是一种根本性的变革。代表公司为OpenAI,微软谷歌以及百度等国内公司也在陆续发力。
ChatGPT的核心技术
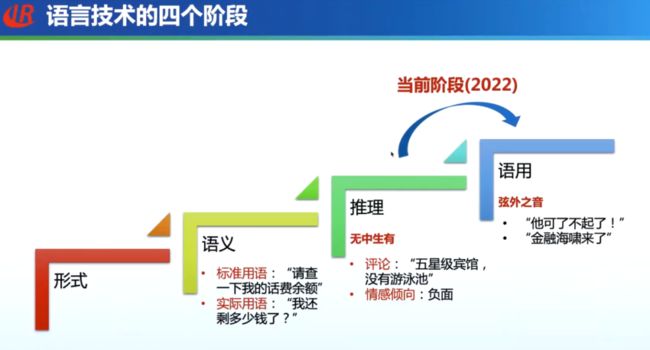
细数语言技术的四个阶段,以 Bert 为代表的预训练语言模型主要解决了语义匹配的问题;ChatGPT 相对较好地解决了推理任务;下一阶段,自然语言处理算法需要考虑语用问题,对于同样的语言输入,模型需要理解不同语气、表情、语音、语调所蕴含的不同意义。
具体技术进展方面,ChatGPT 的核心技术主要包含以下四点:
大规模预训练模型:涌现出推理能力;
Prompt/Instruction Tuning:通过 Prompt 统一各种任务,在众多类型任务的标注数据上精调语言模型,处理未见任务;
在代码上进行继续预训练:涌现出逐步推理能力,代码分步骤、分模块解决问题,代码语言模型需要更长的上下文;
基于人类反馈的强化学习 RLHF:结果更符合人类预期,利用真实用户的反馈。这些技术的融合形成了惊艳的效果。

NLP学术界如何应对
ChatGPT的挑战
在 ChatGPT 时代,自然语言处理领域的发展趋势与早年间的信息检索领域类似。随着搜索引擎的出现,这种系统级别的研究为学术界带来了巨大的危机,学术界可做的研究越来越少。信息检索领域的顶会 SIGIR 相较于其它 AI 顶级会议的论文发表数量要少得多。与此同时,工业界由于掌握了大量的计算资源、用户数据、用户反馈,相较于学术界拥有巨大的优势。这种「AI 的马太效应」会造成胜者通吃的局面。更加危急的是,任务、甚至研究领域之间的壁垒被打破了,所有的问题都可以转化为一个「Seq2Seq」问题,计算机视觉等领域的研究者也会逐渐涌入该领域。

为了应对当前的挑战,自然语言领域的研究者可以借鉴信息检索研究者的经验。首先,学术界可能不再进行系统级别的研究,主要集中在相对边缘的研究方向上;其次,使用工业界巨头提供的数据进行实验,并不一定能得出可靠的结论,由于存在隐私问题,数据的真实性存疑;通过调用公司提供的 API 进行研究,一旦模型被调整,其结论有可能也会改变。
与搜索引擎时代类似,如果将 OpenAI 比作当年的 Google,国内也一定会出现 ChatGPT 时代的「百度」。在这之前,许多机构和企业都有机会放手一搏,做出自己的大模型。相较于其它领域的研究者,NLPer 的真正优势可能在于更加了解语言。
本文整理自「青源Workshop(第20期)|LLM and Chatbot: Endgame, Worse is Better, How to Win Big 」闭门研讨会的引导报告环节,哈尔滨工业大学教授车万翔介绍了ChatGPT效果惊艳的原因,以及ChatGPT时代NLP研究者面临的机遇与挑战。
进NLP群—>加入NLP交流群