Python数据存取详解
一、表格类数据获取
pandas模块中的read_csv()函数和read_execl()函数分别读取csv文件和Excel工作簿中的表格类数据,read_html()函数可以从网页上读取表格类数据。
1、读写csv文件
CSV文件的规范:
- 使用回车换行(两个字符)作为行分隔符,最后一行数据可以没有这两个字符。
- 标题行是否需要,要双方显示约定
- 每行记录的字段数要相同,使用逗号分隔。逗号是默认使用的值,双方可以约定别的。
- 任何字段的值都可以使用双引号括起来. 为简单期间,可以要求都使用双引号。
- 字段值中如果有换行符,双引号,逗号的,必须要使用双引号括起来。这是必须的。
- 如果值中有双引号,使用一对双引号来表示原来的一个双引号
csv文件可以使用记事本或excel软件打开,excel软件会自动按照csv文件规则加载csv文件。
例如某一行如下:
12,aa,"12,aa"它表示了3列,第1列为“12”字符串,第2列为“aa”字符串,第3列为“12,aa”字符串。
另外需要说明的是写入writer.writerow()函数接收的是列表参数,无论是什么数据都会先迭代转化为列表再一次打印输出。所以当传入字符串时。例如’aaaaa’,函数内部会先叠在成[‘a’,‘a’,‘a’,‘a’,‘a’]再打印输出,所以在csv中结果就会是’a’,‘a’,‘a’,‘a’,‘a’
csv模块读写csv文件
使用python3.6环境测试,python读写csv文件:
import csv
print("=============python操作csv文件=================")
#将要存储的数据
DATA = (
(11, '12', '32——1'),
(21, '22', '22——1, 22——2',),
(31, '32', '32——1, 32——2,'),
)
#将数据写到csv
f = open('test.csv', mode='w',encoding='gbk',newline='') #mode写入模式,采用b的方式处理可以省去很多问题。encoding编码。newline=''定义文档换行符
writer = csv.writer(f) #获取输出数据流
for record in DATA: #遍历写入每一行
#csv模块会将所有要写入的对象转化为字符串再写入。若转化后的字符串中不包含分割符(默认逗号),则写入文件中字符串不包含""。若转化后的字符串中包含分割符(默认逗号),则写入文件中字符串包含""
writer.writerow(record) #按行写入文件,会自动将元素对象转化为字符串。写完一行就会添加一个newline换行符。若采用b模式写入,只能写入字节流。
f.close()
#读取csv
f = open('test.csv',mode='r',encoding='gbk') #mode读取模式,采用b的方式处理可以省去很多问题,encoding编码方式
reader = csv.reader(f) #获取输入数据。把每一行数据转化成了一个list,list中每个元素是一个字符串
for row in reader: #按行读取文件。一行读取为字符串,在使用分割符(默认逗号)分割成字符串列表,对于包含逗号,并使用""标志的字符串不进行分割
print(row)
print(type(row))
f.close()除了使用csv模块,还可以使用pandas模块。
read_csv函数包含很多参数,用于控制读取csv文件:
filepath_or_buffer 表示文件系统位置、URL、文件型对象的字符串
sep=sep, 用于对行中各字段进行拆分的字符序列或正则表达式
delimiter=None,
# 列和行的索引和名称
header='infer',用作列名的行号,默认为0,如果没有header行就应该设置为None
names=None, 用于结果的列名列表,结合header=None
index_col=None, 用作行索引的列编号或列名。可以是单个名称/数字或由多个名称/数字组成的列表(层次化索引)
usecols=None,
squeeze=False, 如果数据经解析后仅含一列,则返回Series
prefix=None,
mangle_dupe_cols=True,
# 解析配置
dtype=None,
engine=None,
converters=None, 由列号/列名跟函数之间的映射关系组成的字典。例如{'foo':f}会对foo列的所有值应用函数f
true_values=None,
false_values=None,
skipinitialspace=False,
skiprows=None, 需要忽略的行数(从文件开始处算起),或需要跳过的行号列表(从0开始)
nrows=None, 需要读取的行数
# 缺失数据的处理
na_values=None, 一组用于替换NA的值
keep_default_na=True, 如果连接多列解析日期,则保持参与连接的列,默认为False
na_filter=True,
verbose=False, 打印各种解析器输出信息
skip_blank_lines=True,
# 时间处理
parse_dates=False, 是否尝试将数据解析为日期,默认为False
infer_datetime_format=False,
keep_date_col=False, 如果连接多列解析日期,则保持参与连接的列。默认为False
date_parser=None, 用于解析日期的函数
dayfirst=False, 当解析有歧义的日期时,将其看做国际格式(例如,7/6/2012 -> June 7,2014)。默认为False
# 迭代
iterator=False, 返回一个TextParser以便逐块读取文件
chunksize=None, 文件块的大小(用于迭代)
# 引用压缩文件格式
compression='infer',
thousands=None, 千分位分隔符
decimal=b'.',
lineterminator=None,
quotechar='"',
quoting=csv.QUOTE_MINIMAL,
escapechar=None,
comment=None, 用于将注释信息从行尾拆分出去的字符(一个或多个)
encoding=None, 用于unicode的文本编码格式
dialect=None,
tupleize_cols=False,
# 错误处理
error_bad_lines=True,
warn_bad_lines=True,
skipfooter=0, 需要忽略的行数(从文件末尾算起)
skip_footer=0, # deprecated
# 内置属性
doublequote=True,
delim_whitespace=False,
as_recarray=False,
compact_ints=False,
use_unsigned=False,
low_memory=_c_parser_defaults['low_memory'],
buffer_lines=None,
memory_map=False,
float_precision=None
在python3.6环境下:
print("==============pandas操作csv文件==================")
import pandas as pd
#pandas将数据写入csv文件
DATA = {
'english': ['one','two','three'],
'number': [1,2,3]
}
save = pd.DataFrame(DATA,index=['row1','row2','row3'],columns=['english','number'])
print(save)
save.to_csv('test1.csv',sep=',')
#pandas读取csv
# sep分隔符,encoding编码header=None自动列名,names自定义列名,index_col作为行索引的列(主键),skiprows跳过行索引,na_values缺失值的替代字符串
df = pd.read_csv('test1.csv',sep=',',encoding='gbk',names=['column1','column2','column3'],index_col=['column1'],skiprows=[0],na_values=['NULL'])
print(df)
2、读写xls文件
前提条件是电脑已经安装了office办公软件,并且下载安装了pywin32-217.win32-py2.7库。
1. 库安装
1)安装python库
window下python2、python3安装包的方法:
在线安装
安装好python、设置好环境变量后,在python安装目录下Script文件夹内会存在pip.exe和easy_install.exe两种在线安装工具。
只需要在cmd输入pip,可以查看pip是否可用
没有报错表示可用,在cmd中输入pip install xxx就可以在线安装包了,xxx为你要安装的包的名称。如在线安装lxml包,只需要在cmd中输入pip install lxml。即可
在线更新
pip install --upgrade 库名在cmd中输入pip install --upgrade xxxx就可以在线更新库了,xxx为你要更新的库的名称。如在线更新lxml包,只需要在cmd中输入pip install --upgrade lxml。即可
离线安装
window下python的包两种形式存在,一种以.whl文件形式存在,一种以文件夹形式存在,在文件夹下一般与一个setup.py文件。下面介绍如何安装这两种形式的包。
在安装过程中,很多包是有依赖包的,必须先安装好依赖包才能安装成功当前包。联网电脑,会自动下载安装所依赖的包,所以问题不大,对于不能联网的电脑,就只能根据错误提示,一点一点下载安装所依赖的包。
python包库的下载地址:PyPI · The Python Package Index
2)安装python3的包
如果是whl格式的包:
将whl文件放在C:\Program Files\Python35-32\Scripts文件夹下。
先cd到目录(在cmd中输入):
cd \Program Files\Python35-32\Scripts再安装包(在cmd中输入,xx换成你的文件名):
pip install xx.whl如果是文件夹形式的包:
将文件夹放在C:\Program Files\Python35-32\Scripts文件夹下。
先cd到文件夹目录(在cmd中输入,xx换成你的文件夹名称):
cd \Program Files\Python35-32\Scripts\xx
再执行安装(在cmd中输入):
python setup.py install3)安装python2的包
如果是whl格式的包:
将whl文件放在C:\Python27\Scripts文件夹下。
先cd到目录(在cmd中输入):
cd \Python27\Scripts
再安装包(在cmd中输入,xx换成你的文件名):
pip install xx.whl如果是文件夹形式的包:
将文件夹放在C:\Python27\Scripts文件夹下。
先cd到文件夹目录(在cmd中输入,xx换成你的文件夹名称):
cd \Python27\Scripts\xx
再安装包(在cmd中输入):
python setup.py install注意:
对于部分无法引入的包,需要在对应的安装包目录下运行自定义脚本
如:scapy包按照上述方式安装成功,但是无法正常引入,需要将自定义的脚本文件放在
C:\Python27\Scripts\scapy-master文件夹下执行
4)Python库的卸载
卸载使用:
pip uninstall [packge]卸载完成之后到.\Lib\site-packages目录下检查package文件夹是否还在,如果还在,删除之【注意此时必须关闭python或者ipython】。
2. python操作office办公软件(excel)
使用python编程操作excel软件了,excel软件的启动可能会比较慢,所以有可能要等待几秒才能启动成功。
python2.7下代码:
#coding:utf-8
#python控制excel软件,本机电脑需要安装office软件
from Tkinter import Tk
from time import sleep
from tkMessageBox import showwarning
import win32com.client as win32
warn = lambda app: showwarning(app, 'Exit?') #弹出提示框
def excel():
app = 'Excel'
xl = win32.gencache.EnsureDispatch('%s.Application' % app) #创建excel对象
ss = xl.Workbooks.Add() #添加一个工作簿
sh = ss.ActiveSheet #取得活动(当前)工作表
xl.Visible = True #设置为桌面显示可见
sleep(1) #暂停一下,让用户看清演示的每一步
sh.Cells(1,1).Value = 'first line'
sleep(1) #暂停一下,让用户看清演示的每一步
for i in range(3, 8):
sh.Cells(i,1).Value = 'line %d' % i #在3到8行,第一列,写入内容
sleep(1) #暂停一下,让用户看清演示的每一步
sh.Cells(i+2,1).Value = "last line"
sh.Range(sh.Cells(1, 1), sh.Cells(4, 1)).Font.Bold = True #设置指定区域的字体格式
warn(app) #弹出警告消息
ss.Close(False) #工作簿关闭保存
xl.Application.Quit() #excel应用退出
if __name__=='__main__':
Tk().withdraw() #不让tk顶级窗口出现,因为默认tk会自动创建一个顶级窗口,而且不会将其隐藏
excel()
python3.6下代码:
#coding:utf-8
#python控制excel软件,本机电脑需要安装office软件
from tkinter import Tk
from time import sleep
from tkinter.messagebox import showwarning
import win32com.client as win32
warn = lambda app: showwarning(app, 'Exit?') #弹出提示框
def excel():
app = 'Excel'
xl = win32.gencache.EnsureDispatch('%s.Application' % app) #创建excel对象
ss = xl.Workbooks.Add() #添加一个工作簿
sh = ss.ActiveSheet #取得活动(当前)工作表
xl.Visible = True #设置为桌面显示可见
sleep(1) #暂停一下,让用户看清演示的每一步
sh.Cells(1,1).Value = 'first line'
sleep(1) #暂停一下,让用户看清演示的每一步
for i in range(3, 8):
sh.Cells(i,1).Value = 'line %d' % i #在3到8行,第一列,写入内容
sleep(1) #暂停一下,让用户看清演示的每一步
sh.Cells(i+2,1).Value = "last line"
sh.Range(sh.Cells(1, 1), sh.Cells(4, 1)).Font.Bold = True #设置指定区域的字体格式
warn(app) #弹出警告消息
ss.Close(False) #工作簿关闭保存
xl.Application.Quit() #excel应用退出
if __name__=='__main__':
Tk().withdraw() #不让tk顶级窗口出现,因为默认tk会自动创建一个顶级窗口,而且不会将其隐藏
excel()
3. xls文件的读写与追加
xlwt只能创建一个全新的excel文件,然后对这个文件进行写入内容以及保存。但是大多数情况下我们希望的是读入一个excel文件,然后进行修改或追加,这个时候就需要xlutils了。
使用xlwt库,点击下载xlwt库 或者pip install xlwt
使用xlrd库,点击下载xlrd库 或者pip install xlrd
使用xlutils库,使用pip install xlutils安装
然后就可以处理excel文件了。
python3.6下xls文件的读写:
#xls文件的读写
import xlwt
import xlrd
import xlutils
#将数据写入xls
workbook=xlwt.Workbook(encoding='utf-8') #文件编码
booksheet=workbook.add_sheet('Sheet 1', cell_overwrite_ok=True) #表名,是否覆盖
DATA=(('学号','姓名','年龄','性别','成绩'),
('1001','A','11','男','12'),
('1002','B','12','女','22'),
('1003','C','13','女','32'),
('1004','D','14','男','52'),
)
for i,row in enumerate(DATA): #迭代
for j,col in enumerate(row): #迭代
booksheet.write(i,j,col) #写入单元格
workbook.save('test.xls') #保存成文件
#将数据追加到xls
from xlrd import open_workbook
from xlutils.copy import copy
rexcel = open_workbook("test.xls") # 用wlrd提供的方法读取一个excel文件
rows = rexcel.sheets()[0].nrows # 用wlrd提供的方法获得现在已有的行数
excel = copy(rexcel) # 用xlutils提供的copy方法将xlrd的对象转化为xlwt的对象
table = excel.get_sheet(0) # 用xlwt对象的方法获得要操作的sheet
values = ["1", "2", "3"]
row = rows
for value in values:
table.write(row, 0, value) # xlwt对象的写方法,参数分别是行、列、值
table.write(row, 1, "haha")
table.write(row, 2, "lala")
row += 1
excel.save("test.xls") # xlwt对象的保存方法,这时便覆盖掉了原来的excel
#从xls中读取数据
fname = "test.xls"
data = xlrd.open_workbook(fname)
shxrange = range(data.nsheets)
try:
sh = data.sheet_by_name("Sheet 1")
nrows = sh.nrows
ncols = sh.ncols
print("hang %d, ncols %d" % (nrows, ncols))
for row_index in range(sh.nrows):
for col_index in range(sh.ncols):
print(sh.cell(row_index, col_index).value,end='')
print('')
except:
print("no sheet in %s named Sheet1" % fname)
3、html文件读写
1. 用于构建表格的标签
read_html()函数是通过定位网页源代码中所有用于构建表格的标签来读取数据的,因此,下面先来简单了解一下用于构建表格的标签。
| 标签定义一行中的一个单元格。在 | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| 标签定义一行中的一个单元格。
在PyCharm编辑器中创建一个“test.html”文件,以该文件为基础进行网页源代码的修改和添加,得到如下所示的网页源代码: 使用谷歌浏览器打开“test.html”文件,可看到如下图所示的表格:
2. read_html()函数的基本用法 代码文件:read_html()函数的基本用法.py 认识了用于构建表格的标签,下面从read_html()函数的常用参数入手,讲解该函数的基本用法。 1)参数io 参数io的值可以是网址或本地HTML文档的路径,也可以是requests模块获取到的响应对象的文本内容。该参数是位置参数,在函数的括号中书写时不用给出参数名,但必须为第一个参数。 演示代码如下: read_html()函数的返回值是DataFrame对象的列表,每个DataFrame对象代表页面中的一个表格,第2行代码通过列表切片的方式指定提取第1个表格。 代码运行结果如下图所示:
2)参数match 参数match的值是一个正则表达式,只有含有符合该正则表达式的字符串的表格才会被返回,如果匹配不到则会报错。 演示代码如下: 第2行代码中的match='优'表示读取包含字符串'优'的表格。 代码运行结果如下图所示:
3)参数flavor 该参数用于指定网页源代码的解析器,默认为lxml解析器。 演示代码如下: 4)参数header 参数header用于指定以表格中的一行或几行数据作为表格的列标签,默认值是None。参数值可以是单个整型数字,表示将一行数据作为列标签;也可以是由整型数字组成的列表,表示将几行数据共同作为列标签。 演示代码如下: 代码运行结果如下图所示。
5)参数index_col 参数index_col用于指定表格中的一列数据作为行标签,默认值为None。 演示代码如下: 代码运行结果如下图所示:
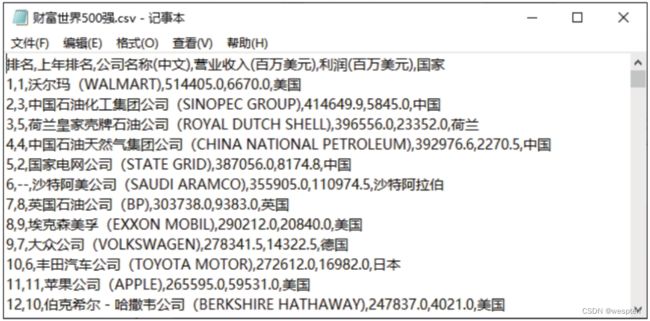
6)参数encoding 参数encoding用于指定表格数据的解码方式,默认使用网页源代码提供的解码方式,一般不需要指定。 学习了read_html()函数的基本用法,下面以爬取财富中文网的2019年财富世界500强排行榜(http://www.fortunechina.com/fortune500/c/2019-07/22/content_339535.htm)为例进行实践。 在编写代码前,需要先利用开发者工具确定网页中的数据是静态加载还是动态加载。如果是静态加载,只需要将网页的网址作为read_html()函数的参数io的值;如果是动态加载,则要先用requests模块携带动态参数获取网页源代码,再将其作为read_html()函数的参数io的值。这里确定网页中的数据是静态加载的,所以演示代码如下: 用记事本打开保存的csv文件,结果如下图所示:
4、python对象与json字符串转换在json字符串和python对象的相互转化中,会进行下列变换:
反过来也是对应转换。 python字典所有的键必须为字符串,值可以是任何对象。包括字典、列表、字符串、数值、布尔值以及null。 json库集成在了标准库中,使用import json即可引入,所以不用安装外部包。 1. python对象转化为json字符串、python对象存储成json文件 json.dumps 将 Python 对象编码成 JSON 字符串: dumps函数包含一些参数,可以使用参数让 JSON 数据格式化输出。
json.dump 将 Python 对象存储成 JSON文件: 测试用例。运行环境python3.6: 注意:测试发现,使用str(dict),转化为字符串为单引号,使用json.dumps转化为字符串为双引号。 2. json字符串转化为python对象,python读取json文件 json.loads 将已编码的 JSON 字符串解码为 Python 对象: json.load 将已编码的 JSON 文件解码为 Python 对象: 测试用例。运行环境python3.6: 二、数据库存取数据当数据量非常大时,在海量文件中查找数据会很麻烦,所以我们需要一个工具来帮助管理数据,那就是数据库。 数据库可以视为一个存放数据的仓库,一个数据库中能存放多张数据表。根据数据表的类型可以将数据库分为关系型数据库和非关系型数据库两类。 关系型数据库中存放的数据表和我们常见的二维表格很相似。二维表格的行在数据表中称为记录,二维表格的列在数据表中称为字段,列名则称为字段名。与二维表格不同的是,数据表的字段有着严格的约束,只能存储指定格式和长度的数据,因此,关系型数据库更适合用于存取结构化的数据。关系型数据库意味着数据库中存放的数据表之间可以产生联系,通过一定的方式用一张表的数据找到另一张表中的数据。例如,学生表中存放了学生的姓名、联系方式等数据,成绩表中存放了学生的姓名、分数等数据,因为两张表中都存在学生的姓名数据,所以可以通过同一个姓名值让两张表产生联系。 非关系型数据库意味着每个数据之间是独立的,常见的类型是键值对关系,只能通过键取到对应数据的值。 数据库管理系统是专门为创建和管理数据库而设计的软件。在爬虫中常用的关系型数据库管理系统有Oracle、SQL Server、MySQL,非关系型数据库管理系统有Redis、memcached、MongoDB。 1、Python操作MySQL数据库1. MySQL的安装和配置 MySQL能在Windows环境下运行,性能卓越,服务稳定,并且体积小、速度快、成本低,支持多种开发语言。国内很多中小型网站为了降低成本都使用MySQL存储数据。下面就来讲解MySQL的安装与配置。 步骤1:在浏览器中打开MySQL的下载页面https://downloads.mysql.com/archives/installer/,选择下载运行于Windows操作系统的5.6.45版本,可看到有两个安装包,第一个是网络安装版,第二个是离线安装版,这里单击离线安装版的“下载”按钮,如下图所示:
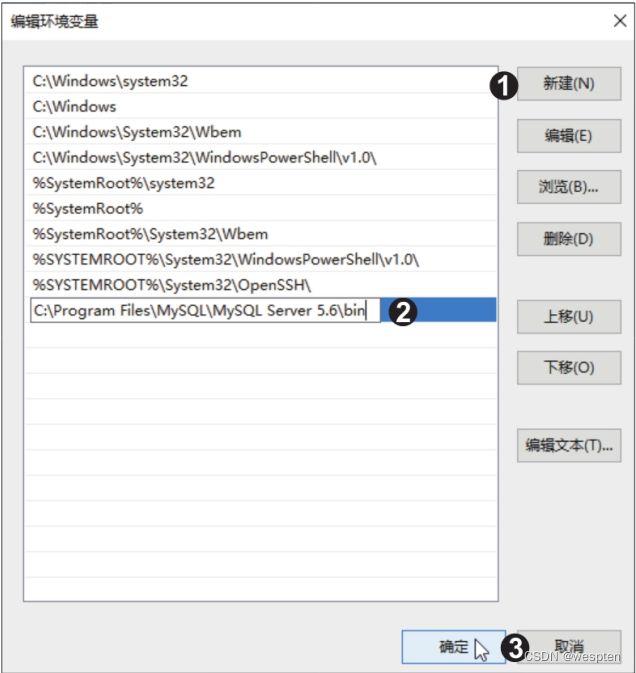
安装包下载完毕后,用搜索引擎搜索详细的安装教程,按照安装教程完成安装。 安装完毕后,为便于在命令行窗口中操控MySQL,还要将“mysql.exe”所在的文件夹路径添加到系统的环境变量Path中。具体方法为:按快捷键【Win+R】打开“运行”对话框,输入“sysdm.cpl”后按【Enter】键,打开“系统属性”对话框;切换到“高级”选项卡,单击“环境变量”按钮,打开“环境变量”对话框;在“系统变量”列表框中双击“Path”选项,打开“编辑环境变量”对话框。 单击“新建”按钮,在文本框中粘贴“mysql.exe”所在的文件夹路径,单击“确定”按钮,如下图所示:
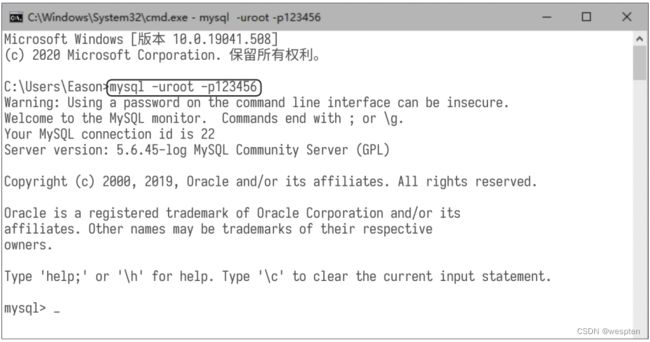
完成设置后,按快捷键【Win+R】打开“运行”对话框,输入“cmd”后按【Enter】键,在弹出的命令行窗口中输入命令“mysql”,按【Enter】键,即可启动MySQL服务。随后在命令行窗口中输入命令“mysql --version”,按【Enter】键,如果显示系统版本号,则说明安装成功。 步骤2:使用安装时配置的管理员账户和密码登录MySQL系统。打开命令行窗口,输入命令“mysql -uroot -p123456”(其中-u代表user,后面跟用户名;-p代表password,后面跟密码),按【Enter】键,即可登录本地MySQL系统,并显示命令提示符“mysql>”,如下图所示。
如果要通过网络登录运行在其他计算机上的MySQL系统,则要输入命令“mysql -uroot -p123456 -h192.168.31.1 -P3306”,其中,-h后为MySQL系统所在计算机的IP地址,-P后为MySQL服务的端口号。 步骤3:登录系统后就可以创建数据库了。在命令提示符“mysql>”后输入并执行命令“CREATE DATABASE test CHARSET=utf8;”(注意不要遗漏末尾的分号),即可创建一个名为test、数据编码格式为UTF-8的数据库。这里指定数据编码格式为UTF-8是为了避免中文数据出现乱码。如果要显示所有数据库的列表,可使用命令“SHOW DATABASES;”,如下图所示。
步骤4:创建数据库后还需要在数据库中创建数据表。先使用命令“USE test;”进入前面创建的数据库test,再使用命令“CREATE TABLE demo(id INT(10) NOT NULL PRIMARY KEY, name VARCHAR(10) NOT NULL);”创建一个名为demo的数据表(命令的具体含义在后面会详细讲解)。此时使用命令“SHOW TABLES;”可以列出当前数据库中的所有数据表,如下图所示。
步骤5:MySQL支持多个用户同时使用,但是管理员账户只能有一个。通过管理员账户可以新建用户并管理用户权限。对于不同级别的用户需要分配不同的权限,常见的权限是数据的“增”“删”“改”“查”四种,其中需要慎重考虑的是数据的删除权限,因为数据一旦被删除就不容易恢复。下面来新建一个用户mrwang,并为其分配权限。 用步骤2中的方法以管理员账户登录系统,输入并执行命令“CREATE USER 'mrwang'@'192.168.31.1' IDENTIFIED BY '123456';”,其中mrwang是用户名,192.168.31.1是该用户登录时可使用的IP地址(通常为本机的IP地址),123456是密码。随后可使用命令“SELECT host, user FROM mysql.user;”查看所有用户的IP地址和用户名信息,如下图所示。
设置用户登录的IP地址时可以使用通配符“%”。例如,'192.168.31.%'表示允许用户从所有以“192.168.31.”开头的IP地址登录,'%'则表示允许用户从任意IP地址登录。 刚创建的用户是没有权限操作数据库的,还需要对其进行授权。继续输入并执行命令“GRANT SELECT, INSERT, UPDATE, DELETE ON test.demo TO 'mrwang'@'192.168.31.1';”,如下图所示。其中SELECT表示查询的权限,INSERT表示增加的权限,UPDATE表示修改的权限,DELETE表示删除的权限,test是数据库的名称,demo是数据表的名称。这条命令就表示授权用户mrwang对数据库test中的数据表demo进行“增”“删”“改”“查”操作。
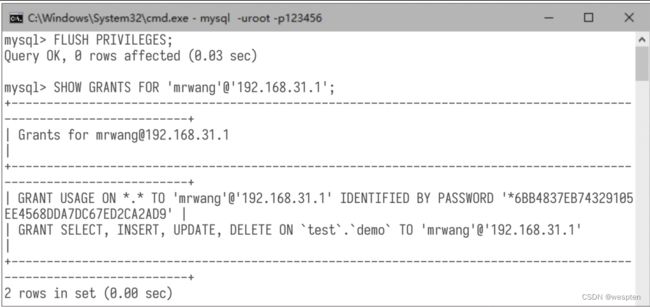
授予的权限要刷新才能生效,对应的命令为“FLUSH PRIVILEGES;”。再使用命令“SHOW GRANTS FOR 'mrwang'@'192.168.31.1';”查看用户mrwang的权限,如下图所示。
设置用户有权操作的数据库和数据表时可使用通配符“*”。例如,test.*表示数据库test中的所有数据表,*.*表示所有数据库中的所有数据表。设置权限时可用ALL PRIVILEGES代表所有权限。例如,命令“GRANT ALL PRIVILEGES ON *.* TO 'mrwang'@'192.168.31.1';”就表示授权用户mrwang对所有数据库中的所有数据表进行任何操作。 2. 数据表的基本操作 录MySQL系统后输入的命令称为SQL。SQL是Structured Query Language(结构化查询语言)的缩写,它是专门为管理关系型数据库系统而设计的编程语言。学会了在命令行窗口中使用SQL命令操作数据库,我们就能通过在Python代码中嵌入SQL命令来更方便地在数据库中存取数据。 1)数据表结构基础知识 每张数据表有着自己的结构,这些结构需要在创建数据表时进行定义。前面说过,数据表的行称为记录,列称为字段。定义数据表的结构主要是定义字段的属性,主要包括字段名、字段类型、字段长度、字段约束。 (1)字段名 字段名可以看成每一列的列名。为字段命名时建议遵守以下规则:
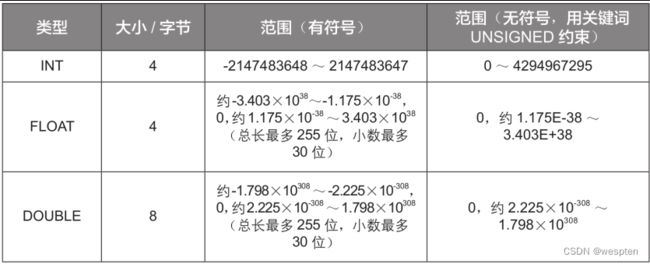
(2)字段类型和字段长度 字段类型规定了一个字段能存储的数据的类型,常用的有数值类型、字符串类型、时间类型3种,各个类型又按照大小和格式分为多种子类型。 常用的数值类型如下表所示:
常用的字符串类型如下表所示:
常用的时间类型如下表所示:
还有两种特殊的字段类型——ENUM和SET。ENUM是单选类型,在创建字段时指定若干选项,存储的值只能是这些选项中的一个;SET是多选类型,存储的值可以是这些选项中的多个。 (3)字段约束 字段约束规定了存储的数据必须符合的条件,这主要是为了保证数据的完整性。 常见的约束类型如下表所示:
2)数据表的“增”“删”“改”“查” 了解完数据表结构的基础知识,接着学习使用SQL完成数据表的“增”“删”“改”“查”等基本操作。 (1)新建数据表 在新建一张数据表之前需要先设计好表的结构,确定有哪些字段,以及每个字段的类型、长度和约束条件。 下表为一张用于存储员工信息的数据表的结构:
设计好表的结构,就可以使用CREATE TABLE语句创建数据表了。 根据上表编写如下所示的SQL命令: 登录数据库系统,先用命令“USE test;”进入前面创建的数据库test,然后输入上述命令(每一行末尾以“#”开头的内容为注释,不用输入),可以像下图这样分行输入,也可以输入在一行中,最后按【Enter】键执行,这样就完成了一个数据表的创建。
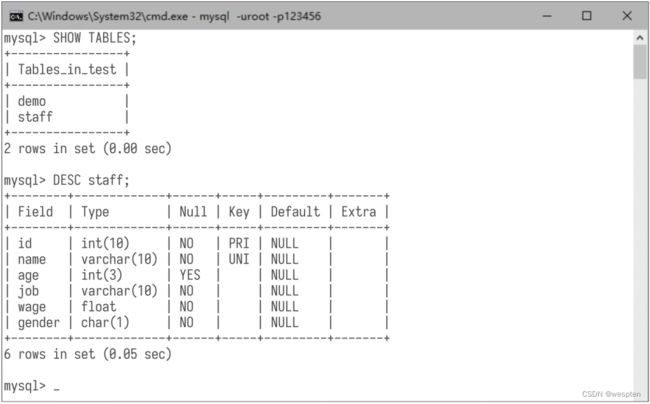
(2)查看数据表信息 进入数据库后,使用命令“SHOW TABLES;”可列出当前数据库中的数据表,使用命令“DESC 表名;”可查看指定数据表的结构,如下图所示。
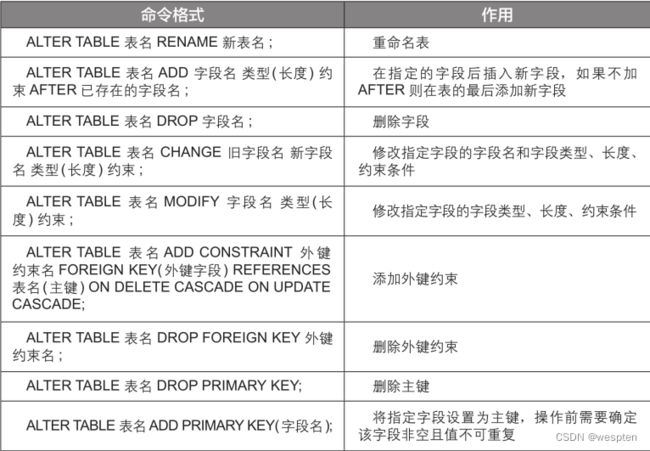
(3)修改数据表结构 使用ALTER TABLE语句可以修改数据表的结构。 常用的命令如下表所示:
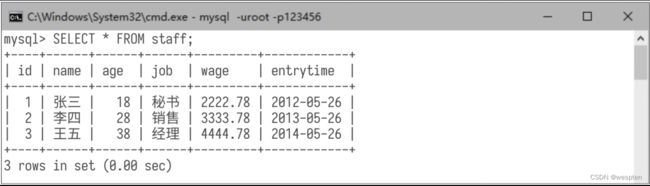
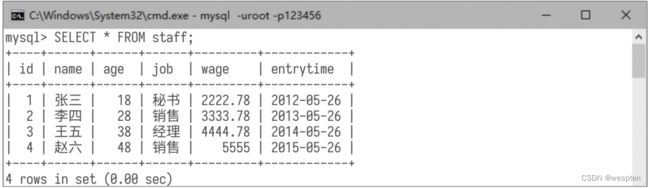
例如,将字段gender修改为字段entrytime,用于存储入职时间。 SQL命令如下: 然后用命令“DESC staff;”查看数据表结构,可看到修改结果,如下图所示:
(4)删除数据表 使用DROP语句能删除数据表,格式为“DROP TABLE 表名”。例如,删除数据表staff的命令如下: 另外,使用DROP语句还能删除数据库,格式为“DROP DATABASE 库名”。例如,删除数据库test的命令如下: 需要注意的是,数据库或数据表被删除后就难以恢复,因此要慎重使用DROP语句,并做好用户权限管理和定期数据备份,以免造成不可挽回的损失。 3. 数据表中数据的基本操作 学习了数据表的基本操作,接着来学习数据表中数据的基本操作。 1)插入数据记录 使用INSERT语句可以在数据表中插入数据记录。 演示命令如下: 2)查询数据记录 查询语句的基本格式为“SELECT 字段名 FROM 表名 WHERE 查询条件”,其中字段名可以使用通配符“*”。在基本的查询操作的基础上,还可以衍生出模糊查询、分组汇总、结果排序等操作。由于篇幅有限,这里不做展开。 查询所有数据记录,演示命令如下: 查询结果如下图所示:
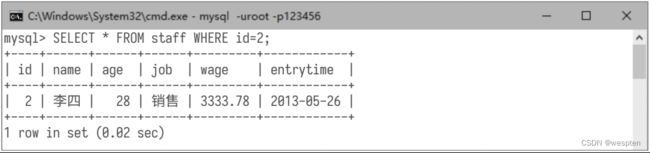
查询员工编号为2的数据记录,演示命令如下: 查询结果如下图所示:
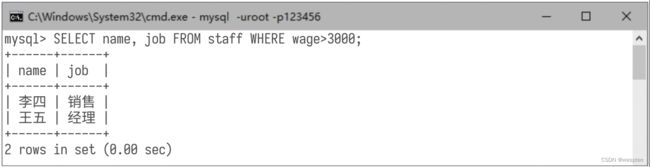
查询工资大于3000的员工的姓名和职位,演示命令如下: 查询结果如下图所示:
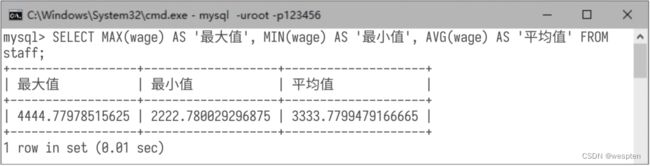
查询所有员工工资的最大值、最小值、平均值,演示命令如下: 查询结果如下图所示:
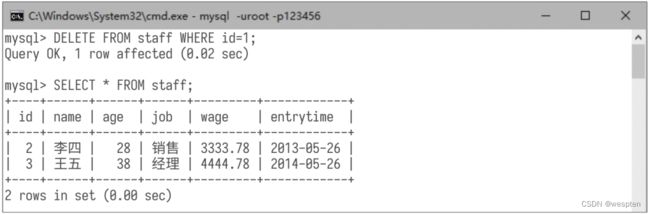
3)删除数据记录 使用DELETE语句能删除满足指定条件的数据记录。 然后使用命令“SELECT * FROM staff;”查询所有数据记录,可看到id为1的数据记录被删除了,如下图所示。
如果不指定条件,则会删除所有数据记录,演示命令如下: 再查询所有数据记录,可看到查询结果为空,如下图所示。
4)修改数据记录 UPDATE语句用于修改数据表中的现有数据记录。 将姓名为“张三”的员工的工资修改为1000,演示命令如下: 可以看出,UPDATE语句根据WHERE关键词指定的条件定位要修改的记录,根据SET关键词指定的字段名和字段值执行修改操作。 学习完常用的SQL命令,下面接着来学习如何在Python代码中操作数据库。 4. 用PyMySQL模块操作数据库 代码文件:用PyMySQL模块操作数据库.py PyMySQL是用于操作MySQL数据库的第三方模块,使用“pip install pymysql”命令进行安装。下面介绍这个模块的基本用法,包括连接数据库、执行SQL命令、获取执行结果等。 要操作数据库,首先需要连接到数据库。在PyMySQL模块中,使用connect()函数创建数据库连接,演示代码如下: 第2行代码中,参数host用于设置MySQL系统的IP地址,这里设置为本机的IP地址;参数port用于设置MySQL系统的端口;参数user和password分别用于设置登录MySQL系统的用户名和密码;参数database用于设置要连接的数据库名称;参数charset用于设置数据编码格式。 完成数据库连接的创建后,接着要创建游标。游标可以理解为指针,通过移动游标可以从数据集中选择和取出数据。创建游标的方法有很多,这里介绍两种。第一种方法创建的游标返回的数据是元组类型,演示代码如下: 第二种方法创建的游标返回的数据是字典类型,演示代码如下: 完成游标的创建后,通过游标的execute()函数执行SQL命令。 演示代码如下: 在编写SQL命令时,通常要用到字符串拼接。但是如果先拼接好SQL命令再用execute()函数执行,会产生SQL注入漏洞。不法分子可以利用这一漏洞绕过数据库的登录验证机制,无须提供用户名和密码就能操作数据库。为了消除这种安全隐患,execute()函数提供了字符串拼接功能,像上述第3行代码那样在execute()函数内部进行字符串拼接,就不会产生SQL注入漏洞了。 通过游标执行SQL命令后,就可以从执行结果中取出数据,基本方式有三种,分别为取出一条数据、多条数据和所有数据。需要注意的是,取过的数据不能被再次取出。例如,取出所有数据后,再取数据就会得到None;取出一条数据后,再取一次会得到下一条数据;取出多条数据也是这样依序进行,取不到就返回None。 取出所有数据使用的是游标的fetchall()函数,演示代码如下: 假设前面创建的是字典类型的游标,则代码运行结果如下: 取出一条数据使用的是游标的fetchone()函数。取出多条数据使用的是游标的fetchmany()函数,函数的参数为要取出的数据的条数,如cursor.fetchmany(2)。 演示代码如下: 5. 用pandas模块操作数据库 使用PyMySQL模块获取的数据为元组或字典格式,如果需要做进一步的处理,最好还要将其转换为pandas模块的DataFrame格式。那么有没有办法直接使用pandas模块操作数据库呢?答案是肯定的。pandas模块提供的read_sql_query()函数能进行“增”“删”“改”“查”等数据库操作,to_sql()函数能将DataFrame格式的数据写入数据表。 需要注意的是,这种方式除了要用到pandas和PyMySQL模块,还要用到SQLAlchemy模块,其安装命令为“pip install sqlalchemy”。 1)read_sql_query()函数 (1)read_sql_query()函数的主要参数
演示代码如下: create_engine()函数支持多种数据库,参数字符串中各部分的含义为“数据库类型+数据库驱动程序://数据库用户名:密码@数据库服务器IP地址:端口/数据库名?连接选项”。 上述代码表示创建一个MySQL数据库的连接引擎,以PyMySQL模块作为驱动程序,登录数据库系统的用户名和密码分别为root和123456,数据库服务器的IP地址为localhost(即本机,IP地址为127.0.0.1),端口为3306,连接的数据库名为test,连接选项中用参数charset指定编码格式为UTF-8。
(2)read_sql_query()函数的基本用法 下面使用read_sql_query()函数从数据库test的数据表staff中读取所有数据,并将字段entrytime作为行标签,生成一个DataFrame。 演示代码如下: 代码运行结果如下: 在数据表staff中增加一条数据记录,演示代码如下: 运行代码后,在MySQL的命令行窗口中查询所有数据记录,结果如下图所示。
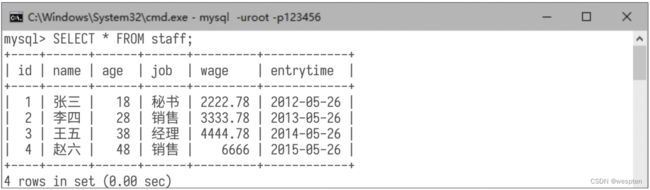
将员工编号为4的员工的工资修改为6666,演示代码如下: 运行代码后,在MySQL的命令行窗口中查询所有数据记录,结果如下图所示。
删除员工编号大于3的数据记录,演示代码如下: 运行代码后,在MySQL的命令行窗口中查询所有数据记录,结果如下图所示。
(3)read_sql_query()函数的用法总结 下面比较使用PyMySQL模块和read_sql_query()函数操作数据库的不同之处。
pandas模块中还有两个与read_sql_query()函数功能类似的函数——read_sql_table()和read_sql()。 这3个函数的区别主要体现在第1个参数:read_sql_query()函数的第1个参数是sql,传入的是SQL命令;read_sql_table()函数主要用于读取整张数据表,其第1个参数是table_name,传入的是数据表名;read_sql()函数则整合了前两个函数的功能,其第1个参数既可以是SQL命令,也可以是数据表名。读者可根据需求在这3个函数中进行选择。 2)to_sql()函数 (1)to_sql()函数的主要参数
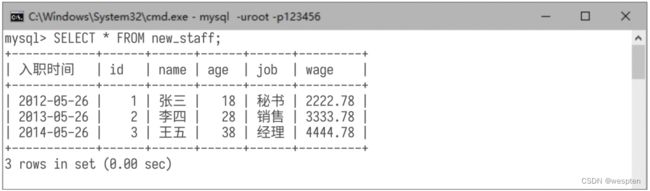
(2)to_sql()函数的基本用法 先用read_sql_query()函数读取数据表staff中的数据,生成一个DataFrame,再用to_sql()函数将该DataFrame写入数据表new_staff中,演示代码如下: 运行代码后,在MySQL的命令行窗口中查询数据表new_staff的所有数据记录,结果如下图所示。
(3)to_sql()函数的用法总结 to_sql()函数可以将DataFrame格式的数据直接写入数据库的数据表中,并且不要求数据库中已经存在对应的数据表。如果对数据表的字段类型有要求,可设置参数dtype,如果省略该参数,新创建的表会使用默认的字段类型。 2、Python操作sqlite数据库sqlite数据库以.db格式的文件形式存在,所以不需要安装驱动和应用系统,在标准库中也集成了sqlite数据库的操作库。 python操作sqlite数据库: 3、Python操作MongoDB数据库MongoDB 是由C++语言编写的,是一个基于分布式文件存储的开源数据库系统。 在高负载的情况下,添加更多的节点,可以保证服务器性能。 MongoDB 旨在为WEB应用提供可扩展的高性能数据存储解决方案。 MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。 主要特点:
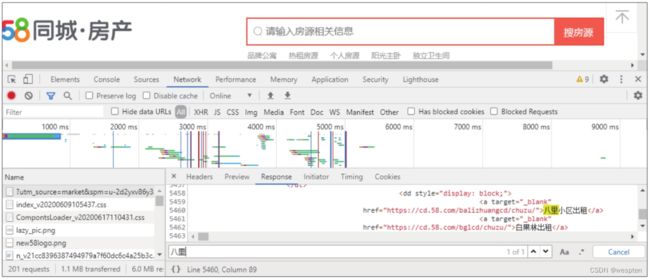
调试环境python3.6,调试python操作mongodb数据库。 1. 安装mongodb数据库 下载mongodb安装包:https://www.mongodb.com/download-center#atlas 安装mongodb软件:根据你的系统下载 32 位或 64 位的 .msi 文件,下载后双击该文件,按操作提示安装即可。mongodb compass 是可视化的数据库操作界面,安装后方便操作。它的作用相当于mysql数据库中的mysql font的作用。 我们这里将mongodb安装在默认c盘目录下:C:\Program Files\MongoDB\Server\3.6。 注意:安装中不要选择安装mongodb compass,因为这个软件下载很慢,如果网速有一点不稳定就会安装不成功,所以要单独下载。 创建数据目录和日志目录:MongoDB将数据目录存储在 db 目录下。将日志目录存储在log目录下。这里分别创建J:\mongodb\db和J:\mongodb\log两个目录。 创建配置文件:配置文件名为mongod.cfg。该文件必须设置 systemLog.path 参数,包括一些附加的配置选项更好。 这里具体配置内容如下: 将配置文件存放在 C:\Program Files\MongoDB\Server\3.6目录下。 安装mongodb服务: 在命令窗口先cd到mongodb安装目录的bin目录下,再使用mongod.exe启动服务。 启动mongodb服务(参数为数据存放路径): 启动mongodb服务后,就可以使用mongodb数据库了,但是命令窗口不能关闭。 由于mongodb都需要在bin目录下启动mongod.exe或者mongo.exe来完成,你可以将mongodb的安装目录C:\Program Files\MongoDB\Server\3.6\bin添加系统环境变量path中。我们这里添加到了环境变量中。 2. MongoDB后台管理Shell 如果你需要进入MongoDB后台管理,你需要先打开mongodb装目录的下的bin目录,然后执行mongo.exe文件,MongoDB Shell是MongoDB自带的交互式Javascript shell,用来对MongoDB进行操作和管理的交互式环境。 当你进入mongoDB后台后,它默认会链接到 test 文档(数据库)。 以后对Shell数据库的操作我们都在Shell窗口中进行。当然我们要学习的主要还是使用python连接操作mongodb数据库。 3. mongodb数据库操作 在python3.6下我们使用pymongo库: 安装成功后就可以编程代码实现python对mongodb数据库的操作了,python3.6操作mongodb数据库前请先确保mongodb服务已经打开。 python3.6下代码如下: 三、数据存取案例代码文件:案例:爬取58同城租房信息.py 本节通过一个案例对前面所学的知识进行综合应用:先爬取58同城网站的租房信息,再将爬取到的数据存储到MySQL数据库中。 步骤1:首先分析要爬取的数据是静态的还是动态加载的,可通过局部搜索页面中的房源关键词来确定。在第一个数据包中搜索关键词“八里”,在该数据包的“Response”选项卡下可搜索到相关数据,如下图所示。说明要爬取的数据存在于静态网页中,只需要对每一页的网址发起请求。
步骤2:在网页底部可以看到总共有70页,如下图所示:
通过单击页码观察网址的变化,如下图所示。可以看出字符“pn”后的数字就是页码,同时每次携带的参数不会变化,说明网站有反爬机制。
需要通过搭建IP代理池的方法来应对反爬机制。先尝试爬取4页数据,编写完完整代码后再将循环次数更改为70次。 发起请求的代码如下: 第5行代码中调用的ip_pond()函数的代码如下: 使用print(response, response.url)查看请求的每个网址的响应状态,以判断能否成功爬取,运行结果如下图所示。可以看到对前4页网页的请求成功返回了响应对象,下一步就可以开始解析响应对象中的数据了。
步骤3:这里使用BeautifulSoup模块来解析网页源代码中的数据。先提取网页源代码并实例化BeautifulSoup对象,接着利用BeautifulSoup对象解析数据,代码如下: 在编写自定义函数parse_html()的代码之前,需要先查看网页的结构。利用开发者工具定位网页元素,可以看到一个房源信息对应一个
因此,先获取每个 使用print()函数输出data_info,运行结果如下图所示。可以看到,解析出的数据中掺杂了大量无用的空格、换行、“\xa0”字符串等,需要删除,还有一些生僻字需要处理。
步骤4:先删除数据中的无用字符,将parse_html()函数的第4~8行代码修改如下: 代码运行结果如下图所示,可以看到无用字符已经没有了,接着来处理生僻字。这些生僻字产生的原因是58同城采用了“字体反爬”技术,简单来说是利用自定义字体对阿拉伯数字进行加密处理,爬取的数据中的阿拉伯数字就会变成生僻字。 解决办法是找到生僻字与阿拉伯数字之间的对应关系并进行一一替换。
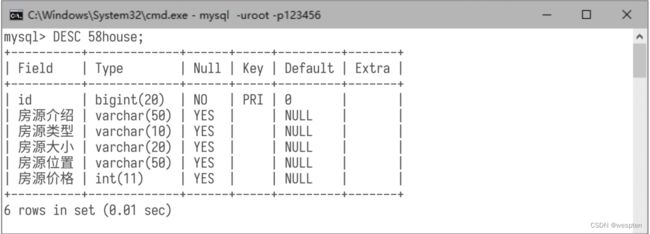
编写一个自定义函数jiema()用于完成生僻字的替换,代码如下: 步骤7:运行代码后,在命令行窗口中登录MySQL数据库,使用命令“DESC 58house;”查看表结构,如下图所示。
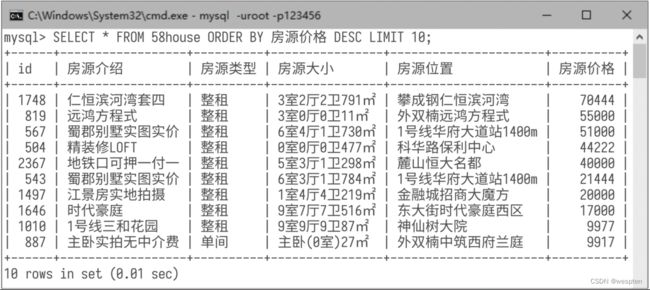
然后使用命令“SELECT * FROM 58house ORDER BY 房源价格 DESC LIMIT 10;”查询数据库中价格最低的10条房源信息,如下图所示。
你可能感兴趣的:(Python,Golang,AI,机器学习,自然语言图像处理,python,开发语言) |