Hive 体系架构
Hive 为C/S模式,其体系架构如下:
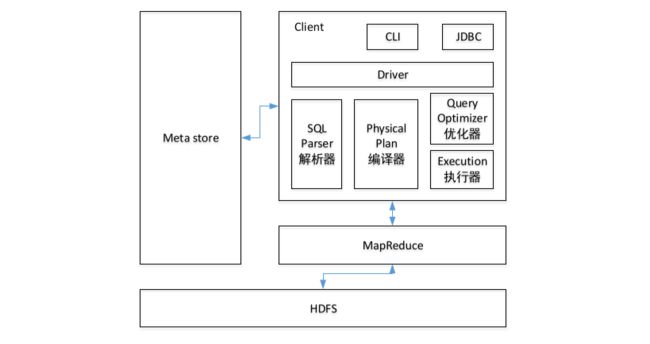
Hive
Hive 使用的数据在 HDFS 中,Hive 的 HQL 将转为 MR、Tez 或 Spark 后,在 Hadoop 集群上运行。
Hive 的三种运行模式:内嵌模式、本地模式、远程模式。
内嵌模式(Local/Embedded Metastore Database(Derby)):该模式一般用来练手和测试使用,Hive 在运行时会在部署目录色生成一个 Derby 文件和一个 metastore_db 目录。
本地模式(Local/Embedded Metastore Server):使用 MySQL 数据库存储元数据。该模式下,每当使用 bin/hive 或者 hiveserver2 的时候,都会在内部启动一个 metastore 嵌入式服务。
如果客户端过多,每个客户端都自己发起连接,就会对mysql造成较大的压力。
远程模式(Remote Metastore Server):使用 MySQL 数据库存储元数据。该模式是把 metastore 服务从Hive服务里剥离出来部署,让 metastore 服务和 Hive 服务运行在不同的进程里,这样从架构上进一步解耦,保证了 Hive 的稳定性,提升了服务效率。
支持多个客户端同时连接,而且客户端不需要知道MySQL的用户名和密码,只需要连接metastore服务即可,提供了更好的管理性和安全保障。
Driver
解析器(SQL Parser):将 SQL 字符串转换成抽象语法树 AST,这一步一般使用第三方工具库完成,比如 antlr;对 AST 进行语法分析,比如表是否存在,字段是否存在、SQL 语义是否有误。
编译器(Physical Plan):将 AST 编译生成逻辑执行计划。
优化器(Query Optimizer):对逻辑执行计划进行优化。
执行器(Execution):把逻辑执行计划转换成可以运行的物理计划
Client
实现对 Hive 访问的用户接口包括:CLI、JDBC/ODBC、HWI、Thrift 等。
CLI(Command Line Interface):命令行接口。CLI启动时,会同时启动一个 Hive 副本。
JDBC/ODBC:使用 Java 的方式访问 Hive。
HWI(Hive Web Interface):通过浏览器访问 Hive。
Thrift:Facebook 开发的一个酸碱框架,Hive 继承了该服务(Hiveserver/HiveServer2)
Hiveserver/HiveServer2 的区别:
都允许在不启动 CLI 的情况下,通过远程客户端访问 Hive,Hiveserver 只支持单个客户端,在 Hive-0.11.0 版本中重写了该模块的代码得到了 Hiveserver2,Hiveserver2 支持多客户端,为开放的客户端(JDBC、ODBC…)提供了更好的支持。
Metastore
元数据(Metastore):包含表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(内/外部表)、表的数据所在目录等。
元数据默认存储在 derby 数据库中,但通常使用 MySQL 数据库存储!
Hive 运行机制
1️⃣:客户端提交 HQL程序发送到 Driver(任何数据库驱动程序,如JDBC、ODBC) 中执行;
2️⃣:Driver 根据 HQL 解析 Query 语句,验证语法;
3️⃣:编译器将获取元数据的请求发送给 Metastore;
4️⃣:Metastore 将所需的元数据作为响应发送给编译器;
5️⃣:编译器检查要求,并重新发送计划给 Driver;
6️⃣:Driver 将执行计划发送到执行引擎;
7️⃣:执行引擎将作业发送到 JobTracker,NamaNode 将作业分配到 TaskTracker,DataNode 执行 MapReduce 操作,执行的同时,执行引擎通过 Matastore 执行元数据操作
8️⃣:执行引擎接收 DataNode 的结果
9️⃣:执行引擎将结果发送到 Driver
1️⃣0️⃣ :Driver 将结果发送到 Hive 端口