指令流水 一个时钟周期 出一个结果_超标量处理器流水线

MIPS处理器的五级流水线

- Fetch(取址)
PC寄存器值作为地址,从I-Cache中取址并存储到指令寄存器。 - Decode(译码)
将指令解码,并根据结果读取寄存器堆,得到指令的源操作数。 - Execute(执行)
根据指令类型完成计算任务。 - Memory(访存)
访问D-Cache,不访问存储器的指令此阶段不做事。 - Write Back(回填)
如果指令存在目的寄存器,将指令结果写入目的寄存器
流水线
流水线技术是一种将每条指令分解为多步,并让各步操作重叠,从而实现几条指令并行处理的技术。程序中的指令仍是一条条顺序执行,但可以预先取若干条指令,并在当前指令尚未执行完时,提前启动后续指令的另一些操作步骤。这样显然可加速一段程序的运行过程。
超流水线
超级流水线以增加流水线级数的方法来缩短机器周期,相同的时间内超级流水线执行了更多的机器指令。采用简单指令以加快执行速度是所有流水线的共同特点,但超级流水线配置了多个功能部件和指令译码电路,采用多条流水线并行处理,还有多个寄存器端口和总线,可以同时执行多个操作,因此比普通流水线执行的更快,在一个机器周期内可以流出多条指令。
一般而言,CPU执行一条指令需要经过以下阶段:取指->译码->地址生成->取操作数->执行->写回,每个阶段都要消耗一个时钟周期,同时每个阶段的计算结果在周期结束以前都要发送到阶段之间的锁存器上,以供下一个阶段使用。
超标量
超标量(superscalar)是指在CPU中有一条以上的流水线,并且每时钟周期内可以完成一条以上的指令,这种设计就叫超标量技术。 其实质是以空间换取时间。而超流水线是通过细化流水、提高主频,使得在一个机器周期内完成一个甚至多个操作,其实质是以时间换取空间。
指令间的相关性
(1)先写后读(Read After Write, RAW)

(2)先读后写(Write After Read, WAR)

(3)先写后写(Write After Write, WAW)
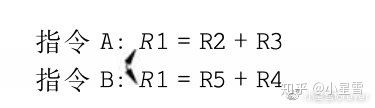
超标量处理器中,WAW、WAR和RAW这三种相关性都会阻碍指令的乱序执行。
超标量流水线
超标量处理器有两种方式可以执行指令,顺序执行(in-order)和乱序执行(out-of-order)。

顺序执行的超标量处理器中,指令的执行必须遵循程序中指定的顺序。

乱序执行,指令在流水线中不在遵循程序中指定的顺序来执行,一旦某条指令的操作数准备好了,就可以将其送到FU中执行。

为了解决乱序执行时解决WAW和WAR这两种相关性,需要对寄存器进行重命名(register renaming)。
超标量处理器中的各个阶段介绍如下:
(1)Fetch(取指令):这部分负责从I-Cache中取指令,I-Cache负责存储最近常用的指令;分支预测器用来决定下一条指令的PC值。
(2)Decode(解码):识别指令的类型
(3)Register Renaming(寄存器重命名):解决WAW和WAR这两种“伪相关性”,需要使用寄存器重命名的方法,将指令集中定义的逻辑寄存器重命名为处理器内部使用的物理寄存器。物理寄存器的个数更多余逻辑寄存器,处理器可以调度更多可以并行执行的指令。将存在RAW的寄存器进行标记,后续通过旁路网络(bypassing network)解决存在的“真相关性”。
(4)Dispatch(分发):被重命名之后的指令会按照程序中的规定的顺序,写到发射队列(Issue Queue)、重排序缓存(ROB)和Store Buffer等部件中
(5)Issue(发射):经过流水线的分发(Dispatch)阶段之后,指令被写到了发射队列(Issue Queue)中,仲裁(select)电路回从这个部件中挑选出合适的指令送到FU中执行。
(6)Register File Read(读取寄存器):被仲裁电路选中的指令需要从物理寄存器堆(Physical Register File, PRF)中读取操作数
(7)Execute(执行):各种FU单元执行
(8)Write back(写回):将FU计算的结果写到物理寄存器(PRF)中,通过旁路网络将计算结果送到需要的地方。
(9)Commit(提交):这个阶段起主要作用的部件是重排序缓存(ROB),它将乱序执行的指令拉回到程序中规定的顺序。
Cortex-A77架构介绍
Cortex A77面向移动高性能领域,采用ARMv8.2 64位指令集架构。硬件设计上和A76一脉相承,都采用了7nm工艺,峰值频率也没有变化。A77的流水线结构应该和A76是一致的,20%的提升主要在微架构的细节方面,用来提高IPC和并行执行的能力。

Cortex-A77微架构
A77的流水线结构没有太大变化,还是标准的physical register Out-of-Order machine。其中有几个值得注意的点。第一个是1.5K entry的Mop Cache。引入Mop Cache可以存储解码后的微指令,这样能够直接bypass fetch和decode的流水线,获得更大的dispatch宽度。我们看到这个Mop cache是放在fetch级的,和Icache的结果mux后,统一送给decode模块。如果这个结构正确的话,这个Mop cache的主要目的就是功耗控制和减少branch penalty。Decode级增加到了6条指令,同时拓宽了issue宽度,增加了1个AlU和1个BRU。这样A77的执行单元有4个ALU,2个BRU,2条Load-store pipe。

Branch prediction是另一个重点优化的手段。可以看出和ZEN2的方向如出一辙,这也是前端流水线最重要的性能指标。A77拓宽了branch prediction的bandwidth到64B,这样理论上可以同时预测16条32位指令的分支结果。同时也和ZEN一样,大幅增加了BTB的size。可以看到,A77相对于ZEN少了一个L0 BTB,只有2级BTB。由于没有具体的数据,很难说哪个方案更好,应该是根据各自面对的应用场景测试后选择的方案。共同的趋势都是更大的预测器和预测宽度。
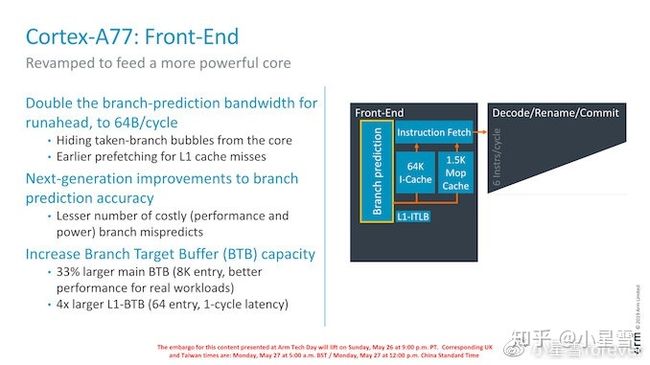
Decode级主要是增加了50%的dispatch宽度,6条指令的并发理论上可以提供更大的并行执行能力。随之ROB的entry数也增加到160个。这里提到了加快renaming table在branch misprediction后的update速度。通常renaming table会在相应branch retire时,恢复到actual renaming的状态。这里提到的accelerate,有可能是提供了多个branch recovery点,可以不等retire,直接恢复到最近的recovery点上。这样硬件复杂度和面积都会增加。由于没有更详细的信息,也只能做上述合理的推测。

执行单元,主要是数量的增加,向Apple看齐。注意ARM一直保持了single cycle的ALU,这在单核IPC性能上至关重要,ZEN2也保持了这一点。A77采用了Unified Issue Queue,这和ZEN分离式的设计有所不同。一体化的IQ可以带来更好的schedule效果,但会在很大程度上制约频率的提升。这里体现了ARM并不以频率为首要目标,而更多的考虑综合的能耗。另外的变化是增加了crypto流水线,提高AES编解码的能力。对于这一点,作者还是持保留态度。目前对于crypto的加速通常采用专用加速器实现,因为 算法确定,ASIC能获得非常高的加速比,同时硬件代价较小。并且ASIC实现的crypto加速器可以和处理器完全隔离,做到纯硬件的加解密,这样安全级别很高。而用处理器实现,首先性能和功耗有数量级上的差距,其次是指令实现,软件参与度较高,安全性上难以保证。

Load-store流水线,同样采用了统一的Issue Queue。可以看到A77有2个address的path和2个st-date的path,可以同时执行2条存储指令。组合可能是2条load,2条store,1 load+1 store。这里采用了2条store pipe的方案还是比较激进的,应该为了更高的内存搬运的性能。对于通常的应用,这额外的一条store data估计是起不到多大作用的。


参考:《超标量体系结构》
MikesICroom:移动的王者:深入分析ARM最强处理器Cortex A77zhuanlan.zhihu.com