1.RocketMQ简述
RocketMQ是阿里巴巴在2012年开源的分布式消息中间件,目前已经捐赠给Apache基金会,已经于2016年11月成为 Apache 孵化项目,相信RocketMQ的未来会发挥着越来越大的作用,将有更多的开发者因此受益。
1.1 消息队列(Message Queue)的好处:
a.解耦
生产者和消费者可以独立发布服务,不会导致线上异常和数据丢失;
b.可恢复性
MQ通常具有重试机制,而且分组消费,数据存储到磁盘(支持副本),使数据不会丢失;
c.缓冲
避免生产者和消费者处理速度不一致带来的问题,如数据丢失,调用异常和超时等;
d.削峰
使用MQ可以一定程度上解决突发高流量的情况,将短时间内的流量,扩大到更长时间的维度,避免系统超负荷运行,甚至系统奔溃;
e. 异步通信
消费者可以不立即处理MQ中的消息,让MQ作为一种临时的数据存储方式(Kafka默认保存数据7天),等在需要的时候在进行消费处理。
f. 数据分发
当业务M需要调用多方(如A,B,C)时,普通的调用需要逐个调用,当增加D或者减少C时,当前业务需要修改代码以及重新上线等;但是使用MQ之后,当前业务M只需要将消息发送到MQ中,不用关心到底是谁消费了消息,消费者的增加和删除不影响业务M。
1.2 消息队列(Message Queue)的缺点:
a.系统可用性减低
加入MQ之后,服务就会依赖MQ,MQ宕机,那么服务也就不可用了。
b.系统复杂性增加:
同步改成异步之后,MQ消息的丢失,重复,顺序性等都需要考虑。
c.数据一致性问题:
在不同的分组消费MQ时,有的分组消费成功,有的消费失败,会导致各系统之间的数据不一致。
2.RocketMQ架构
说明:
2.1 NameServer名称服务
NameServer是没有状态的,即NameServer中的Broker和topic等状态信息(通过其他角色上报获取)都是保存在内存中的,不会持久化存储(可通过配置实现),集群可以横向扩展。主要功能如下:
a.接收Broker(master和slave)启动时的注册路由信息;
b.为producer和consumer提供路由服务,即通过topic名字获取所有broker的路由信息;
c.接收broker发送的心跳信息,如果心跳的时间戳过期NameServer关闭与broker的连接。
2.2 Broker节点
Broker向NameServer注册topic配置信息,配置信息格式如下:
{
"perm":6,
"readQueueNums":2,
"topicFilterType":"SINGLE_TAG",
"topicName":"Topic-Lance",
"writeQueueNums":5
}
Broker的消息存储:
Rocketmq的消息的存储是由consumeQueue和 commitLog 配合完成的,commitLog保存消息的物理数据,consumeQueue是消息的逻辑队列,类似于索引,存储的是指向物理存储的地址。在一个Broker上,只有一个commitLog,所有consumeQueue共享同一个commitLog。
假如topic的名字是Topic-Lance,配置的读写队列有queue-1和queue-2,那么Topic-Lance和queue-1组成一个consumeQueue,Topic-Lance和queue-2组成另一个consumeQueue。
假如broker-A(包含queue-0,queue-1,queue-2), broker-B(包含queue-0,queue-1)两台broker机器都配置了Topic-Lance,那么broker启动的时候,注册到NameServer的Topic-Lance的路由有broker-A-queue-0,broker-A-queue-1,broker-A-queue-2,broker-B-queue-0,broker-B-queue-1共5个consumeQueue。
为了提高读写性能,commitLog采取顺序写,随机读(通过pagecache机制批量从磁盘读取到内存,加速后续的读取速度),consumeQueue大部分读入内存(如果consumeQueue因为重启等因素丢失,可以通过commitLog重建)
2.3 Producer 生产者
a.Producer发送消息时(必须制定topic),首先从本地的Producer集合中获取topic->broker的路由信息,如果没有,则从nameserver中获取topic->broker路由,并缓存到本地集合;
b.定时从nameServer获取最新的topic路由信息;
c.Producer定时将Producer的group信息发送到对应的broker上;
d.Producer发送消息到Master的broker上,通过Broker的主从复制copy到slave的broker上。
发送实现轮询方式:
List messageQueueList;
AtomicInteger sendWhichQueue;
int index =(++sendWitchQueue)% messageQueueList.size
MessageQueue sendQueue = messageQueueList[index];
//sendQueue 为要发送的队列
2.4 Consumer 消费者
a.向NameServer注册Consumer;
b.定时从NameServer获取topic路由信息;
c.定时清理下线的broker;
d.向所有broker发送心跳;
e.动态调整消费线程池;
f.负责负载均衡服务RebalanceService。
RocketMQ是基于pull模式拉取消息,consumer做负载均衡并通过长轮询向broker拉消息,长轮询拉取消息后回调MessageListener接口实现完成消费。
关于RocketMQ长轮询可参考:
https://www.jianshu.com/p/48dbc9eee890
3.RocketMQ数据处理
3.1 数据重试机制
a.Producer端重试 :
默认情况下是失败3次重试,可通过retryTimesWhenSendFailed定义重试次数;
b.Consumer端重试:
1.Exception的情况,一般重复16次 10s、30s、1mins、2mins、3mins等,可以通过设置transactionCheckMax设置;
2.超时情况(Consumer端没有返回CONSUME_SUCCESS,也没有返回RECONSUME_LATER),MQ会无限制的发送给Consumer端,默认超时时间时15分钟。
RocketMQ默认保存3天,commit log刷盘间隔,默认1秒。
c. 死信队列:
当消费者消费16次以后,数据仍然不成功,那么消息会被发送到死信队列中。死信队列不会被正常消费,保存时间和正常消息相同,默认保存3天,故线上业务要监控死信队列。
3.2 MQ的高效读写:
a.顺序写磁盘
Producer写的时候,一直是追加到文件的末尾,这样避免大量的磁盘寻址时间。如普通的机械磁盘,顺序写能够达到600M/s,而随机写只有100K/s。
b.零拷贝
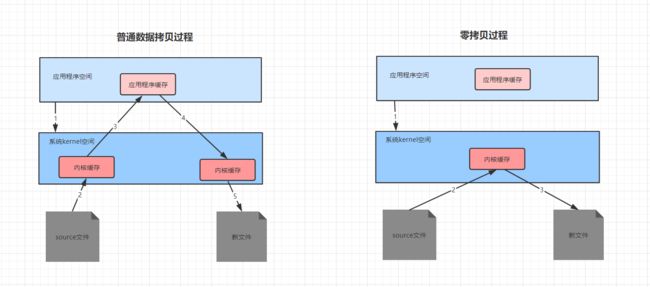
零拷贝避免了数据读入到应用程序空间的过程,直接由操作系统的kernel完成读写,极大地提高的效率。
c.分布式并发
kafka采取分布式方式,每个topic数据可以有多个partition,每个partition在不同的broker上,一个partition由一个group中的消费者消费,很大程度上提高了并行度。
3.3 RocketMQ的数据存储结构:
a.CommitLog
CommitLog存储消息的元数据,默认每个 CommitLog 文件的大小为 1G,一般情况下第一个 CommitLog 的起始偏移量为 0,第二个 CommitLog 的起始偏移量为 1073741824 (1G = 1073741824byte)。
b.CommitQueue
保存在CommitLog中的消息的索引。
c.IndexFile
为消息提供根据key和时间区间来查询消息的方法,算是一个辅助的功能。
3.4 RocketMQ的刷盘方式:
数据写入的过程为:
生产者 --> JVM堆 --> 系统内存 --> 磁盘
a.同步刷盘
在返回写入成功之前,消息已经被写入到了磁盘中,即走完生产者 --> JVM堆 --> 系统内存 --> 磁盘流程之后,返回成功。性能较低,但是保证了数据不丢失。
b.异步刷盘
在返回写入成功之前,消息已经被写入到了内存中,即走完生产者 --> JVM堆 --> 系统内存,返回成功。速度快,吞吐量达,当内存积累到一个阀值的时候,触发刷盘,将内存数据写入到磁盘。无法保证内存中的数据不丢失。
4.RocketMQ高可用
4.1 生产者的高可用:
一个topic数据的消息队列,创建到多个Broker组(Broker组内有主节点和从节点)上,这样生产者发送的消息的位置是一个组,而不是单点。
4.2 消费者的高可用:
消费者在消费消息时,当主节点宕机后,消费者会被自动切换到从节点进行消费