Transformer Tutorials 最全入门详细解释(一)
目录
.0 背景
0.1 RNN
0.2 seq2seq(别名Encoder-Decoder)
0.3 Attention(注意力机制)
.1 Transformer
1.1 什么是Transformer
1.2 Encoder-Decoder
1.3 self-attention
1.4 Multi-Head attention
1.5 output
.2 位置编码
2.1 Positional Encoding Layer in Transformers
2.2 Understanding the Positional Encoding Matrix
2.4 Visualizing the Positional Matrix
2.5 What Is the Final Output of the Positional Encoding Layer?
References
.0 背景
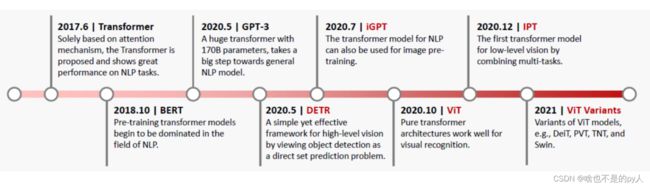

它做了什么:
在不同语境中,相同的单词代表不同的含义,比如说下面情境

| it | tired中 | 代表anmimal |
| it | wide中 | 代表street |
显然句子中每一个单词的意思要跟其他单词相关
0.1 RNN
RNN循环神经网络被广泛应用于自然语言处理中,对于处理序列数据有很好的效果,常见的序列数据有文本、语音等,至于为什么要用到循环神经网络而不是传统的神经网络,我们在这里举一个例子。
如:我一月一号去郑州。
那么“一月一号”是时间,“郑州”是目的地,“我”和“去”都是其他不需要提取的信息,我们统一归为其他类。
那么假如我输入另外一个句子:
我一月一号离开郑州
此时“一月一号”是时间,“郑州”就变成了始发地,“我”和“离开”都是其他。
因为计算机并不能读懂汉字,所以我们一般会用向量的方式去表示一个词。
向量表示词的方法有很多,常用的比如one-hot、词袋模型、词嵌入等。
在本例中为了方便计算在这里我们使用:
[1,1]表示我
[2,2]表示去
[3,3]表示离开
[4,4]表示郑州
并且假设所有的权重都是1,所有的偏置都是0。
下图为“我去郑州”的循环神经网络结构图。
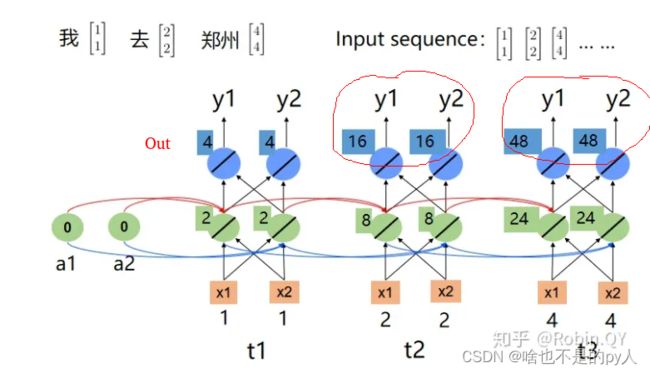
我去郑州 
我离开郑州
我们看到,因为“去”和“离开”的词向量不同,所以在循环神经网络中最后的“郑州”的输出也不相同,这样就能把两个“郑州”给区分开来了。
根据上边的例子可以看出来,循环神经网络中每一个时序的隐藏层不仅包含了前边时序的输入信息,也包含了前边时序的顺序信息。可以理解为包含了前边时序的语义信息。
循环神经网络展开图:
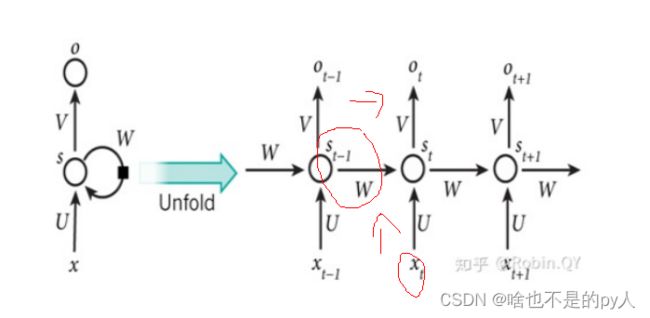
可以看出,每一个时刻的输出不仅包含了该时刻的输入向量,也包含了前一时刻的隐藏层的输出。具体的计算公式如下:

0.2 seq2seq(别名Encoder-Decoder)
刚才的例子其实是N对N的循环神经网络,即我的输入序列长度是N,输出也是对应的N长度的序列。其实循环神经网络还有其他的比如:1对N、N对1。
但很多时候我们会遇到输入序列和输出序列不等长的例子但又不是1对N和N对1,如机器翻译,智能问答,源语言和目标语言的句子往往并没有相同的长度。为此我们引出RNN最重要的一个变种:N vs M。这种结构又叫Encoder-Decoder模型,也可以称之为Seq2Seq模型。
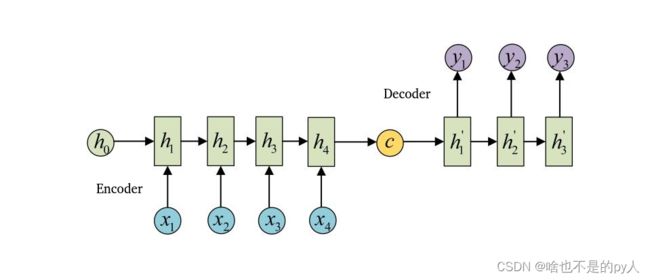
还有一种做法是将c当做每一步的输入:

对于序列到序列的数据来说,可以把Encoder和Decoder分别看成是RNN,在Encoder中根据输入数据生成一个语义编码C,C的获取方式有很多种,最简单的就是把Encoder中最后一个隐藏层赋值给C,也可以对最后一个隐藏状态做一个变换得到C,还可以对所有的隐藏状态做变换得到C。
拿到C之后,就可以用另一个RNN进行解码,这部分RNN被称为Decoder,具体做法就是将C当做之前的初始状态h0输入到Decoder中,C还有一种做法是将C当做每一步的输入。
举例:
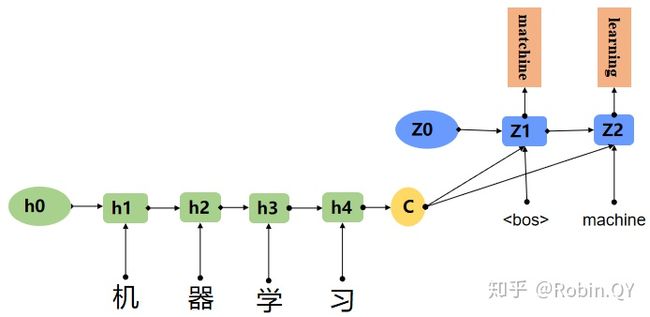
这里我们用一个机器翻译的例子解释seq2seq模型。
例:机器学习翻译 成 machine learning
0.3 Attention(注意力机制)
图片展示的Encoder-Decoder框架是没有体现“注意力模型”的,所以可以把它看做是注意力不集中分心模型。因为在生成目标句子的单词时,不论生成哪个单词,它们使用的输入句子的语义编码C都是一样的,没有任何区别。

而语义编码C是由原句子中的每个单词经过Encoder编码产生的,这意味着原句子中任意单词对生成某个目标单词来说影响力都是相同的,这就是模型没有体现出注意力的缘由。
所以就引出了attention来解决这个问题
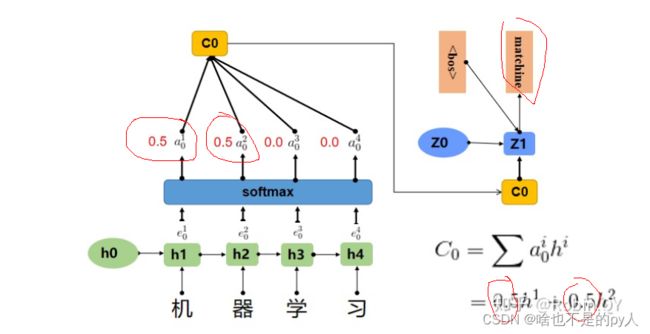
在上边那个例子中在生成“machine”时,"机","器","学",""习"的贡献是相同的,很明显,这是不太合理,显然,"机","器",对于翻译成"machine"更为重要。所以我们希望在模型翻译"machine"的时候,"机","器"两个字的贡献(权重)更大,当在翻译成"learning"时,"学","习"两个字贡献(权重)更大。

上图中,输入序列上是“机器学习”,因此Encoder中的h1、h2、h3、h4分别代表“机","器","学","习”的信息,在翻译"macine"时,第一个上下文向量C1应该和"机","器"两个字最相关,所以对应的权重a_ij比较大。
在翻译"learning"时,第二个上下文向量C2应该和"学","习"两个字最相关,所以"学","习"对应的权重a_ij比较大。
a_ij其实是一个0-1之间的值,a可以看成是e的softmax后的结果。
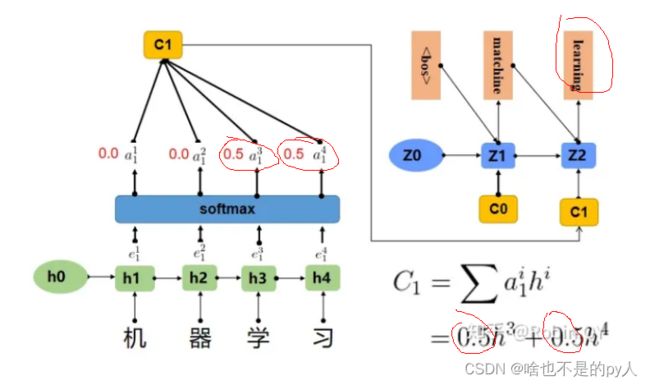
这样显然就可以看出和之前的区别,这样就有了attention
那现在关于attention来说就只剩下一个问题了,就是e是怎么来的。关于e的计算,业界有很多种方法,常用的有以下三种方式:

- 计算Encoder的序列h与Decoder的序列h的余弦相似度.
- 在1的基础上,乘上一个Wa,Wa是需要学习的参数,从学习到Encoder和Decoder的隐藏的打分e。
- 设计一个前馈神经网络,前馈神经网络的输入是Encoder和Decoder的两个隐藏状态,Va、Wa都是需要学习的参数。
通过这样的设计让e更有效

.1 Transformer
Transformer是一个利用注意力机制来提高模型训练速度的模型。
Trasnformer可以说是完全基于自注意力机制的一个深度学习模型,因为它适用于并行化计算,和它本身模型的复杂程度导致它在精度和性能上都要高于之前流行的RNN循环神经网络。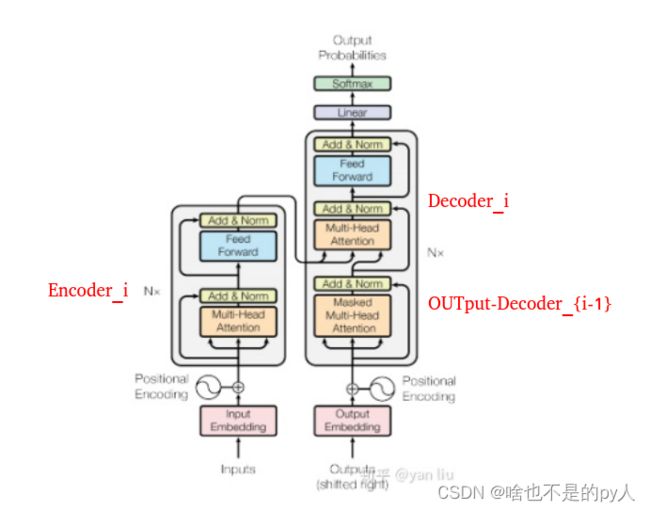
1.1 什么是Transformer
你可以简单理解为它是一个黑盒子,当我们在做文本翻译任务是,我输入进去一个中文,经过这个黑盒子之后,输出来翻译过后的英文。

那么在这个黑盒子里面都有什么呢?
里面主要有两部分组成:Encoder 和 Decoder
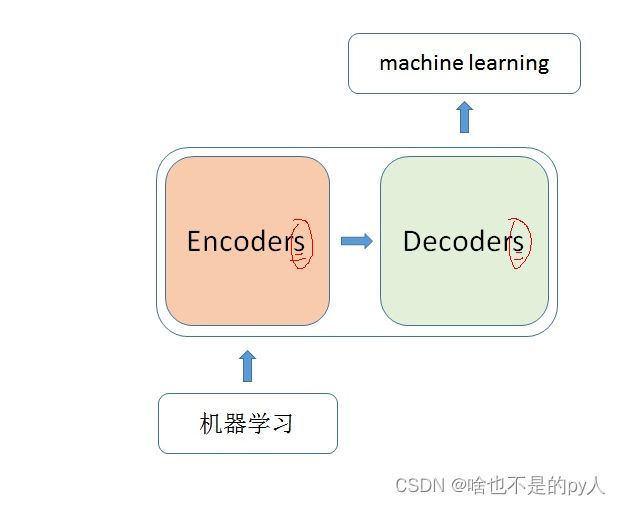
当我输入一个文本的时候,该文本数据会先经过一个叫Encoders的模块,对该文本进行编码,然后将编码后的数据再传入一个叫Decoders的模块进行解码,解码后就得到了翻译后的文本,对应的我们称Encoders为编码器,Decoders为解码器。
1.2 Encoder-Decoder
那么编码器和解码器里边又都是些什么呢?
细心的同学可能已经发现了,上图中的Decoders后边加了个s,那就代表有多个编码器了呗,没错,这个编码模块里边,有很多小的编码器,一般情况下,Encoders里边有6个小编码器,同样的,Decoders里边有6个小解码器。
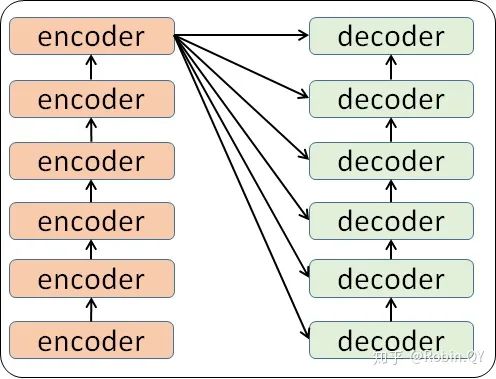
我们看到,在编码部分,每一个的小编码器的输入是前一个小编码器的输出,而每一个小解码器的输入不光是它的前一个解码器的输出,还包括了整个编码部分的输出。
那么你可能又该问了,那每一个小编码器里边又是什么呢?
我们放大一个encoder,发现里边的结构是一个自注意力机制加上一个前馈神经网络。

1.3 self-attention
首先,self-attention的输入就是词向量,即整个模型的最初的输入是词向量的形式。那自注意力机制呢,顾名思义就是自己和自己计算一遍注意力,即对每一个输入的词向量,我们需要构建self-attention的输入。
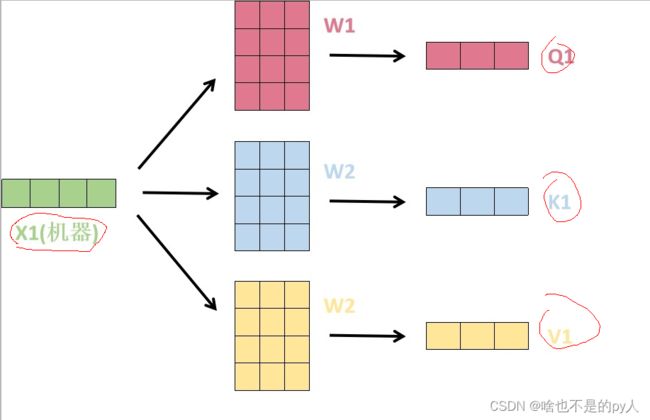
1. 在这里,transformer首先将词向量乘上三个矩阵,得到三个新的向量,之所以乘上三个矩阵参数而不是直接用原本的词向量是因为这样增加更多的参数,提高模型效果。对于输入X1(机器),乘上三个矩阵后分别得到Q1,K1,V1,同样的,对于输入X2(学习),也乘上三个不同的矩阵得Q2,K2,V2。
2. 那接下来就要计算注意力得分了,这个得分是通过计算Q与各个单词的K向量的点积得到的。我们以X1为例,分别将Q1和K1、K2进行点积运算,假设分别得到得分112和96。

3. 将得分分别除以一个特定数值8(K向量的维度的平方根,通常K向量的维度是64)这能让梯度更加稳定,则得到结果如下:

4. 将上述结果进行softmax运算得到,softmax主要将分数标准化,使他们都是正数并且加起来等于1。

5. 将V向量乘上softmax的结果,这个思想主要是为了保持我们想要关注的单词的值不变,而掩盖掉那些不相关的单词(例如将他们乘上很小的数字)

6. 将带权重的各个V向量加起来,至此,产生在这个位置上(第一个单词)的self-attention层的输出,其余位置的self-attention输出也是同样的计算方式。

将上述的过程总结为一个公式就可以用下图表示:

1.4 Multi-Head attention
self-attention层到这里就结束了吗?
还没有,论文为了进一步细化自注意力机制层,增加了“多头注意力机制”的概念,这从两个方面提高了自注意力层的性能。
第一个方面,他扩展了模型关注不同位置的能力,这对翻译一下句子特别有用,因为我们想知道“it”是指代的哪个单词。

第二个方面,他给了自注意力层多个“表示子空间”。对于多头自注意力机制,我们不止有一组Q/K/V权重矩阵,而是有多组(论文中使用8组),所以每个编码器/解码器使用8个“头”(可以理解为8个互不干扰自的注意力机制运算),每一组的Q/K/V都不相同。然后,得到8个不同的权重矩阵Z,每个权重矩阵被用来将输入向量投射到不同的表示子空间。
经过多头注意力机制后,就会得到多个权重矩阵Z,我们将多个Z进行拼接就得到了self-attention层的输出:

上述我们经过了self-attention层,我们得到了self-attention的输出,self-attention的输出即是前馈神经网络层的输入,然后前馈神经网络的输入只需要一个矩阵就可以了,不需要八个矩阵,所以我们需要把这8个矩阵压缩成一个,我们怎么做呢?只需要把这些矩阵拼接起来然后用一个额外的权重矩阵与之相乘即可。
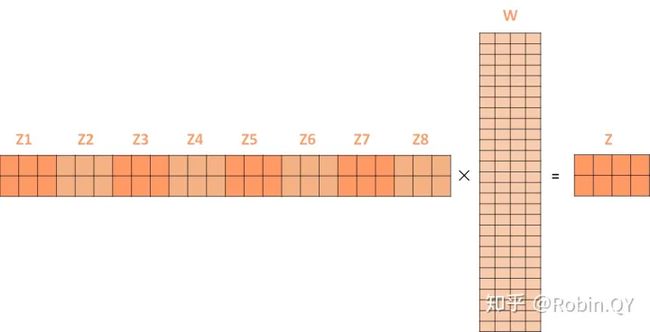
最终的Z就作为前馈神经网络的输入。
接下来就进入了小编码器里边的前馈神经网模块了,关于前馈神经网络,网上已经有很多资料,在这里就不做过多讲解了,只需要知道,前馈神经网络的输入是self-attention的输出,即上图的Z,是一个矩阵,矩阵的维度是(序列长度×D词向量),之后前馈神经网络的输出也是同样的维度。
以上就是一个小编码器的内部构造了,一个大的编码部分就是将这个过程重复了6次,最终得到整个编码部分的输出。
然后在transformer中使用了6个encoder,为了解决梯度消失的问题,在Encoders和Decoder中都是用了残差神经网络的结构,即每一个前馈神经网络的输入不光包含上述self-attention的输出Z,还包含最原始的输入。
上述说到的encoder是对输入(”机器学习“)进行编码,使用的是自注意力机制+前馈神经网络的结构,同样的,在decoder中使用的也是同样的结构。也是首先对输出(machine learning)计算自注意力得分,不同的地方在于,进行过自注意力机制后,将self-attention的输出再与Decoders模块的输出计算一遍注意力机制得分,之后,再进入前馈神经网络模块。
以上,就讲完了Transformer编码和解码两大模块,那么我们回归最初的问题,将“机器学习”翻译成“machine learing”,解码器输出本来是一个浮点型的向量,怎么转化成“machine learing”这两个词呢?
1.5 output
这个工作是最后的线性层接上一个softmax,其中线性层是一个简单的全连接神经网络,它将解码器产生的向量投影到一个更高维度的向量(logits)上,假设我们模型的词汇表是10000个词,那么logits就有10000个维度,每个维度对应一个惟一的词的得分。之后的softmax层将这些分数转换为概率。选择概率最大的维度,并对应地生成与之关联的单词作为此时间步的输出就是最终的输出啦!!
假设词汇表维度是6(一共6个词),那么输出最大概率词汇的过程如下:

以上就是Transformer的框架了,但是还有最后一个问题,我们都是到RNN中的每个输入是时序的,是又先后顺序的,但是Transformer整个框架下来并没有考虑顺序信息,这就需要提到另一个概念了:“位置编码”。
.2 位置编码
Transformer中确实没有考虑顺序信息,那怎么办呢,我们可以在输入中做手脚,把输入变得有位置信息不就行了,那怎么把词向量输入变成携带位置信息的输入呢?
我们可以给每个词向量加上一个有顺序特征的向量,发现sin和cos函数能够很好的表达这种特征,所以通常位置向量用以下公式来表示:

Transformers use a smart positional encoding scheme, where each position/index is mapped to a vector.
Hence, the output of the positional encoding layer is a matrix, where each row of the matrix represents an encoded object of the sequence summed with its positional information.
An example of the matrix that encodes only the positional information is shown in the figure below.

2.1 Positional Encoding Layer in Transformers
Let’s dive straight into this. Suppose you have an input sequence of length  and require the position of the
and require the position of the  object within this sequence. The positional encoding is given by sine and cosine functions of varying frequencies:
object within this sequence. The positional encoding is given by sine and cosine functions of varying frequencies:
注意单位是弧度制

代码:
import numpy as np
import matplotlib.pyplot as plt
def getPositionEncoding(seq_len, d, n=10000):
P = np.zeros((seq_len, d))
for k in range(seq_len):
for i in np.arange(int(d/2)):
denominator = np.power(n, 2*i/d)
P[k, 2*i] = np.sin(k/denominator)
P[k, 2*i+1] = np.cos(k/denominator)
return P
P = getPositionEncoding(seq_len=4, d=4, n=100)
print(P)
#------------output----------------
[[ 0. 1. 0. 1. ]
[ 0.84147098 0.54030231 0.09983342 0.99500417]
[ 0.90929743 -0.41614684 0.19866933 0.98006658]
[ 0.14112001 -0.9899925 0.29552021 0.95533649]]例子:


2.2 Understanding the Positional Encoding Matrix
To understand the positional encoding, let’s start by looking at the sine wave for different positions with n=10,000 and d=512.
def plotSinusoid(k, d=512, n=10000):
x = np.arange(0, 100, 1)
denominator = np.power(n, 2*x/d)
y = np.sin(k/denominator)
plt.plot(x, y)
plt.title('k = ' + str(k))
fig = plt.figure(figsize=(15, 4))
for i in range(4):
plt.subplot(141 + i)
plotSinusoid(i*4)The following figure is the output of the above code:

固定k,随着 i 的增大,三角函数的值的变化(可以看到每个位置(k)的sin函数图像都不一样)此时就可以去定义位置编码关系
You can see that each position k corresponds to a different sinusoid, which encodes a single position into a vector. If you look closely at the positional encoding function, you can see that the wavelength(振幅)for a fixed  is given by:
is given by:
Hence, the wavelengths of the sinusoids form a geometric progression and vary from 2π to 2πn. The scheme for positional encoding has a number of advantages.
- The sine and cosine functions have values in [-1, 1], which keeps the values of the positional encoding matrix in a normalized range.
- As the sinusoid for each position is different, you have a unique way of encoding each position.
- You have a way of measuring or quantifying the similarity between different positions, hence enabling you to encode the relative positions of words.(通过三角函数的特性去定义单词位置的特殊关系)
2.4 Visualizing the Positional Matrix
Let’s visualize the positional matrix on bigger values. Use Python’s matshow() method from the matplotlib library. Setting n=10,000 as done in the original paper, you get the following:
def getPositionEncoding(seq_len, d, n=10000):
P = np.zeros((seq_len, d))
for k in range(seq_len):
for i in np.arange(int(d/2)):
denominator = np.power(n, 2*i/d)
P[k, 2*i] = np.sin(k/denominator)
P[k, 2*i+1] = np.cos(k/denominator)
return P
P = getPositionEncoding(seq_len=100, d=512, n=10000)
cax = plt.matshow(P)
plt.gcf().colorbar(cax)d是词向量维度,n是词汇表总数
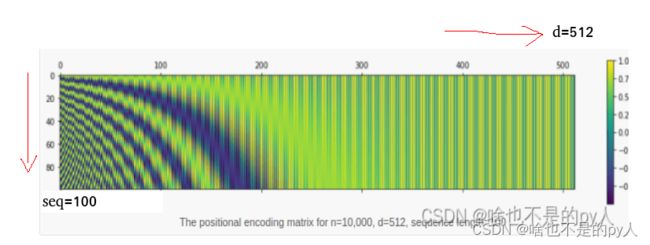
上代表随着 i 变大,周期在变大
n是用来控制振幅和周期的
可以看到seq中的每个位置的编码都不一致,这样就赋予了attention捕获位置的能力。

2.5 What Is the Final Output of the Positional Encoding Layer?
The positional encoding layer sums the positional vector with the word encoding and outputs this matrix for the subsequent layers. The entire process is shown below.

这样就将每个位置和其他位置的相关性量化出来了
参考:
A Gentle Introduction to Positional Encoding in Transformer Models, Part 1 - MachineLearningMastery.com
Transformer Architecture: The Positional Encoding - Amirhossein Kazemnejad's Blog
References
NLP中的RNN、Seq2Seq与attention注意力机制 - 知乎
The Illustrated Transformer – Jay Alammar – Visualizing machine learning one concept at a time.
保姆级教程:图解Transformer - 知乎
http://nlp.seas.harvard.edu/annotated-transformer/
https://arxiv.org/abs/1706.03762