DUBBO 机制详解
DUBBO 机制详解
-
- 1. 什么是 RPC
- 2. 什么是 Dubbo
- 3. dubbo 简单使用
-
- 3.1 启动注册中心 ZK
- 3.2 dubbo 服务提供者
- 3.3 dubbo 服务消费者
- 4. Dubbo 负载均衡策略
- 5. Dubbo 网络IO模型
-
- 5.1 dubbo 消费者连接池
- 5.2 Dubbo 发送和接受机制
-
- 发送机制
- 唯一ID
- DefaultFuture
- ThreadlessExecutor
- 接收机制
- 6. Dubbo 异步调用
- 7. Dubbo 可扩展机制
-
- 7.2 Dubbo SPI
1. 什么是 RPC
RPC:远程过程调用(Remote Rrocedure Call)是一个计算机通信协议,该协议允许运行一台计算机的程序调用另外一台计算机的子程序。
2. 什么是 Dubbo
dubbo:是一款高性能、轻量级的开源Java RPC框架。
- 基于透明接口的RPC (Dubbo提供了基于高性能接口的RPC,对用户是透明的)
- 智能负载均衡 (Dubbo开箱即用地支持多种负载平衡策略,该策略可感知下游服务状态以减少总体延迟并提高系统吞吐量)
- 自动服务注册和发现 (Dubbo支持多个服务注册表,可以立即检测在线/离线服务)
- 高扩展性 (Dubbo的微内核和插件设计确保第三方实现可以轻松地将其扩展为协议,传输和序列化等核心功能)
- 运行时流量路由 (可以在运行时配置Dubbo,以便可以根据不同的规则路由流量,这使得支持蓝绿色部署,数据中心感知路由等功能变得容易)
- 可视化服务治理 (Dubbo提供了用于服务管理和维护的丰富工具,例如查询服务元数据,运行状况和统计信息)
dubbo架构如下:
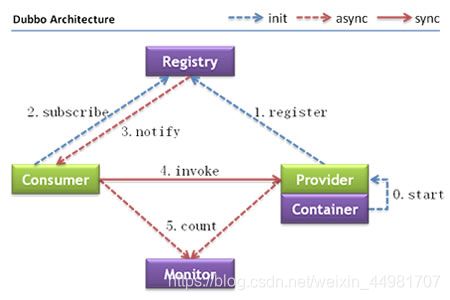
服务消费方调用服务提供方是基于网络协议调用的。
3. dubbo 简单使用
3.1 启动注册中心 ZK
首先去官网下载 zk,http://archive.apache.org/dist/zookeeper/。随便哪个版本都可以,然后解压到本地 windows。
然后进入 conf目录下,复制一份 zoo_sample.cfg文件,重新命名为 zoo.cfg。
进入 bin目录下,执行 zkServer.cmd 即可。zk 服务启动后如下,默认端口是 2182。

3.2 dubbo 服务提供者
这里以 springboot 整合 dubbo,版本是 2.0.6.RELEASE。
pom.xml 添加依赖
<dependency>
<groupId>org.apache.dubbogroupId>
<artifactId>dubbo-spring-boot-starterartifactId>
<version>2.7.8version>
dependency>
<dependency>
<groupId>com.101tecgroupId>
<artifactId>zkclientartifactId>
<version>0.10version>
dependency>
<dependency>
<groupId>org.apache.curatorgroupId>
<artifactId>curator-frameworkartifactId>
<version>4.2.0version>
dependency>
<dependency>
<groupId>org.apache.curatorgroupId>
<artifactId>curator-recipesartifactId>
<version>5.1.0version>
dependency>
application.yml 添加 dubbo配置项
dubbo:
application:
name: dubbo_provider
registry:
protocol: zookeeper # 注册中心为 dubbo
address: zookeeper://127.0.0.1:2181 # zk 的地址值
protocol:
name: dubbo # 通信协议
port: 20880 # dubbo 服务的端口
编写提供 dubbo 调用接口和实现类
public interface DubboProviderService {
String getMessage();
}
@DubboService(version = "1.1")
public class DubboProviderServiceImpl implements DubboProviderService{
@Override
public String getMessage() {
return "调用成功";
}
}
启动类添加 @EnableDubbo 注解,启动启动类即可
可以通过 zkCli 查看 dubbo 服务提供者注册到 ZK 节点内容
[zk: localhost:2181(CONNECTED) 48] ls /dubbo/com.luo.zhi.dubbo.DubboProviderService/providers
[dubbo%3A%2F%2F192.168.1.103%3A20880%2Fcom.luo.zhi.dubbo.DubboProviderService%3Fanyhost%3Dtrue%26application%3Ddubbo_provider%26deprecated%3Dfalse%26dubbo%3D2.0.2%26dynamic%3Dtrue%26generic%3Dfalse%26interface%3Dcom.luo.zhi.dubbo.DubboProviderService%26metadata-type%3Dremote%26methods%3DgetMessage%2CgetMessage3%2CgetMessage2%2CgetMessage1%26pid%3D20684%26release%3D2.7.8%26revision%3D1.1%26side%3Dprovider%26threads%3D3000%26timestamp%3D1651038547844%26version%3D1.1]
3.3 dubbo 服务消费者
以 springboot 整合 dubbo,版本是 2.0.6.RELEASE。
pom.xml 需要添加依赖和服务提供者一样,这里不展示。
application.yml 添加 dubbo配置项
dubbo:
application:
name: dubbo_consumer
registry:
protocol: zookeeper # 注册中心使用 zk
address: zookeeper://127.0.0.1:2181 # zk 的地址值
编写 dubbo 调用类
// 这个接口要和提供者接口 全限定类名一样
public interface DubboProviderService {
String getMessage();
}
@RestController
@RequestMapping("/dubbo")
public class DubboController {
@DubboReference(version = "1.1")
DubboProviderService dubboProviderService;
@GetMapping("/getMessage")
public String getUser(Integer id) {
return dubboProviderService.getMessage();
}
}
启动类添加 @EnableDubbo 注解,启动启动类即可。调用 controller 层
异步调用方式
@RestController
@RequestMapping("/dubbo")
public class DubboController {
@DubboReference(version = "1.1", timeout = 5000)
DubboProviderService dubboProviderService;
@DubboReference(version = "1.1", async = true, timeout = 5000)
DubboProviderService dubboProviderService1;
@GetMapping("/getMessage")
public String getUser(Integer id) {
String message = dubboProviderService.getMessage();
System.out.println("2222222222222222");
return message;
}
@GetMapping("/getMessage1")
public String getUser1(Integer id) throws ExecutionException, InterruptedException {
String message = dubboProviderService1.getMessage();
System.out.println("2222222222222222");
Future<String> future = RpcContext.getContext().getFuture();
return future.get();
}
}
4. Dubbo 负载均衡策略
在分布式系统中,负载均衡是必不可少的一个模块,dubbo 中提供了五种负载均衡的实现。
| 类型 | 说明 | 是否默认 | 是否加权(权重) |
|---|---|---|---|
| RandomLoadBalance | 随机 | 是 | 是,默认权重相同 |
| RoundRobinLoadBalance | 轮询 | 否 | 是,默认权重相同 |
| LeastActiveLoadBalance | 最少活跃数调用 | 否 | 不完全是,默认权重相同;仅在活跃数相同时按照权重比随机 |
| ConsistentHashLoadBalance | 一致性hash | 否 | 否 |
| ShortestResponseLoadBalance | 最短时间调用 | 否 | 不完全是,默认权重相同;仅在预估调用相同时按照权重比随机 |
我们可以通过设置 dubbo 消费者负载均衡策略达到不同的调度效果,当然高版本 dubbo 负载均衡策略远比想象中的复杂。比如:dubbo 生产者集群中某台服务器阻塞时间很久,dubbo 消费者会动态降点该节点的权重(weight),让更多的流量请求到正常的节点。
使用方式如下
@DubboReference(version = "1.1", timeout = 5000, connections = 5, loadbalance = "roundrobin")
5. Dubbo 网络IO模型
Dubbo 缺省协议采用单一长连接和多路复用器的 NIO 异步通信架构。非常适合小数据量大并发的服务调用。
这里会有一个问题,如果消费者(C)并发调用提供者(P),在使用单一连接的情况下,如何区分请求和响应的呢?
答:请求参数携带一个唯一 ID,然后传递给服务端,再服务端又回传回来,这样就知道返回的结果是属于哪个线程的了。
5.1 dubbo 消费者连接池
默认是采用单一长连接的,我们在 dubbo 消费者服务启动的时候直接看 DubboProtocol.getClients(URL url)方法,该方法会判断针对每一个 Reference 的 URL 生成连接个数,以及连接是否共享。
private ExchangeClient[] getClients(URL url) {
// 是否共享连接,默认是不共享连接
boolean useShareConnect = false;
/**
从Reference 的 url 中获取普通连接数,connections
connections 参数默认为 0,可以配置
*/
int connections = url.getParameter(CONNECTIONS_KEY, 0);
List<ReferenceCountExchangeClient> shareClients = null;
if (connections == 0) {
// 如果 Reference 的普通连接数是0,则开启共享连接
useShareConnect = true;
// 获取 Reference 的共享连接数
String shareConnectionsStr = url.getParameter(SHARE_CONNECTIONS_KEY, (String) null);
connections = Integer.parseInt(StringUtils.isBlank(shareConnectionsStr) ? ConfigUtils.getProperty(SHARE_CONNECTIONS_KEY,
DEFAULT_SHARE_CONNECTIONS) : shareConnectionsStr);
// 生成共享连接
shareClients = getSharedClient(url, connections);
}
// 每个 Reference 都有自己的连接池 clients
ExchangeClient[] clients = new ExchangeClient[connections];
for (int i = 0; i < clients.length; i++) {
// 判断是否共享连接
if (useShareConnect) {
// 从共享连接池中拿取
clients[i] = shareClients.get(i);
} else {
// 初始化生成非共享连接
clients[i] = initClient(url);
}
}
return clients;
}
问题:什么是共享连接和非共享连接?
答:由于同一个服务提供者机器可以提供多个服务,比如服务 A、服务 B,那么消费者Reference 服务 A、服务 B,由于服务 A、和服务 B的 ip 和 端口是一样的,在调用这两个服务完全可以共用 socket。
- 所谓共享连接,就是消费者调用服务 A、服务 B 可以共用 socket。
- 而非共享连接,则是消费者调用服务 A、服务 B 不共用 socket。
非共享连接旨在每个 Reference 的服务请求量、策略不一样,这样消费者可以针对每个 Reference 的服务配置不同的策略。
5.2 Dubbo 发送和接受机制
多个线程请求共用一个 socket连接,当数据返回时,怎么区分数据属于哪个线程;以及 dubbo 虽然是 NIO 模型,但默认实现的是同步调用等,这些问题都在本节中一一解决。
发送机制
DubboInvoker.doInvoke 方法是发送请求的核心方法
@Override
protected Result doInvoke(final Invocation invocation) throws Throwable {
RpcInvocation inv = (RpcInvocation) invocation;
final String methodName = RpcUtils.getMethodName(invocation);
inv.setAttachment(PATH_KEY, getUrl().getPath());
inv.setAttachment(VERSION_KEY, version);
ExchangeClient currentClient;
if (clients.length == 1) {
currentClient = clients[0];
} else {
// index.getAndIncrement()是通过cas原子操作自增
// 每次请求相当于轮询方式拿取连接池连接,如果只有一个,每次获取的都是一样的
currentClient = clients[index.getAndIncrement() % clients.length];
}
try {
boolean isOneway = RpcUtils.isOneway(getUrl(), invocation);
int timeout = calculateTimeout(invocation, methodName);
if (isOneway) {
boolean isSent = getUrl().getMethodParameter(methodName, Constants.SENT_KEY, false);
currentClient.send(inv, isSent);
return AsyncRpcResult.newDefaultAsyncResult(invocation);
} else {
// 获取执行器,里面会 new 一个 ThreadlessExecutor对象
ExecutorService executor = getCallbackExecutor(getUrl(), inv);
CompletableFuture<AppResponse> appResponseFuture =
currentClient.request(inv, timeout, executor).thenApply(obj -> (AppResponse) obj);
// save for 2.6.x compatibility, for example, TraceFilter in Zipkin uses com.alibaba.xxx.FutureAdapter
FutureContext.getContext().setCompatibleFuture(appResponseFuture);
AsyncRpcResult result = new AsyncRpcResult(appResponseFuture, inv);
// 将执行器添加到 AsyncRpcResult
result.setExecutor(executor);
return result;
}
} catch (TimeoutException e) {
throw new RpcException(RpcException.TIMEOUT_EXCEPTION, "Invoke remote method timeout. method: " + invocation.getMethodName() + ", provider: " + getUrl() + ", cause: " + e.getMessage(), e);
} catch (RemotingException e) {
throw new RpcException(RpcException.NETWORK_EXCEPTION, "Failed to invoke remote method: " + invocation.getMethodName() + ", provider: " + getUrl() + ", cause: " + e.getMessage(), e);
}
}
进入到 HeaderExchangeChannel.request 方法,该方法会封装 Request 请求参数,并调用 NettyClient(底层是 NIO 模型的 Socket连接)发送请求。
public CompletableFuture<Object> request(Object request, int timeout, ExecutorService executor) throws RemotingException {
if (closed) {
throw new RemotingException(this.getLocalAddress(), null, "Failed to send request " + request + ", cause: The channel " + this + " is closed!");
}
// 封装 Request 对象,并生成唯一 ID。
Request req = new Request();
req.setVersion(Version.getProtocolVersion());
req.setTwoWay(true);
req.setData(request);
// 这个代码很重要
DefaultFuture future = DefaultFuture.newFuture(channel, req, timeout, executor);
try {
// 发送请求
channel.send(req);
} catch (RemotingException e) {
future.cancel();
throw e;
}
return future;
}
唯一ID
上文我们说过每个 PRC 请求参数会携带一个唯一 ID,用来区分请求和响应是哪个线程,这里唯一ID 跟下面代码有关:
Request req = new Request();
// 构造函数
public Request() {
mId = newId();
}
private static long newId() {
// getAndIncrement()方法通过 cas原子操作自增1
return INVOKE_ID.getAndIncrement();
}
// INVOKE_ID 是Request 的静态 final 变量。
private static final AtomicLong INVOKE_ID = new AtomicLong(0);
看到这里我们明白了唯一ID是怎么生成了,使用 AtomicLong 从 0 开始自增。
DefaultFuture
每个线程在进行 RPC 调用时,都拥有自己唯一的 DefaultFuture 对象。我们来看另外一个重要的代码,HeaderExchangeChannel.request 中的 DefaultFuture.newFuture 方法。
......
DefaultFuture future = DefaultFuture.newFuture(channel, req, timeout, executor)
......
》》》》》》》》》》》
// 创建 DefaultFuture 对象的方法
// 参数:nettyClient, requet请求参数,超时实际timeout,ThreadlessExecutor执行器
public static DefaultFuture newFuture(Channel channel, Request request, int timeout, ExecutorService executor) {
// 调用构造方法
final DefaultFuture future = new DefaultFuture(channel, request, timeout);
// 将 ThreadlessExecutor执行器添加进 DefaultFuture
future.setExecutor(executor);
// ThreadlessExecutor needs to hold the waiting future in case of circuit return.
if (executor instanceof ThreadlessExecutor) {
((ThreadlessExecutor) executor).setWaitingFuture(future);
}
// timeout check
timeoutCheck(future);
return future;
}
》》》》》》》》》》》
// DefaultFuture 构造方法
private DefaultFuture(Channel channel, Request request, int timeout) {
this.channel = channel;
this.request = request;
this.id = request.getId();
this.timeout = timeout > 0 ? timeout : channel.getUrl().getPositiveParameter(TIMEOUT_KEY, DEFAULT_TIMEOUT);
// 重点,将唯一ID 和 DefaultFuture 自身添加进 FUTURES(一个Map)
FUTURES.put(id, this);
CHANNELS.put(id, channel);
}
每一个 RPC 调用都有唯一的 DefaultFuture 对象 和 唯一ID,它们被添加到全局 FUTURES中
DefaultFuture 类简介如下:
public class DefaultFuture extends CompletableFuture<Object> {
......省略
// FUTURES 是静态 final 变量
private static final Map<Long, DefaultFuture> FUTURES = new ConcurrentHashMap<>();
// ThreadlessExecutor 执行器
private ExecutorService executor;
// 通过 唯一ID 获取 DefaultFuture 对象
public static DefaultFuture getFuture(long id) {
return FUTURES.get(id);
}
......省略
}
DefaultFuture 还有另外一个重要的变量, ThreadlessExecutor。它封装了阻塞队列,是实现请求线程阻塞,响应唤醒的关键所在。
在调用 channel.send(req) 方法发送请求后,线程继续往下执行,回到 DubboInvoker.doInvoke 方法
@Override
protected Result doInvoke(final Invocation invocation) throws Throwable {
......省略
// 这个类代表一个未完成的RPC调用,它将为这个调用保留一些上下文信息,例如RpcContext和Invocation,
AsyncRpcResult result = new AsyncRpcResult(appResponseFuture, inv);
// AsyncRpcResult 也保存了 ThreadlessExecutor执行器
result.setExecutor(executor);
// 返回 AsyncRpcResult
return result;
......省略
}
代码继续往下执行到,AsyncToSyncInvoker.invoke 方法
@Override
public Result invoke(Invocation invocation) throws RpcException {
......省略
// 跟进去
asyncResult.get(Integer.MAX_VALUE, TimeUnit.MILLISECONDS);
......省略
}
AsyncRpcResult.get 方法,该方法会调用 threadlessExecutor执行器
@Override
public Result get(long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException {
if (executor != null && executor instanceof ThreadlessExecutor) {
ThreadlessExecutor threadlessExecutor = (ThreadlessExecutor) executor;
// 执行响应任务
threadlessExecutor.waitAndDrain();
}
return responseFuture.get(timeout, unit);
}
ThreadlessExecutor
public class ThreadlessExecutor extends AbstractExecutorService {
// 每个 ThreadlessExecutor 对象都有一个阻塞队列
private final BlockingQueue<Runnable> queue = new LinkedBlockingQueue<>();
/**
一次RPC调用只会执行这个方法一次,它会通过向 阻塞queue 拿取任务,如果没有,线程则会阻塞。当响应任务到达,线程又会被唤醒。继续执行任务。
这里要注意,一次RPC调用是一个线程,这个线程的阻塞和唤醒都是又阻塞队列BlockingQueue完成的。
*/
public void waitAndDrain() throws InterruptedException {
if (finished) {
return;
}
// 从阻塞队列读取响应任务,如果没有响应任务,等待添加响应任务唤醒线程
Runnable runnable = queue.take();
synchronized (lock) {
waiting = false;
runnable.run();
}
// 如果队列后续还有任务 则直到执行完才结束
runnable = queue.poll();
while (runnable != null) {
try {
runnable.run();
} catch (Throwable t) {
logger.info(t);
}
runnable = queue.poll();
}
// 标记 ThreadlessExecutor执行器 已经完成
// mark the status of ThreadlessExecutor as finished.
finished = true;
}
/**
如果调用线程仍在等待回调任务,则将任务添加到阻塞队列中以等待调度。
否则,直接提交给共享回调执行器。
*/
@Override
public void execute(Runnable runnable) {
synchronized (lock) {
if (!waiting) {
// 如果 rpc调用线程不是等待阻塞状态,则用共享线程池来处理响应任务
sharedExecutor.execute(runnable);
} else {
// 如果 rpc调用线程是等待阻塞状态,则通过 阻塞队列add方法添加唤醒
queue.add(runnable);
}
}
}
}
那么dubbo 消费者在接收到响应数据时,怎么找到对应的 ThreadlessExecutor执行器,调用 execute 方法呢?还记得我们之前将 唯一ID : DefaultFuture 存入 FUTURES(Map)中,而 DefaultFuture 对象中有 ThreadlessExecutor执行器变量。所以只需要通过 唯一ID,能找到对应的 ThreadlessExecutor执行器执行execute,就能唤醒对应的线程。我们来看 dubbo 是不是这样做的。
接收机制
Dubbo 是基于 Netty 实现的 NIO 网络模型,我们直接找 NettyClientHandler.channelRead 方法。
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
NettyChannel channel = NettyChannel.getOrAddChannel(ctx.channel(), url, handler);
// 跟进去
handler.received(channel, msg);
}
一直 debug 到 AllChannelHandler.received 方法
@Override
public void received(Channel channel, Object message) throws RemotingException {
// 获取 ThreadlessExecutor执行器
ExecutorService executor = getPreferredExecutorService(message);
try {
// 调用 ThreadlessExecutor.execute 方法。这个方法我们上面介绍过。添加任务、唤醒阻塞线程
executor.execute(new ChannelEventRunnable(channel, handler, ChannelState.RECEIVED, message));
} catch (Throwable t) {
if(message instanceof Request && t instanceof RejectedExecutionException){
sendFeedback(channel, (Request) message, t);
return;
}
throw new ExecutionException(message, channel, getClass() + " error when process received event .", t);
}
}
WrappedChannelHandler.getPreferredExecutorService 方法获取 ThreadlessExecutor执行器
public ExecutorService getPreferredExecutorService(Object msg) {
if (msg instanceof Response) {
Response response = (Response) msg;
// 这个方法上文介绍过,通过 唯一ID 获取 DefaultFuture对象
DefaultFuture responseFuture = DefaultFuture.getFuture(response.getId());
// a typical scenario is the response returned after timeout, the timeout response may has completed the future
if (responseFuture == null) {
return getSharedExecutorService();
} else {
// 通过 DefaultFuture对象 获取成员变量 ThreadlessExecutor执行器
ExecutorService executor = responseFuture.getExecutor();
if (executor == null || executor.isShutdown()) {
executor = getSharedExecutorService();
}
// 返回 ThreadlessExecutor执行器
return executor;
}
} else {
return getSharedExecutorService();
}
}
跟到这里是不是跟我们上文猜想的一样。
总结,每个线程在进行 RPC 调用时,都拥有自己唯一的 DefaultFuture 对象,每个 DefaultFuture 对象对应一个 唯一ID 添加到全局 FUTURES 中。发送数据、响应数据都会携带 唯一ID ,当响应数据的时候,也会以 唯一ID 获取对应的 DefaultFuture 对象。而 DefaultFuture 实现了,线程获取任务阻塞,添加任务唤醒的线程功能,本质是靠成员 ThreadlessExecutor 执行器完成,而 ThreadlessExecutor 对象则是封装了阻塞队列来完成这功能。
6. Dubbo 异步调用
dubbo 提供的调用方式默认使用的是同步阻塞调用。由于上文讲了 dubbo 的网络模型是 NIO,所以它天然的支持异步 IO 请。
使用方式如下
public class DubboController {
@DubboReference(version = "1.1", timeout = 5000, connections = 5, loadbalance = "roundrobin")
DubboProviderService dubboProviderService;
// 开启异步方式
@DubboReference(version = "1.1", async = true, timeout = 5000, connections = 5)
DubboProviderService dubboProviderService1;
@GetMapping("/getMessage")
public String getUser(Integer id) throws ExecutionException, InterruptedException {
dubboProviderService1.getMessage();
// dubbo 集成 CompletableFuture 异步工具类
CompletableFuture<String> completableFuture = RpcContext.getContext().getCompletableFuture();
// 做其他事情
doOtherThings();
// 获取异步调用结果
String res = completableFuture.get();
return res;
}
}
7. Dubbo 可扩展机制
- SPI思想是什么?
SPI的全名为Service Provider Interface。是JDK内置的一种 服务提供发现机制,为某个接口寻找服务实现机制。
- 为什么要这个东西?
面向的对象的设计里,我们一般推荐模块之间基于接口编程,模块之间不对实现类进行硬编码。一旦代码里涉及具体的实现类,就违反了可拔插的原则,如果需要替换一种实现,就需要修改代码。为了实现在模块装配的时候不用在程序里动态指明,这就需要一种服务发现机制。java spi就是提供这样的一个机制:为某个接口寻找服务实现的机制。这有点类似IOC的思想,将装配的控制权移到了程序之外。同时起到解耦的作用。
- JDBC SPI体现
https://blog.csdn.net/qq_38712932/article/details/82987865
- Java SPI技术实现
首先有一个接口

再有接口实现多个。我这里就列举一个

在resources/META-INF/services生成文件,文件名是接口的全限定类名

文件内容是接口实现类的全限定类名

实现

不足点:
- 不能按需加载,需要遍历所有的实现,并实例化,然后在循环中才能找到我们需要的实现。如果不想用某些实现类,或者某些类实例化很耗时,它也被载入并实例化了,由此造成了浪费。
- 获取某个实现类的方式不够灵活,只能通过Iterator形式获取,不能根据某个参数来获取对应的实现类。
- 多个并发多线程使用ServiceLoader类的实例是不安全的
7.2 Dubbo SPI
// TODO
感悟:
疑问:为啥dubbo加载配置文件和其它数据,都是先看缓存中是否有,没有则生成加入到缓存。而不是一开始初始化缓存,需要直接从缓存中获取。
答:这种方案更能拥抱变化,比如配置文件改变了。
ClassLoader加载目录文件?
Class类是Java反射机制的起源和入口,用于获取与类相关的各种信息,提供了获取类信息的相关方法。
javassist.CtClass/javassist.ClassPool 实现动态代理-