处理器架构 指令集
区分处理器架构 指令集 微处理器架构
0前提知识
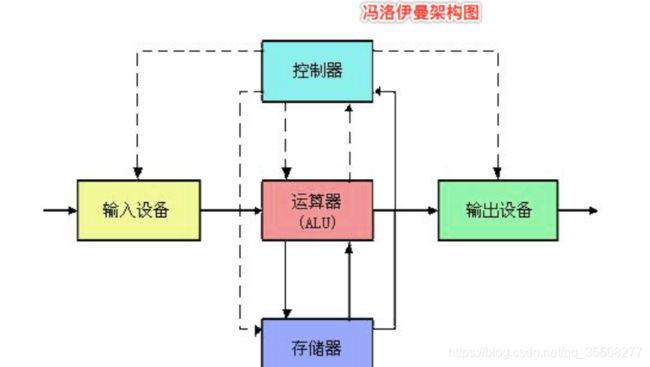
数字系统需要三个主要的组成部分:
- 计算对位进行操作的函数的组合逻辑(ALU)
- 存储位的存储器元素(寄存器)
- 控制存储器元素更新的时钟信号
指令
处理器完成一条指令过程
取指令、指令译码和执行指令
- 取指(fetch)
取值阶段从存储器读取指令字节,放到指令存储器(CPU中)中,地址为程序计数器(PC)的值。
它按顺序的方式计算当前指令的下一条指令的地址(即PC的值加上已取出指令的长度) - 译码(decode)
ALU从寄存器文件(通用寄存器的集合)读入最多两个操作数。(即一次最多读取两个寄存器中的内容) - 执行(execute)
在执行阶段会根据指令的类型,将算数/逻辑单元(ALU)用于不同的目的。对其他指令,它会作为一个加法器来计算增加或减少栈指针,或者计算有效地址,或者只是简单地加0,将一个输入传递到输出。
条件码寄存器(CC)有三个条件位。ALU负责计算条件码新值。当执行一条跳转指令时,会根据条件码和跳转类型来计算分支信号cnd。
时钟周期
机器周期
指令周期
程序
我们在编写程序的时候其实可以对程序的代码划分为两个部分,
一部分是程序编写完成后就不再需要对其进行修改了的(也就是逻辑代码部分)指令
另一部分就是在程序编写完毕后其内容会随着程序的运行而不断变化的部分(也就是定义变量)。数据
而哈佛结构和冯诺依曼结构就是对于这个两部分代码的存储方式的区别。
注
处理器架构和处理器指令集没有特别的对应关系。
采用x86指令集也可以用MIPS的微结构,MIPS的指令集也可以用在x86处理器的微结构上。
指令集不决定处理器的架构
1指令集架构(Instruction Set Architecture,ISA)
一个处理器支持的指令和指令的字节级编码称为它的指令集体系结构ISA。规定了处理器如何识别这些汇编指令,以及如何与上层交互。
如在有的指令集里面,0000代表add,所以同样的二进制串在不同的指令集下有不同的解读。
CISC(复杂指令集)
(Complex Instruction Set Computer)】
intel 的x86,
精简指令集(RISC)
Reduced Instruction Set Computer
在中高档服务器中采用RISC指令的CPU主要有Compaq(康柏,即新惠普)公司的Alpha、HP公司的PA-RISC、IBM公司的PowerPC、MIPS公司的MIPS和SUN公司的Sparc。
区别
1.指令系统:RISC设计者把主要精力放在那些经常使用的指令上,尽量使它们具有简单高效。对不常用的功能,常通过组合指令来完成。因此,在RISC计算机上实现特殊功能时,效率可能较低。但可以利用流水技术和超标量技术加以改进和弥补。而CISC计算机的指令系统比较丰富,有专用指令来完成特定的功能。因此,处理特殊任务效率较高。
2.存储器操作:RISC对存储器操作有限制,使控制简单化;而CISC计算机的存储器操作指令多,操作直接。
3.程序:CISC汇编语言程序一般需要较大的内存空间,实现特殊功能时程序复杂,不易设计;而RISC汇编语言程序编程相对简单,科学计算及复杂操作的程序设计相对容易,效率较高。
4.中断:RISC计算机在一条指令执行的适当地方可以响应中断,但是相比CISC指令执行的时间短,所以中断响应及时;而CISC计算机是在一条指令执行结束后响应中断。
5.CPU:RISC CPU包含有较少的单元电路,因而面积小、功耗低;而CISCCPU包含有丰富的电路单元,因而功能强、面积大、功耗大。
6.设计周期:RISC微处理器结构简单,布局紧凑,设计周期短,且易于采用最新技术;CISC微处理器结构复杂,设计周期长。
7.用户使用:RISC微处理器结构简单,指令规整,性能容易把握,易学易用;CISC微处理器结构复杂,功能强大,实现特殊功能容易。
8.应用范围:由于CISC指令系统的确定与特定的应用领域有关,故CISC计算机更适合于专用机;而RISC计算机则更适合于通用机。
2 处理器结构 (CPU架构)
CPU体系结构,处理器体系结构,中央处理器体系结构。。。whatever
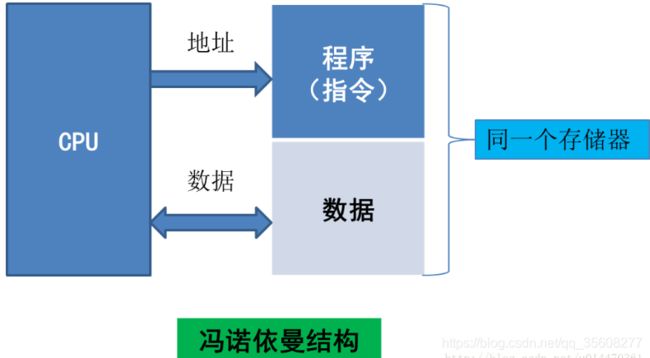
冯诺依曼结构
又称作普林斯顿体系结构(Princetionarchitecture)。就是我们所说的X86架构
结构特点
核心是:数据和指令混在一起,统一编址。将程序指令存储器和数据存储器合并在一起的存储器结构。
取指令和取操作数都在同一总线上,通过分时复用的方式进行。共享同一总线的结构,使得信息流的传输成为限制计算机性能的瓶颈,影响了数据处理速度的提高。如图

由于程序指令存储地址和数据存储地址指向同一个存储器的不同物理位置,因此程序指令和数据的宽度相同。
区分哪些是指令和哪些是数据大致上有以下方法:
1、用寄存器和指令周期来区分数据和指令。例如:CS段(codesegment代码段)和DS段(datasegment数据段),前者CPU是认为存放的都是指令,后者CPU认为存放的都是数据;
2、通过不同的时间段来区分指令和数据,在取指阶段取出的就是指令,执行阶段取出的就是数据。
优缺点
结构简单、易实现、成本低,但效率偏低

eg
Intel公司的X86微处理器
冯诺依曼结构主要是基于电脑购买者对电脑的使用途径不同—-各种娱乐型用户、各种专业开发用户等,且安装的软件的种类繁多,升级频繁,多种软件同时运行时处理的优先级比较模糊,因特尔芯片不具备彻底智能分配各程序优先级和流水线的机制,机械的分配优先和流水线反而容易使用户不便。
arm7系列的CPU有很多款,其中部分CPU没有内部cache的,比如arm7TDMI,就是纯粹的冯·诺依曼结构,其他有内部cache且数据和指令的cache分离的cpu则使用了哈弗结构。
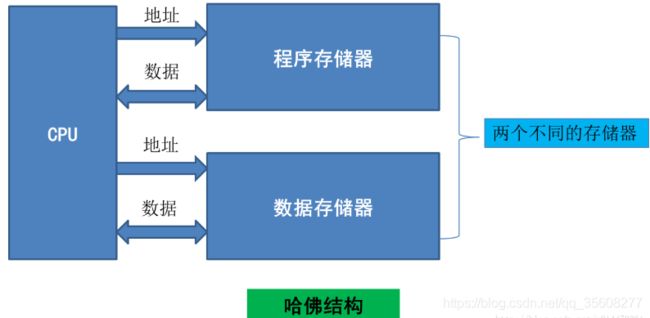
哈佛架构
结构特点
数据和指令是区分开的。独立编址,就算地址一样,数据也是不一样的。所以指令和数据可以有不同的数据宽度,如Microchip公司的PIC16芯片的程序指令是14位宽度,而数据是8位宽度。
采用哈佛结构,由于取指令和存取数据分别经由不同的存储空间和不同的总线,使得各条指令可以重叠执行,这样,也就克服了数据流传输的瓶颈,提高了运算速度。 哈佛结构强调了总的系统速度以及通讯和处理器配置方面的灵活性。目的是为了减轻程序运行时的访存瓶颈。
例如最常见的卷积运算中, 一条指令同时取两个操作数, 在流水线处理时, 同时还有一个取指操作, 如果程序和数据通过一条总线访问, 取指和取数必会产生冲突, 而这对大运算量的循环的执行效率是很不利的。 哈佛结构能基本上解决取指和取数的冲突问题。

优缺点
结构效率高但复杂,对外围设备的连接与处理要求高,十分不适合外围存储器的扩展

eg
目前使用哈佛结构的中央处理器和微控制器有很多,DSP和ARM为代表.
哈佛机构的高性能体现在在单片机、DSP芯片平台上运行的程序种类和花样较少,因为各个电子娱乐产品中的软件升级比较少,应用程序可以用汇编作为内核,最高效率的利用流水线技术,获得最高的效率。
除了Microchip公司的PIC系列芯片,还有摩托罗拉公司的MC68系列、Zilog公司的Z8系列、ATMEL公司的AVR系列和ARM公司的ARM9、ARM10和ARM11。
改进型哈佛结构
改进型哈佛结构虽然也使用两个不同的存储器:程序存储器和数据存储器,但它把两个存储器的地址总线合并了,数据总线也进行了合并,即原来的哈佛结构需要4条不同的总线,改进后需要两条总线。
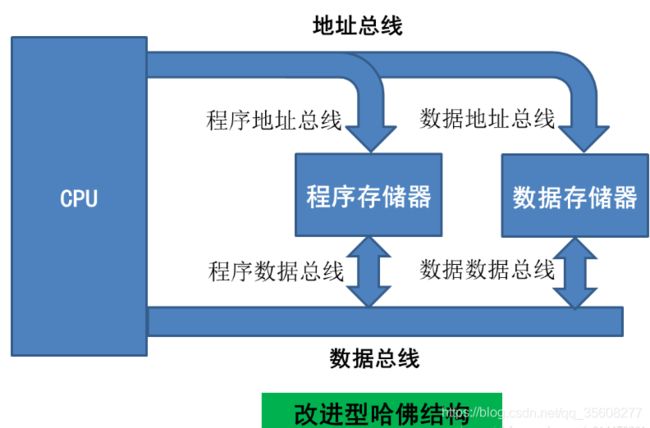
结构特点
使用两个独立的存储器模块,分别存储指令和数据,每个存储模块都不允许指令和数据并存,以便实现并行处理;
具有一条独立的地址总线和一条独立的数据总线,利用公用地址总线访问两个存储模块(程序存储模块和数据存储模块),公用数据总线则被用来完成程序存储模块或数据存储模块与CPU之间的数据传输;
两条总线由程序存储器和数据存储器分时共用。
eg
现在的处理器,依托CACHE的存在,已经很好的将二者统一起来了。现在的处理器虽然外部总线上看是诺依曼结构的,但是由于内部CACHE的存在,因此实际上内部来看已经类似改进型哈佛结构的了。
3 处理器微结构(micro-architecture)
处理器识别了这些指令之后,如何执行这些指令就是微结构的事情。比如你可以设计三个加法ALU,在一个周期里面同时执行三条加法指令,也可以设计一个加法+两个乘法ALU,在一个周期里面同时执行一条加法+两条乘法指令。
4基于公司的架构
arm架构
arm公司