word2vec原理+代码
文章目录
- 参考
- word2vec 简单解释
- 提速方法
-
- Hierarchical Softmax
- Negative Sampling
- word2vec提取关键词
- word2vec keras 版代码
网上关于Word2vec的介绍有很多,由于在graph embedding中word2vec的广泛应用以及打算整理一版word embedding的系列内容,这里把word2vec单独拉开来讲。
关于graph embedding的更多内容:
graph embedding第一篇——deepwalk and line
graph embedding 第二篇 node2vec and sdne
graph embedding在大厂中的应用
参考
word2vec数学讲解
Keras版的Word2Vec
【不可思议的Word2Vec】 3.提取关键词
从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史
word2vec 简单解释
word2vec有两个训练方案,分别为CBOW和skip-gram:
- CBOW使用周围词预测中心词,即 p ( w t ∣ c o n t e x t ) p(w_t|context) p(wt∣context)
- skip-gram 使用中心词,预测周围词,即 p ( c o n t e x t ∣ w t ) p(context|w_t) p(context∣wt)
其架构图如下图所示:

而不论是CBOW 还是 skip-gram,计算 p p p的时候,其归一化因子要sum整个语料库的内容,计算量巨大,因此提出两种算法提升计算速度,他们分别是Hierarchical Softmax和Negative Sampling。
word2vec的缺陷:
word2vec无法处理同义词,比如bank,可以是银行也可以是河岸,但是使用word2vec得到的结果都是一样的。
这里就不详细去写CBOW和skip-gram架构如何训练,接下来主要介绍两种提速方式。
提速方法
Hierarchical Softmax
以CBOW为例,介绍层次softmax:

- 输入层是包含 2 c 2c 2c个词的词向量
- 投影层, x w = ∑ i = 1 2 c v ( c o n t e x t ( w i ) ) x_w=\sum_{i=1}^{2c} v(context(w_i)) xw=∑i=12cv(context(wi))
- 输出层,输出层对应一颗二叉树,其叶子节点对应其词,因此,共有 ∣ D ∣ |D| ∣D∣个叶子节点,其非叶子节点的值记为 θ \theta θ,如果 σ ( x w θ ) \sigma(x_w \theta) σ(xwθ)为1,则进入左节点,否则进入右节点。
举例说明,比如说,使用【足球】的周围词预测【足球】:

令 d j w d_j^w djw表示词 w w w的Huffman编码,他是一个非0即1的值。
我们不难写出其条件概率为:
p ( d j w ∣ x w , θ j − 1 w ) = [ σ ( x w T θ j − 1 w ) ] 1 − d j w ⋅ [ 1 − σ ( x w T θ j − 1 w ) ] d j w ] p(d_j^w|x_w,\theta_{j-1}^w)=[\sigma(x_w^T\theta_{j-1}^w)]^{1-d_j^w} \cdot [1-\sigma(x_w^T\theta_{j-1}^w)]^{d_j^w}] p(djw∣xw,θj−1w)=[σ(xwTθj−1w)]1−djw⋅[1−σ(xwTθj−1w)]djw]
那么目标函数就出来了:
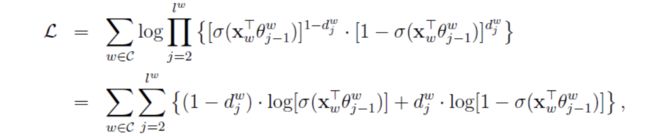
接下来要做的就是求梯度等等操作了。skip-gram和这个类似,就不细说了。
Negative Sampling
Negative sampling用于提高训练速度和改善所得词向量的质量。可以作为层次softmax的一种替代。该想法主要是抽取负样本的想法。那么对于给定的词 w w w,如何抽取其负样本呢?
词典 D D D中的词在语料库 C C C中出现的频次有高有低,我们希望,那么高频词被负采样的概率高,低频次被负采样的概率低。
令 l e n ( w ) = c o u n t e r ( w ) α ∑ i c o u n t e r ( w i ) α , α = 0.75 len(w)=\frac{counter(w)^\alpha}{\sum_i counter(w_i)^\alpha}, \alpha=0.75 len(w)=∑icounter(wi)αcounter(w)α,α=0.75,记 l 0 = 0 , l k = ∑ j = 0 k l e n ( w j ) l_0=0,l_k=\sum_{j=0}^k len(w_j) l0=0,lk=∑j=0klen(wj), w j w_j wj 表示词典D的第j个词,不难得知, l l l为[0,1]区间的递增序列,并令 I i = ( l i − 1 , l i ] , i = 1 , 2 , ⋯ , N I_i=(l_{i-1},l_i],i=1,2,\cdots,N Ii=(li−1,li],i=1,2,⋯,N为其中的一个区间,该划分是非等距的。进一步,引入等距剖分,划分 M M M个等距点,有 M > > N M>>N M>>N。具体见下图:

可以得到 m i m_i mi到 I j I_j Ij的映射关系,接下来就是每次从 [ 1 , M − 1 ] [1,M-1] [1,M−1]生成一个随机整数 r r r, m r m_r mr对应的 I k ⇒ w k I_k⇒ w_k Ik⇒wk即为所采样的样本。
word2vec提取关键词
来源于苏神的思路
更多关于关键词提取的算法:
关键词提取技术——无监督方法
关键词提取——有监督方法
关键词提取技术本质上是可以通过关键词获取到文章大意,也就是说,我们的目标是让 p ( s ∣ w i ) p(s|w_i) p(s∣wi)越大越好。
p ( s ∣ w i ) = p ( w 1 , w 2 , ⋯ , w n ∣ w i ) = ∏ k p ( w k ∣ w i ) p(s|w_i)=p(w_1,w_2,\cdots,w_n|w_i)=\prod_k p(w_k|w_i) p(s∣wi)=p(w1,w2,⋯,wn∣wi)=k∏p(wk∣wi)
这样我们只需要计算出 p ( w k ∣ w i ) p(w_k|w_i) p(wk∣wi)就可以了。上面我们介绍了huffman树,想要求 p ( w k ∣ w j ) p(w_k|w_j) p(wk∣wj),就是求路径上每个节点的概率,我们有:
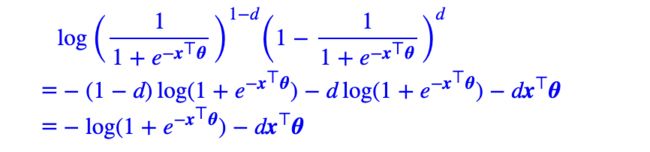
因此,我们可以将计算的最大的概率,作为关键词。
苏神给的链接:
链接: https://pan.baidu.com/s/1htC495U 密码: 4ff8
包含文件:word2vec_wx, word2vec_wx.syn1neg.npy, word2vec_wx.syn1.npy, word2vec_wx.wv.syn0.npy,4个文件都是Gensim加载模型所必需的。具体每个文件的含义我也没弄清楚,word2vec_wx大概是模型声明,word2vec_wx.wv.syn0.npy应该就是我们所说的词向量表,word2vec_wx.syn1.npy是隐层到输出层的参数(Huffman树的参数),word2vec_wx.syn1neg.npy就不大清楚了~
如果你只关心词向量,也可以下载C版本的格式(跟C版本Word2Vec兼容,只包含词向量):
链接: https://pan.baidu.com/s/1nv3ANLB 密码: dgfw
import numpy as np
import gensim
from collections import Counter
import pandas as pd
import jieba
model = gensim.models.word2vec.Word2Vec.load('your model path')
def predict_proba(oword, iword):
iword_vec = model[iword]
oword = model.wv.vocab[oword]
oword_l = model.syn1[oword.point].T # syn1有Huffman树的参数
dot = np.dot(iword_vec, oword_l)
lprob = -sum(np.logaddexp(0, -dot) + oword.code*dot)
return lprob
def keywords(s):
s = [w for w in s if w in model]
ws = {w:sum([predict_proba(u, w) for u in s]) for w in s}
return Counter(ws).most_common()
s = u'太阳是一颗恒星'
pd.Series(keywords(jieba.cut(s)))
word2vec keras 版代码
#! -*- coding:utf-8 -*-
#Keras版的Word2Vec,作者:苏剑林,http://kexue.fm
#Keras 2.0.6 + Tensorflow 测试通过
import numpy as np
from keras.layers import Input,Embedding,Lambda
from keras.models import Model
import keras.backend as K
word_size = 128 #词向量维度
window = 5 #窗口大小
nb_negative = 16 #随机负采样的样本数
min_count = 10 #频数少于min_count的词将会被抛弃
nb_worker = 4 #读取数据的并发数
nb_epoch = 2 #迭代次数,由于使用了adam,迭代次数1~2次效果就相当不错
subsample_t = 1e-5 #词频大于subsample_t的词语,会被降采样,这是提高速度和词向量质量的有效方案
nb_sentence_per_batch = 20
#目前是以句子为单位作为batch,多少个句子作为一个batch(这样才容易估计训练过程中的steps参数,另外注意,样本数是正比于字数的。)
import pymongo
class Sentences: #语料生成器,必须这样写才是可重复使用的
def __init__(self):
self.db = pymongo.MongoClient().weixin.text_articles
def __iter__(self):
for t in self.db.find(no_cursor_timeout=True).limit(100000):
yield t['words'] #返回分词后的结果
sentences = Sentences()
words = {} #词频表
nb_sentence = 0 #总句子数
total = 0. #总词频
for d in sentences:
nb_sentence += 1
for w in d:
if w not in words:
words[w] = 0
words[w] += 1
total += 1
if nb_sentence % 10000 == 0:
print u'已经找到%s篇文章'%nb_sentence
words = {i:j for i,j in words.items() if j >= min_count} #截断词频
id2word = {i+1:j for i,j in enumerate(words)} #id到词语的映射,0表示UNK
word2id = {j:i for i,j in id2word.items()} #词语到id的映射
nb_word = len(words)+1 #总词数(算上填充符号0)
subsamples = {i:j/total for i,j in words.items() if j/total > subsample_t}
subsamples = {i:subsample_t/j+(subsample_t/j)**0.5 for i,j in subsamples.items()} #这个降采样公式,是按照word2vec的源码来的
subsamples = {word2id[i]:j for i,j in subsamples.items() if j < 1.} #降采样表
def data_generator(): #训练数据生成器
while True:
x,y = [],[]
_ = 0
for d in sentences:
d = [0]*window + [word2id[w] for w in d if w in word2id] + [0]*window
r = np.random.random(len(d))
for i in range(window, len(d)-window):
if d[i] in subsamples and r[i] > subsamples[d[i]]: #满足降采样条件的直接跳过
continue
x.append(d[i-window:i]+d[i+1:i+1+window])
y.append([d[i]])
_ += 1
if _ == nb_sentence_per_batch:
x,y = np.array(x),np.array(y)
z = np.zeros((len(x), 1))
yield [x,y],z
x,y = [],[]
_ = 0
#CBOW输入
input_words = Input(shape=(window*2,), dtype='int32')
input_vecs = Embedding(nb_word, word_size, name='word2vec')(input_words)
input_vecs_sum = Lambda(lambda x: K.sum(x, axis=1))(input_vecs) #CBOW模型,直接将上下文词向量求和
#构造随机负样本,与目标组成抽样
target_word = Input(shape=(1,), dtype='int32')
negatives = Lambda(lambda x: K.random_uniform((K.shape(x)[0], nb_negative), 0, nb_word, 'int32'))(target_word)
samples = Lambda(lambda x: K.concatenate(x))([target_word,negatives]) #构造抽样,负样本随机抽。负样本也可能抽到正样本,但概率小。
#只在抽样内做Dense和softmax
softmax_weights = Embedding(nb_word, word_size, name='W')(samples)
softmax_biases = Embedding(nb_word, 1, name='b')(samples)
softmax = Lambda(lambda x:
K.softmax((K.batch_dot(x[0], K.expand_dims(x[1],2))+x[2])[:,:,0])
)([softmax_weights,input_vecs_sum,softmax_biases]) #用Embedding层存参数,用K后端实现矩阵乘法,以此复现Dense层的功能
#留意到,我们构造抽样时,把目标放在了第一位,也就是说,softmax的目标id总是0,这可以从data_generator中的z变量的写法可以看出
model = Model(inputs=[input_words,target_word], outputs=softmax)
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
#请留意用的是sparse_categorical_crossentropy而不是categorical_crossentropy
model.fit_generator(data_generator(),
steps_per_epoch=nb_sentence/nb_sentence_per_batch,
epochs=nb_epoch,
workers=nb_worker,
use_multiprocessing=True
)
model.save_weights('word2vec.model')
#通过词语相似度,检查我们的词向量是不是靠谱的
embeddings = model.get_weights()[0]
normalized_embeddings = embeddings / (embeddings**2).sum(axis=1).reshape((-1,1))**0.5
def most_similar(w):
v = normalized_embeddings[word2id[w]]
sims = np.dot(normalized_embeddings, v)
sort = sims.argsort()[::-1]
sort = sort[sort > 0]
return [(id2word[i],sims[i]) for i in sort[:10]]
import pandas as pd
pd.Series(most_similar(u'科学'))