场景生成及编辑&3D定位论文阅读
前置知识
归纳偏置
关于归纳偏置的理解:首先推荐一篇解释归纳偏置非常好的博客:浅谈归纳偏置 (InductiveBias)
通俗的,归纳偏置可以理解为,从现实生活中观察到的现象中归纳出一定的 规则(heuristics),然后对模型做一定的 约束,从而可以起到“模型选择” 的作用,类似贝叶斯学习中的“先验”。
机器学习中,很多学习算法经常会对学习的问题做一些关于目标函数的必要假设,称为 归纳偏置 (InductiveBias)。也就是说我们在设计模型中,按照总结出的一些规则来设计,假设模型就应该这么做,那么就是为模型引入了归纳(inductive)出来的规则,使其具有了偏置(bias)。
归纳偏置会促使学习算法优先考虑具有某些属性的解,也因此使得学习器具有了泛化的能力。因为有时候一个问题有很多个可以拟合的解,但训练的模型必然存在一定的“偏好” 或者说 “倾向”,才能学习出模型自己认为正确的拟合规则。
例子有很多:
深度神经网络 偏好性地认为,层次化处理信息有更好效果;
卷积神经网络 认为信息具有空间局部性,可用滑动卷积共享权重的方式降低参数空间;
循环神经网络 则将时序信息纳入考虑,强调顺序重要性;图网络 则认为中心节点与邻居节点的相似性会更好地引导信息流动。
CNN 的 Inductive Bias 是 局部性 (Locality) 和 空间不变性 (Spatial Invariance) / 平移等效性 (Translation Equivariance),即空间位置上的元素 (Grid Elements) 的联系/相关性近大远小,以及空间 平移的不变性 (Kernel 权重共享) 。
RNN 的 Inductive Bias 是 序列性 (Sequentiality) 和 时间不变性 (Time Invariance),即序列顺序上的时间步 (Timesteps) 有联系,以及时间变换的不变性 (RNN 权重共享)。
注意力机制,也是基于从人的直觉、生活经验归纳得到的规则。
RPN网络(Region Proposal Network)
TODO
Transformer进一步理解

Transformer的decoder的第一个Multi-Head Attention是MaskedMulti-Head Attention的,为什么要mask,个人理解是为了使当前阶段模型的输入只看到上个阶段的预测,而非全局上下文(因为encoder中的MSA是可以看到全局上下文的),这样做的目的也可以理解为是为了防止标签泄露。
第二个Multi-HeadAttention就只是基于Attention,query是MaskedMulti-Head Attention输出的结果,以一句话来比喻,query就是当前的单词(只了解在此之前的信息),key、value是encoder的输出(整句话,全局信息),decoder的输出就是预测结果(未来的单词)
注意力机制中,key和value一般是相同的,query不同;自注意力机制中,query,key,value一般是相同的。
非自回归(Non-Autoregressive)
参考:Non-Autoregressive NMT 小结 (一)
Autoregressive Translation(AT)指的是在翻译目标语句时,模型是从左到右逐字翻译的,目标语句的长度是通过预测生成EOS符号隐式地定义的。RNN、sequence2sequence 和 Transformer都是自回归模型。
Non-Autoregressive Translation(NAT)模型无法动态地实现这一点,因此,NAT需要首先确定目标语句的长度,之后NAT模型再并行地生成目标语句的各个单词。
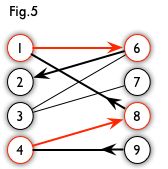
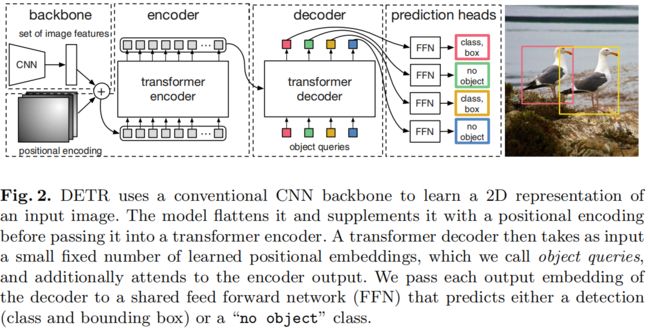
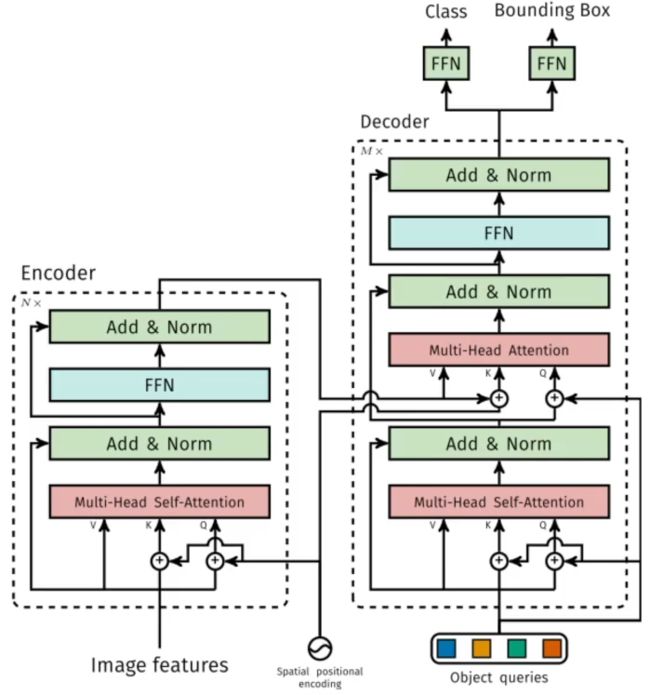
NAT和AT模型结构的异同:在Encoder端,二者完全相同;在Decoder端,训练时,AT模型的输入和输出都是目标语句 y ,NAT模型的输出是 y ,而输入是一个与 y 无关的变量。测试时,AT模型的输入是已经生成的目标单词 y 在了解匈牙利算法前,需要先了解 集合预测问题(Set Prediction),详细请参考:目标检测中的集合预测。通常“集合”预测任务是一种多标签分类问题。多标签分类问题的解决方法通常是“one-vs-rest”(“一对多”,one-vs-rest,又称one-vs-all, 这里指的是将label的类别作为“一”,将其余类别当做一个整体作为“多”,进行训练),这种方法不适用于“元素”间有底层关系结构的情况(“元素”e.g.几乎一模一样的预测框)。在目标检测中,集合预测就是输入一副图像,网络的输出就是最终的预测的集合(框,类别。也不需要任何后处理)。这种方式简单粗暴,从直觉上看会比基于滑动窗口的方式更难。基于滑窗的方式就像人为地给了一个梯子,帮助网络去越过障碍,而集合预测就更需要网络真正懂得图像的语义而直接越过障碍。带来的最大好处就是训练与预测变成真正的端到端,无需NMS的后处理,去除了人为设计的归纳偏置。 集合预测任务中最大的问题就是要避免near-duplicates。之前的一些检测器通过使用NMS这种后处理方法来解决,但是集合预测任务是postprocessing-free,它们需要全局推理方案来建模所有预测元素之间的交互,以避免冗余。这样的一个问题就是一个二分图匹配问题,求解二分图匹配问题常用的算法就是匈牙利算法。因此,通常的解决方案是设计一个基于匈牙利算法[1]的损失,以找到ground truth和prediction之间的双向匹配。 下面对图论中的一些概念进行补全(参考:二分图的最大匹配、完美匹配和匈牙利算法): 二分图:简单来说,如果图中点可以被分为两组,并且使得所有边都跨越组的边界,则这就是一个二分图。准确地说:把一个图的顶点划分为两个不相交集 U 和V ,使得每一条边都分别连接U、V中的顶点。如果存在这样的划分,则此图为一个二分图。图 1 是一个二分图。为了清晰,把它画成图 2 的形式。 匹配:在图论中,一个「匹配」(matching)是一个边的集合,其中任意两条边都没有公共顶点。例如,图 3、图 4 中红色的边就是图 2 的匹配。 我们定义匹配点、匹配边、未匹配点、非匹配边,它们的含义非常显然。例如图 3 中 1、4、5、7 为匹配点,其他顶点为未匹配点;1-5、4-7为匹配边,其他边为非匹配边。 交替路:从一个未匹配点出发,依次经过非匹配边、匹配边、非匹配边…形成的路径叫交替路。 增广路:从一个未匹配点出发,走交替路,如果途径另一个未匹配点(出发的点不算),则这条交替路称为增广路(agumenting path)。例如,图 5 中的一条增广路如图 6 所示(图中的匹配点均用红色标出): 增广路有一个重要特点:非匹配边比匹配边多一条。因此,研究增广路的意义是改进匹配。只要把增广路中的匹配边和非匹配边的身份交换即可。由于中间的匹配节点不存在其他相连的匹配边,所以这样做不会破坏匹配的性质。交换后,图中的匹配边数目比原来多了 1 条。 我们可以通过不停地找增广路来增加匹配中的匹配边和匹配点。找不到增广路时,达到最大匹配(这是增广路定理)。匈牙利算法正是这么做的。匈牙利树一般由 BFS(广度优先搜索) 构造(类似于 BFS 树)。从一个未匹配点出发运行 BFS(唯一的限制是,必须走交替路),直到不能再扩展为止,要求所有叶子节点均为匹配点 匈牙利算法的要点如下 从左边第 1 个顶点开始,挑选未匹配点进行搜索,寻找增广路。 如果经过一个未匹配点,说明寻找成功。更新路径信息,匹配边数 +1,停止搜索。 如果一直没有找到增广路,则不再从这个点开始搜索。事实上,此时搜索后会形成一棵匈牙利树。我们可以永久性地把它从图中删去,而不影响结果。 由于找到增广路之后需要沿着路径更新匹配,所以我们需要一个结构来记录路径上的点。DFS 版本通过函数调用隐式地使用一个栈,而 BFS 版本使用 prev 数组。 匈牙利算法的具体步骤,请参考:匈牙利算法 [1] Kuhn, H.W.: The Hungarian method for the assignment problem (1955) NeRF的成像是在相机视角位置成像的,也就是成像面是在光线发射位置。成像面(相机处)有h*w个像素,每个像素都有着对应的位置φ,伴随着相机内参,每个像素点也有着对应的观测方向θ。从这个像素点出发一条射线,中间可以采样n个点,每一个点都有一个空间坐标(x,y,z)。这样,所求图像的每一个像素都对应了一条射线,每条射线下有着n个输入(x, y, z, θ,φ),然后每一个点经过NeRF都会产生一个不透明度σ,和一个RGB值,将这条射线上点的不透明度从头开始累积到一定阈值,这一过程中的RGB的累积值就是所求图像上这一像素最后的颜色值。为每一个像素都执行以上过程,最终就合成了新视角下的图像。 NeRF原文的阅读笔记参考之前的博客:NeRF论文阅读笔记 Paper: https://openaccess.thecvf.com/content/CVPR2021/papers/Ost_Neural_Scene_Graphs_for_Dynamic_Scenes_CVPR_2021_paper.pdf Code: https://light.princeton.edu/publication/neural-scene-graphs/ 动机:Nerf等方法受限于学习静态场景的视角合成,缺乏表示dynamic scenes和将scenes分解为单独object的能力。也就是说最近的Nerf等方法将整个场景的所有对象都编码进一个单一的静态网络,在一个MLP里学习整个静态场景的完全隐式表示,他们不能够表示动态的场景以及分层的表示场景。因此在这篇文章中,作者称是首次提出来了一种神经渲染的方法,将多目标的动态场景表示为场景图,然后将一个场景的静态部分和动态部分进行解耦,分别对他们学习表示。最后实现了动态场景的视角合成,具体地讲就是只通过在这个场景的视频上训练,就可以合成在这个场景下,包含未见过目标的新的目标组合的视角。 所要实现的功能如下图: 方法:首先,为了分层地建模场景,作者将整个场景用一个有向无环的场景图来表示,(a)和)(b)是同一个场景图的等距视图和自车视角。这个场景图里,包含了一个相机节点C;一个静态节点,也就是背景,用Fbckg来表示;还有若干个动态目标的节点,就是这些框,他们分别用Fθ来学习,比如Fθcar/truck。在每个节点都有一个局部的坐标系,整个场景还有一个原点为W的全局坐标系。那么有了这些之后,对于一个给定的场景图,所有动态目标的pose和location就可以被提取出来,对于从原点W出发到动态目标或者相机的边,作者分配了一个变换矩阵T到这上面,我的理解就是旋转平移的变换矩阵。然后在这个等距视图中所有目标的尺度都是相等的,但是他们的真实尺寸并不相同,所以作者又在从这些节点指向他们对应的表示模型上分配了各自相应的缩放尺度。 对于每个节点的学习呢,作者同样是使用Nerf,但是稍微有些改进。 首先对于位置编码,作者使用了一种在NIPS2020中提出的傅里叶位置编码方法,来辅助在MLP中学习高频函数。 在对背景进行学习的时候,方式与初始的Nerf基本相同,输入就是射线上点的位置以及其观测方向,分两个阶段,第一个阶段输出不透明度,第二阶段预测颜色。 接下来对于动态场景的学习时,作者首先做的就是对于相似外貌的动态目标,作者将他们视为一个类别,使用同一个MLP来学习。这样做的目的是减小模型的计算量,否则为每一个目标都使用Nerf进行建模计算量太大。但是这样也会存在一个问题,即使这些目标外貌相似,但他们的细节肯定不同,因此作者在输入时增加了一个目标的潜向量l来加以区分。此外,动态目标的外貌依赖于它与环境和全局光照的交互,也就是取决于目标的姿态,但体素密度不应该随着姿态的改变而改变,因此作者又只在第二阶段加入了姿态。与加入观测方向d的方式一样。 在渲染时,也有一些细节,渲染过程如下: 在学习背景时,采样时,为了提升效率,采取了多平面采样:作者定义了平行于初始相机姿态的Ns个平面,并在近clip和远clip间等间距。然后对于一个ray,计算光线与这些平面的交点。 对于动态目标学习时:作者使用一个2018年在JCGT上提出的名为ray-box的方法来渲染。即对于每个与动态点有交点的ray,计算出与ray-box相交的入点与出点,在等距的采样Nd个点。作者表示,少量的等距点就足以在保持较短的渲染时间的同时准确地表示动态对象。 在每一条射线上,黑色的点表示静态节点,蓝色的点表示动态节点。也就是说,每个射线上,都在经过的每一个动态节点上采样了Nd个点,以及在Ns个平面上采样了Ns个交点。这些点的颜色和体素密度分别被相应的神经辐射场函数Fθ预测。 最后就是与初始Nerf一样,对这条线求积分来预测像素的的颜色。 思考:将场景中的object进行结构,用场景图表示,从而实现动态的object组合的合成。这一方式值得借鉴。 动机:目前图像合成很多工作是在二维中运行,忽略了我们的世界是三维的,没有考虑三维场景的构成。近年来,虽然 Nerf 已经在 3D 的图像生成方面实现了高分辨率的可控图像生成,但仅限于单物体的场景,并且在更复杂的真实世界图像生成方面的表现不尽人意。 做法:作者将场景表示为组合的Nerf,通过解耦一个场景的多个物体,再进行耦合,从而可以控制不同物体的合成。首先,作者将场景表示为一个合成生成的神经特征场(就是下图的隐式3D场景表示)。然后对于一个随机采样的相机,作者使用一个feature field来渲染出场景的一个特征图像,这个特征图像是低分辨率的,以节省时间和计算。然后使用一个2D CNN解码器将特征图像转换为RGB图像。 GIRAFFE 可以解开单个物体,并允许在场景中平移和旋转它们,以及改变相机的姿态。也可以将生成的场景从 single-object 扩展到 multi-object,即使训练数据中没有这样的素材。 图中的 feature field 可以理解与 Nerf 中的radiance field类似,二者的区别就是最后Nerf生成的是不透明度+颜色,feature field生成的是不透明度+feature,后面会讲到。 在本篇工作之前,有一篇工作叫GRAF,它提出了一个生成式的Nerf模型,从一组未设定pose的2D图像中生成出丰富外观和形状的图像。公式如公式三,其中Ms, Ma分别是形状和外貌的潜编码的维度。 在这篇工作中,作者相较于 GRAF 的改进就是将输出的 color c,变成了 feature f。将目标表示为 Generative Neural Feature Fields。 R^+表示不透明度。 其次,为了克服 NeRF 和 GRAF 中,无法将 background 和 object 分离开,从而去控制和增减物体,的不足,GIRAFFE 对场景中的每一个object (包括 background)引入了一个仿射变换 T={s,t,R} ,表示物体放置在场景中的位置和方向。这使得我们可以让物体与背景分离开,从而操纵物体在场景中的位置,也可以自由地增减物体。(6)表示将object上的点映射到scene space中。所以本文的方法可以表示为公式(7)。 回到这个大图中,网络前面的输入与Nerf的都相似,输入是光线上采样点的坐标和观测方向,添加上不同的形状、外貌和仿射变换后输入至各自的函数,得到解耦的feature fields。那对于解耦的目标和背景,如何再进行耦合呢?作者给出了一种简单且直观的方式:对多个feature fields进行耦合时,对于不透明度进行求和,对于feature使用各自的不透明度进行加权平均。作者称这种方式还保证了在bp的过程中梯度可以传播到每个实体。 因为作者将Nerf的输出从c改成了F,原先经过体素渲染后直接就可以得到H*W*3的图像,但是这里经过体素渲染后得到的是一个feature image,所以接下来作者又设置了一个2D渲染,就是刚才说的2D CNN 解码器,渲染成H*W*3的图像,最后生成的图像与采样的图像一同送入判别器进行训练。 GRAF: GIRAFFE: 对各种场景的解耦: 对各种属性的控制,以及增加物体: 生成训练集之外的物体: 改变背景和外观: 不足:模型的属性解耦能力仍然不够强,比如景前物体会被“附着”到背景上等等 动机:这篇文章也指出了,虽然有些工作(比如前两篇)是通过学习每个object的NeRF模型或将单个scene分解为前景object和背景来进行编辑,但是他们要么是特定于对象,要么是特定于场景,要么在合成时没有真实背景,这限制了他们的适用性。现在这些工作缺少的是是一个神经表示和模型,它允许表示多个真实的场景,同时允许直观的控制。如果这样的话,就可以保持神经渲染模型的逼真性和简单性,同时保持传统计算机图形表示(网格、体积和纹理)的通用性和直观控制。 Nerf以及相关工作对新视角合成任务是有效的,但是存在两个问题: 他们需要每个场景的训练; 场景由一个神经网络隐式表示,这使得不能进行编辑和操作。也就是说,这些模型是特定于场景的,并且缺乏3D场景表示,因此经典的编辑,如形状操作,或组合场景是不可能的。 因此,这篇文章提出了一个Control-NeRF,可以表征多个场景,并进行直观的控制和编辑。 本文的模型共同学习特定于场景的feature volume 和一个神经渲染网络,即NeRF。feature volume的可视化见最左边这个图,由于提出的feature volume是独立于渲染模型的,因此可以通过编辑场景对应的feature volume来操作和组合场景。也就是说,可以将编辑过的feature volume插入到渲染模型中,以合成高质量的新视图。 另外,该模型可以同时在多个场景上进行训练,为每个场景产生不同的场景表示,同时学习一个通用的渲染网络。 具体的是,他们沿着射线在feature volume上查询得到一个feature,然后将得到的feature放入Nerf中预测不透明度和颜色,他们Nerf的这一点有点像上篇中的一样,都是输入一个feature。在训练时,Volume和Nerf网络一同训练,然后在新视角生成时,将Nerf网络固定住,只训练Volume。 此外,由于在学每个场景是都会产生一个Volume,他们是独立于Nerf的,那颗可以直接对他们进行编辑和混合,如最右边所示。 Volume如何得到:对于每个场景,该模型都寻求学习一个体素表征Vs,WHD是空间分辨率,F是特征维度。 公式化如下,S表示三线性采样,作者称这个公式可以使一同训练体素。 结果可视化: 不足:这个工作略显粗糙,一些细节描述的不是很充分(如何生成volume?训练细节?) 可借鉴之处:生成一个独立于神经渲染网络的 volume representation 这点比较有意思,可以更方便的进行三维场景合成等编辑操作。 这个文章提出了一个问题:3D object localization in neural fields,即,在NeRF中进行目标定位。挑战主要在于:如何有效地利用NeRF表示中包含的几何信息,特别是利用NeRF表示的易缩放性。为此,作者提出了一个transformer-based network包含coarse和fine两条流分别从更宽和放大的视野来理解场景。因为在场景中定位一个目标,网络不仅应该关注目标本身,还应该利用周围有用的上下文信息,因此设计了两条流分别关注目标的上下文和细节。本文的动机是: 机器人在3D空间中的目标定位策略的选择,取决于所采用的感知模型的类型和底层环境表示。有些使用2D相机构造2D图像,因此可以选取2D目标定位方法;有些为了估计目标姿态,构造了3D地图(表征为点云或体素等),因此可以用3D CNN等方法来处理数据;但与2D图像相比,3D地图包含了3D拓扑和丰富的几何信息,这可以促进机器人理解场景和更好做决策。 也就是说,对场景的表征,3D比2D可以更好帮助机器人完成任务。但用传统的点云、体素等元素表征3D场景又存在着许多限制。这些传统的三维表征缺乏辐射细节(颜色,照明等),这对目标定位是重要的,并且这些传统的模式是稀疏或者不完整的。因此机器人基于点云或体素的模型,无法像人类那样利用目标真实的结构和外貌。 近些年,NeRF将一个连续的3D场景压缩在前馈神经网络里,存储了每个3D位置的密度和辐射值(这里的辐射值可以理解为颜色)。相对于传统的3D表示方法,NeRF更紧凑且包含更多逼真的元素。但是,传统的目标定位方法无法应用于这种scene representation中,此外, NeRF在SLAM[2]、机器人运动规划[3]、操作[4]中已被应用,但运动规划的前提是知道目标在哪个位置,而目前在NeRF中的目标定位问题却没有被很好的研究。 此外,目前并没有适合这一任务的数据集,即,既满足NeRF的表征,又包含目标的3D框。因此,作者基于Objection dataset [1] 制作了NeRFLocBench 数据集(即在NeRF数据集上制作了objects的3D bounding boxes)。 所以这篇文章的主要贡献如下: 提出了 object localization in a neural radiance world 问题。这对机器人感知场景,从而进行规划和控制,十分有帮助。 提出了NeRF-Loc 框架来利用神经表征中的几何信息进行3D目标定位。(这个坑与自己的想法类似,但已经被占了) 提出了第一个基于NeRF样本目标定位基准:NeRFLocBench 。 模型框架示意图如下,包含coarse、fine两个网络,分别从不同的尺度来处理信息,然后这两条流被注意力机制模块融合,之后再预测目标的3D Boxes。 目标定位问题综述:目标定位问题在自动驾驶、室内导航和机器人操作等领域中都有着重要的应用。以往的方法根据输入模态的类型大致可分为三类: Point-cloud based: 点云是直接在3D空间内通过LiDAR这种传感器获取目标表面点的坐标。虽然效果不错,但是设备比较昂贵。 Stereo image based: 基于双目图像的方法利用从双目图像对之间的差异中获得的几何结构。虽然成本不高,该方法需要相当长的baseline(两个相机之间的距离)才可以推测出准确的深度,这阻碍了在紧凑设备上的应用。 Monocular image based: 便携,成本低,在目标定位中比较受欢迎。 NeRF-Loc 具体网络框架如下: 算法如下:1)首先给定一个观测姿态P和相机的内参矩阵K(两条流,也就是Kc和Kf),和一个神经辐射场FΘ,那么则对从相机中心发射出光束的field values (i.e. colors and densities)进行采样;2)被采样的field values被输入至相应的 transformer encoder进行特征提取;3)两类抽取出的特征在注意力融合模块被融合;4)最后,融合后的特征被输入至 transformer decoder预测bounding-box的 corners and category. 输入和Encoder: 双流的不同尺度输入是如何实现的?通过改变焦距来改变相机采样范围,从而完成放大、缩小。然后在每个ray上均匀采样N个点,在辐射场中提取出各自的场值(c,σ)。实验表示,双流编码显著提高了定位性能。 输入网络的是什么形式的数据?输入transformer encoder的是两组 point sets,其中每个点的值就是在NeRF中对应的场值(c,σ)。这两组 point sets被两个线性层映射为embedding后分别输入各自的encoder。线性层中维度转换的细节没有提,但估计是:N*4 --> N*d。 Decoder: I是融合后的embedding,q是一个关于J目标形状的随机初始化的query。 数据集: 作者成建立了一个benchmark:NeRFLocBench。但它就是基于 Objectron 数据集[1]先训练出每个场景的NeRF表征,然后做一些粗/细粒度的采样,以及对应渲染出的图片和深度图。严格来说没有提出一个新的数据集。 总的来讲,这篇文章要做的就是:遇到一个新的场景后,我们首先用NeRF对这个场景进行表征,然后在NeRF表征中进行目标定位以辅助后续的机器人导航或操作,这种方式不需要其他数据。这篇主要讲的是如何在NeRF中进行定位,而不是对NeRF进行创新。在一个场景的NeRF训练完后,rgb图像、相机姿态这些数据在训练时都不再需要了。文章最后说,未来他们会在多目标下更复杂的NeRF场景继续探索目标定位任务。 随记: 本文是第一个提出object localization in a neural radiance world 坑的工作,但是方法比较简单。只是用两个相同架构的transformer decoder来对在3D场景下不同尺度采样出的点的值进行处理,中间加了一个融合层后再进行decoder出3Dbbox的框和类别。 网络框架还是3D 目标定位那一套,主要借鉴了 3DETR[5]。虽然本文对3D场景的表征变换了,但是本质上还是利用Transformer进行3D 目标检测那一套,输入进本文网络的数据也类似于点云数据,即在三维点云(x,y,z)的基础上加了两维,成为NeRF场景下的点(x, y, z,θ,φ)。 比较有意思的点: 使用双流网络充分利用NeRF表征的易缩放性:通过改变焦距来控制照片尺度,值得借鉴。 处理不同尺度的Transformer encoder或许可以权值共享?类似于孪生神经网络,使得模型可以同时incorporate multi-level scene? 在NeRF中进行目标定位的工作不多,并且十分具有意义,可以进行探索。但目前用于NeRF训练的场景比较单一,需要复杂场景(多目标)且带有3D bbox 标注的数据集。 3D目标定位的工作已经比较成熟,再改进已比较难,应该突破的点是如何让其与NeRF表征更适配?比如这篇文章就很好的利用了NeRF场景的易缩放性提出了双流网络。 [1] Adel Ahmadyan, Liangkai Zhang, Artsiom Ablavatski, Jianing Wei, and Matthias Grundmann. “Objectron: A Large Scale Dataset of Object-Centric Videos in the Wild with Pose Annotations”. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2021). [2] Zihan Zhu et al. “Nice-slam: Neural implicit scalable encoding for slam”. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022, pp. 12786–12796. [3] Michal Adamkiewicz et al. “Vision-only robot navigation in a neural radiance world”. In: IEEE Robotics and Automation Letters 7.2 (2022), pp. 4606–4613. [4] Jeffrey Ichnowski*, Yahav Avigal*, Justin Kerr, and Ken Goldberg. “Dex-NeRF: Using a Neural Radiance fifield to Grasp Transparent Objects”. In: Conference on Robot Learning (CoRL). 2020. [5] Ishan Misra, Rohit Girdhar, and Armand Joulin. “An End-to-End Transformer Model for 3D Object Detection”. In: ICCV. 2021. 3D obeject detection在自动驾驶和机器人技术中都是很重要的应用,目前可以被分类为Image-based和Point cloud-based。image-based 3D 目标检测方法可以分为使用单个图像或使用多个连续视角的图像。虽然后者使用多视图投影几何来组合三维空间中的信息,但他们仍然使用二维特征来指导相关的三维预测。Point cloud-based则严重依赖于传感器捕获的数据的质量。 3D obeject detection in NeRF 是 3D-to-3D learning的范式,可以充分利用NeRF中固有的三维信息,直接在三维空间中预测region proposal。NeRF可以从一个场景的多个视角图像produce出该场景的 voxel 或者 point cloud 表征。当然,与之前point cloud-based方法一样,NeRF重建场景中的噪声和几何质量也将会产生重要影响。此外,与point cloud-based方法不一样的是,NeRF中的点分布在整个实体内部,不像点云那样只覆盖在目标表面而且还存在背部无点的问题。 3D目标检测综述: RPN网络:TODO Point Cloud-based: 该方法的发展路线:Voxel representation(point clouds or RGB-D images) --> 3D feature volume (3D CNN or Transformer) --> Sparse convolution or 2D projection --> Operate directly on raw points. 这些方法的分类标准有:3D frustums extruded from 2D detection, 3D region proposals, and voting. Image-based:分为single image-based和multi-view image-based。最开始的方法大多是single image-based,他们尝试从单个RGB图像估计每个像素的深度、pseudo-LiDAR信号、voxel信息等,然后再重建的深度或三维特征上检测。最近的方法倾向于多视角的情况:ImVoxelNet将多个图像的特征映射到3D grid中,然后应用一个正常的 voxel-based 检测器来检测;DERT3D先预测3D参考点,然后将其映射到2D图像中来聚合图像特征;PETR直接将3D位置编码整合进2D特征图中。 网络整体框架如下:从NeRF中采样出来的值被输入至3D backbone,然后经过3D FPN网络和RPN头提出region proposals,最后通过NMS生成最终的3D bboxes。每一块的网络作者都没有设计,都是选取了当前几种主流的网络来进行消融实验,最后选择最好的。比如Anchor-Based RPNs基于Faster R-CNN, Anchor-Free RPNs基于FCOS。 数据集制作:作者从几个NeRF的数据集中手工标注了3D bboxes。 有意思的点: NeRF采样策略:经过一系列尝试,只使用密度是最好的策略。 场景编辑:得到proposals后,在渲染图像之前,可以将3D bbox内的体素密度设置为0,这样就可以实现场景编辑的效果。 随记: 这篇文章做的数据集是 indoor,有着连续的视角、相机姿态、多目标3D bboxes。那能否做一个其他场景下的数据集? 目前单目标场景用于object detection in NeRFs的数据集只有Objectron; 多目标场景的就是这篇文章提出的3D-FRONT NeRF 数据集,但是还没公布链接。应该是投CVPR2023,估计6月份才会开源。 这篇文章与上篇文章一样,网络部分都没有很好的设计,甚至这篇文章的网络还没有上一篇文章的网络有创新以更贴合NeRF的场景。NeRF场景下的“point cloud”与真实的3D point cloud不一样,真实的3D点云内部不包含点,且存在后部没有点的问题,或许可以从这一点出发来设计网络使得更模型更适合NeRF point。 NeRF模型包含的几何信息也很重要,上一章的一些文章通过一些方式为模型引入几何信息。或许在这篇文章中,也可以通过合理的方式注入几何信息?且更关键的是,或许可以无需NeRF,而是pure transformer-based,直接从多视角图像中重建出三维场景,然后随即生成proposal?这样的过程可能更方便三维重建阶段的transformer与3D检测阶段的transformer交互(更方便地注入几何信息等)? Paper: https://openaccess.thecvf.com/content/ICCV2021/papers/Misra_An_End-to-End_Transformer_Model_for_3D_Object_Detection_ICCV_2021_paper.pdf Code: https://github.com/facebookresearch/3detr Transformer应用于3D目标检测的开山之作。很多Transformer-based 3D目标检测的工作都是基于这篇进行魔改。 动机: 之前3D目标检测依赖于手工设计的归纳偏置 self-attention是置换不变的,能够捕获long range的上下文语义信息,故很适合处理无序的点云数据,也可以无需手工设计归纳偏置。 网络架构: 关键点: 利用PointNet++中的方法对点云降采样,N个点降为N′个。然后进行特征变换,直接送入encoder,不需要提供位置编码,因为点云信息已经蕴含了xyz坐标信息。 queryembeddings是non-parametric的。 具体:利用farthest pointsampling采样在ᵄ1′个输入点中得到ᵃ5个点,然后进行Fourier位置编码后,特征变换得到queryembedding。这样ᵃ5个点就会与ᵃ5个queryembedding相对应。Queryembedding表征着3d空间中接近objects的空间。 论文通过实验证明了,在3d点云中使用non-parametric queries的重要性。 相比于2d图像网格,点云更为稀疏和不规则,因此很难学习到parametric queries(nn.Embeddings)。Non-parametric queries从点云中直接采样学习到,因此能更少受点云的不规则性影响。 Paper: https://link.springer.com/chapter/10.1007/978-3-030-58452-8_13 Code: https://github.com/facebookresearch/detr 动机: 在目标检测任务中,此前的检测器大都先用手工设计的候选框预测方案,例如anchor或滑动框。这些方案也包含了其他先验知识的干涉,例如NMS等后处理方案、anchor的设计、训练时如何将检测结果与ground truth匹配等。这些先验知识其实就是为目标检测任务引入归纳偏置。本文通过将transformer融入模型,简化检测流程,跳过手工设计的部分,将问题转化为集合预测问题,以端到端的方式直接输出预测的(对象,框)的集合。 总体来讲DETR没有在单独网络模块上的创新,仅仅是在架构上的创新。核心就是将目标检测问题看作是 Set Prediciton问题,设计了并行解码的Transformer用于目标检测,搭配了二分匹配算法来计算loss。 主要贡献: Bipartite Matching(二分图匹配) 在Set Prediction问题中,损失函数必须满足“预测顺序不变性”(invariant by a permutation of the predictions,即预测值/框的顺序不能影响损失值),而二分图匹配——这里特指的是“无向”二分图匹配将“预测值→ground-truth值”的关系建模为了一个无向二分图,这种图的“匹配”不存在顺序问题。特别地,用“匈牙利算法”来求解二分图匹配问题。 因此,所提出的Bipartite Matching有以下两点好处: 能保证预测顺序不变性 能保证“prediction”与“ground truth”两者间一一匹配 基于并行解码Transformer的目标检测架构: Transformer的详细结构: object queries的长度是N,一开始我们对物体一无所知,所以queries是0向量,但是要加上positional embedding。 本文虽是2023,但是2015年修改稿,参考文献较老。
匈牙利算法(Hungarian algorithm)


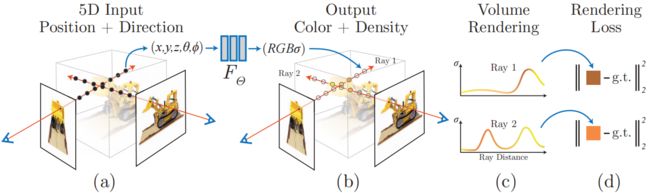
基于NeRF的新视角合成(Novel View Synthesis,NVS)
《Nerf: Representing scenes as neural radiance fields for view synthesis》【ECCV 2020】UC Berkeley+Google
2.《 pixelNeRF:Neural Radiance Fields from One or Few Images》【CVPR 2021】 UC Berkeley

基于NeRF的场景编辑及解耦
《Neural scene graphs for dynamic scenes》【CVPR 2021】 Algolux+慕尼黑工业+普林斯顿



《GIRAFFE: Representing Scenes as Compositional Generative Neural Feature Fields》【CVPR 2021 Best Paper】 图宾根+马普所


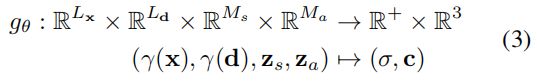





《Control-NeRF: Editable Feature Volumes for Scene Rendering and Manipulation》 【WACV 2023】马普所+图宾根


![]()
![]()
基于Transformer的新视角合成
《 ViewFormer:NeRF-freeNeural Rendering from Few Images Using Transformers》【ECCV 2022】捷克理工+代尔夫特理工

《 Scene Representation Transformer:Geometry-Free Novel View Synthesis Through Set-Latent SceneRepresentations》【CVPR 2022 】Google+西蒙弗雷泽大学

3.《 Geometry-biased Transformers for NovelView Synthesis》【arXiv2301】CMU



三维场景目标定位(Obeject Localization)
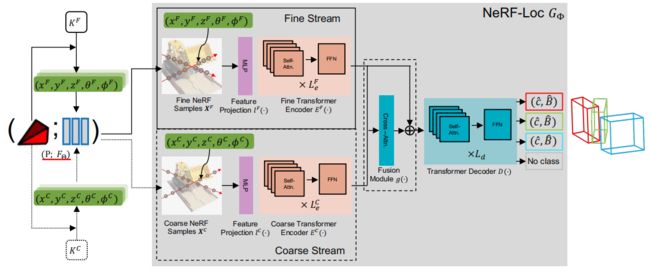
《 NeRF-Loc:Transformer-Based Object Localization Within Neural Radiance Fields》【arXiv2209】斯坦福+港中文


![]()
《 NeRF-RPN: A general framework for object detection in NeRFs》【arXiv 2211】港科+快手



《An End-to-End Transformer Model for 3D Object Detection》 【ICCV 2021】Facebook

《DE⫶TR: End-to-End Object Detection with Transformers》 【ECCV 2020】巴黎第九大学、Facebook AI Research
《 Explicit3D: Graph Network with SpatialInference for Single Image 3D Object Detection》【TMM 2022】清深
《Model-Agnostic Hierarchical Attention for 3D Object Detection》【arXiv 2301】马里兰大学、Salesforce Research、UT Austin
室内场景生成(Indoor Scene Synthesis)
《Sceneformer: Indoor scene generation with transformers》【3DV 2021】 慕尼黑工业大学
《SceneHGN: Hierarchical Graph Networks for 3D Indoor Scene Generation with Fine-Grained Geometry》【TPAMI 2023】国科大+斯坦福