1、业务团队使用Flink简要梳理
目录
1、Flink流式计算框架使用背景
2、Flink基础概念&原理
3、那么我们为什么选择 Flink
Flink是一个分布式、高性能、高可用、实时性的流式处理框架,支持实时的流处理和批处理;它统一了批处理和流处理,把批处理当做了流处理的一种特殊情况(和spark微批处理的区别),流处理数据无界,批处理数据有界。Flink根据固定缓存块进行网络数据传输,用户通过设定固定缓存块的超时值指定缓存块的传输时机(为0则是流处理标准模型,获得最低的延迟,无穷大则为批处理模式,获得最大的吞吐量);
当我们在使用Flink的时候,应该关注哪些核心的技术挑战点?
- Flink的Job作业是如何通过JobMaster调度的?任务是如何通过TaskExecutor执行的?资源是如何通过ResourceManager管理的?
- JobMaster作为作业的控制中心,它的主要职责包含了作业生命周期管理、任务调度、出错恢复、作业状态查询、分布式状态快照,这些职责的实现机制?
- TaskExecutor作为任务运行的容器,为各任务提供分层的memory管理,以及通过Task Slot进行资源的逻辑拆分;
- ResourceManager管理TaskExecutor,其中的slotmanager管理slot,slot的申请流程(JM—>RM—>TE—>JM,以slot offer的结果为准)?
- Flink基于state状态、三种时间(Processing Time|Event Time|Ingestion Time)、两种窗口(滑动、滚动)的统计方式?
1、Flink流式计算框架使用背景
因为目前云控负责的是路侧感应设备状态、交通事件、感知对象数据的监控,由路侧感应器设备数据的采集传输是通过Iot hub(基于mqtt二进制消息协议接入Iot设备+内置规则引擎路由消息到不同的存储介质,如kafka)完成的,云控平台监听Iothub输出到kafka主题设备相关数据作为数据源输入到flink流计算引擎中,并将读取到的监控数据做进一步的 聚合、转换、计算等操作,然后将计算结果推送到相应的业务各存储模块(tsdb、redis、mysql等)也可以再次转发kafka,。流程简图如下:

2、Flink基础概念&原理
这里可以先对flink相关的概念有一个初步的认识;聊flink前先对数据集类型和数据运算模型有初识;
数据集类型有哪些?
- 有界数据集:有限不会改变的数据集合
- 无界数据集:无穷的持续集成的数据集合;常见的有 应用实时产生的日志 | 金融市场的实时交易记录|Iot感应设备实时产生的数据
数据运算模型有哪些?
- native流式计算:只要数据一直在产生,计算就持续地进行 long running computation
- micro-batching批处理:在预先定义的时间内运行计算,当完成时释放计算机资源
Flink即可以处理有界数据、也可以处理无界数据,即支持native流式处理,也支持micro-batching的批处理;
2.1、What is Flink
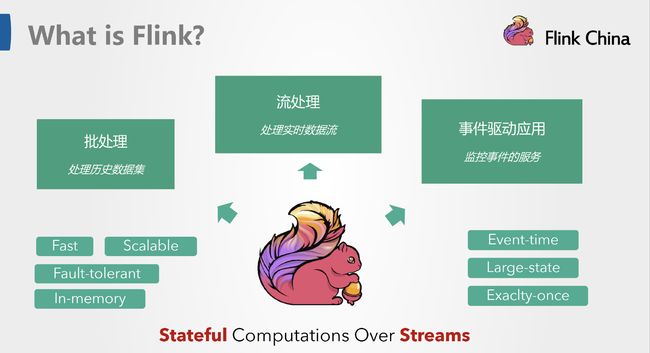

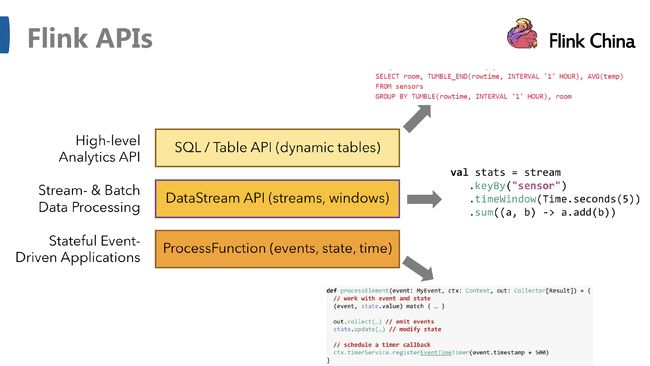
三张图摘自-云邪 成都站 《Flink 技术介绍与未来展望》,图一对flink的基本概念做了阐述,图二是flink的四个核心解决方案、基石,图三flink的几类api;
2.2、Flink的整体架构
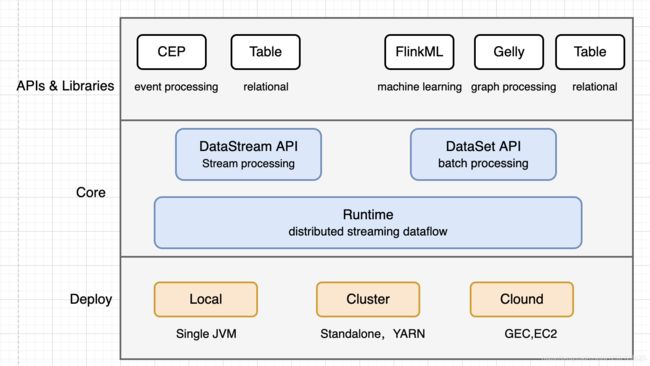
自下而上
- 部署:flink支持本地运行、能在独立集群或者被YARN或者Mesos管理的集群上运行、也能部署在云上;
- 运行:flink是一个分布式流式处理引擎,一次一个event的形式被处理;
- API:DataStream(流)、DataSet(批)、Table(表)、SQL API
- 扩展库: Flink包括用于复杂事件处理的CEP,机器学习(FlinkML),图形处理(Gelly)和Apache Storm兼容性的专用代码库;
2.3、Flink数据流编程模型
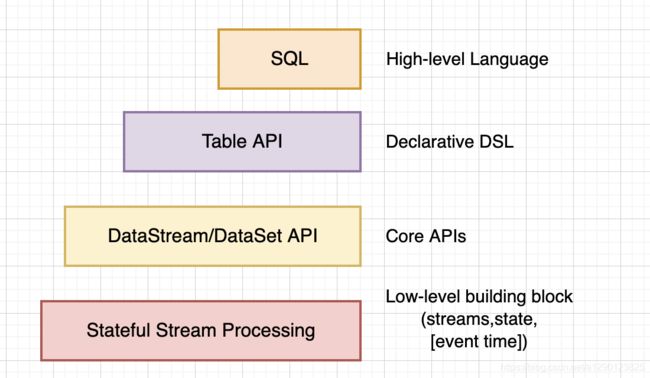
- 最底层提供了有状态流。它将通过 过程函数(Process Function)嵌入到 DataStream API 中。它允许用户可以自由地处理来自一个或多个流数据的事件,并使用一致、容错的状态。除此之外,用户可以注册事件时间和处理事件回调,从而使程序可以实现复杂的计算。
- DataStream / DataSet API 是 Flink 提供的核心 API ,DataSet 处理有界的数据集,DataStream 处理有界或者无界的数据流。用户可以通过各种方法(map / flatmap / window / keyby / sum / max / min / avg / join 等)将数据进行转换 / 计算。
- Table API 是以 表 为中心的声明式 DSL,其中表可能会动态变化(在表达流数据时)。Table API 提供了例如 select、project、join、group-by、aggregate 等操作,使用起来却更加简洁(代码量更少)。你可以在表与 DataStream/DataSet 之间无缝切换,也允许程序将 Table API 与 DataStream 以及 DataSet 混合使用。
- Flink 提供的最高层级的抽象是 SQL 。这一层抽象在语法与表达能力上与 Table API 类似,但是是以 SQL查询表达式的形式表现程序。SQL 抽象与 Table API 交互密切,同时 SQL 查询可以直接在 Table API 定义的表上执行。
2.4、Flink程序于数据流结构
以云控感应设备数据量统计为例
public class ObstacleStreamingJob {
private static final Logger logger = LoggerFactory.getLogger("ObstacleStreaming");
// RSCU基础数据维度表
public static Map> deviceMap = new ConcurrentHashMap<>();
// Side Output分流OutTag标识-写TSDB
private final static OutputTag sideOutTag_writeTSDB = new OutputTag("KafkaInput1") {
};
// Side Output分流OutTag标识-写Redis
private final static OutputTag sideOutTag_writeRedis = new OutputTag("KafkaInput2") {
};
// Side Output分流OutTag标识-写Kafka
private final static OutputTag sideOutTag_writeKafka = new OutputTag("KafkaInput3") {
};
// 设备配置信息广播流载体描述符
private final static MapStateDescriptor>> BROADCAST_DEVICE_CONFIG =
new MapStateDescriptor(
"broadcast-device-config",
BasicTypeInfo.STRING_TYPE_INFO,
new MapTypeInfo(String.class, Tuple4.class));
public static void main(String[] args) {
try {
// 设置Stream的运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironmentUtils.buildDefaultStreamExeEnv2();
// 每5s将RSCU/RSU设备信息,广播到所有分区并行实例
BroadcastStream>> deviceStreamToBroadcast = env
.addSource(new DeviceJdbcReader())
// 广播流设置并行度为1,避免主数据流收到并行发送的多条设备配置数据
.setParallelism(1).broadcast(BROADCAST_DEVICE_CONFIG);
SingleOutputStreamOperator sideOutputStream = env
.addSource(ObstacleKafkaSource.obsSource())
.connect(deviceStreamToBroadcast)
.process(new BroadcastProcessFunction>, RscuObstacles>() {
/**
* 处理主数据流\并分流
* @param input
* @param ctx
* @param collector
* @throws Exception
*/
@Override
public void processElement(RscuObstacles input, ReadOnlyContext ctx, Collector collector) throws Exception {
HeapBroadcastState>> deviceConfigMap =
(HeapBroadcastState) ctx.getBroadcastState(BROADCAST_DEVICE_CONFIG);
Map> map = deviceConfigMap.get("deviceMap");
ctx.output(sideOutTag_writeTSDB, input);
ctx.output(sideOutTag_writeRedis, input);
ctx.output(sideOutTag_writeKafka, input);
if (!DeviceConfigFilter.filter(input, map)) {
return;
}
deviceMap.putAll(map);
logger.debug("process mainstream deviceConfigMap:{},deviceMap:{}", deviceConfigMap,
deviceMap);
}
/**
* 处理广播数据流
* @param tuple4Map
* @param ctx
* @param collector
* @throws Exception
*/
@Override
public void processBroadcastElement(Map> tuple4Map,
Context ctx, Collector collector) throws Exception {
logger.debug("receive broadcast msg:{}", tuple4Map);
BroadcastState>> state =
ctx.getBroadcastState(BROADCAST_DEVICE_CONFIG);
state.put("deviceMap", tuple4Map);
}
}).name("SideOutProcess");
// 处理写kafka流(配置开关开启)
if (PropertiesUtil.getObstacleKafkaPushSwitch()) {
sideOutputStream.getSideOutput(sideOutTag_writeKafka)
// 上报频率为16hz,降频为4hz,每250ms抽取一帧数据发送
.timeWindowAll(Time.milliseconds(250))
.process(new ProcessAllWindowFunction() {
@Override
public void process(Context ct, Iterable it,
Collector cl) throws Exception {
if (it.iterator().hasNext()) {
RscuObstacles obstacles = it.iterator().next();
cl.collect(obstacles);
}
}
})
.addSink(ObstacleSendKafkaSink.obsSink())
.name("ObstacleKafka");
}
// 处理写入TSDB流
sideOutputStream.getSideOutput(sideOutTag_writeTSDB)
.map((value) -> {
logger.debug("value={},deviceMap={}", value, deviceMap);
String rscuSn = value.getAreaMap().getRscuId().toStringUtf8();
HashMap tags = new HashMap<>();
if (MapUtils.isNotEmpty(deviceMap)) {
String county = deviceMap.get(rscuSn).t1();
String province = deviceMap.get(rscuSn).t2();
String city = deviceMap.get(rscuSn).t3();
String roadType = deviceMap.get(rscuSn).t4().toString();
tags.put(Constants.RSCU_ID, rscuSn);
tags.put(Constants.CITY, city);
tags.put(Constants.DATA_SOURCE, Constants.DS_REAL);
tags.put(Constants.PROVINCE, province);
tags.put(Constants.COUNTY, county);
tags.put(Constants.ROAD_TYPE, roadType);
}
Datapoint dataPoint = new Datapoint().withMetric(Constants.obstacles).withTags(tags).withField(
Constants.obstacle)
.addBytesValue(System.currentTimeMillis(), value.toByteArray());
logger.debug("dataPoint={}", dataPoint);
return dataPoint;
})
.timeWindowAll(Time.seconds(1))
.process(new ProcessAllWindowFunction, TimeWindow>() {
@Override
public void process(Context context, Iterable iterable,
Collector> collector) throws Exception {
List arrayList = new ArrayList<>();
iterable.forEach(arrayList::add);
if (CollectionUtils.isNotEmpty(arrayList)) {
collector.collect(arrayList);
}
}
})
.addSink(ObstacleTSDBSink.tsdbSink());
// 处理写入Redis
sideOutputStream.getSideOutput(sideOutTag_writeRedis)
.map(new ObstacleMapRedis())
.addSink(new ObstacleRedisSink());
// 执行job
env.execute("Obstacle Streaming Job");
} catch (Exception e) {
logger.error("ObstacleStreamingJob Fail!", e);
}
}
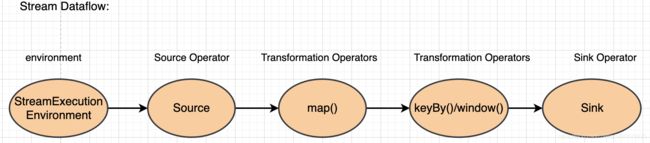
Flink 应用程序结构就是如上图所示:
- StreamExecutionEnvironment:构建一个流的运行环境 ;包括指定checkpoint机制配置;
- Source: 数据源,Flink 在流处理和批处理上的 source 大概有 4 类:基于本地集合的 source、基于文件的 source、基于网络套接字的 source、自定义的 source。自定义的 source 常见的有 Apache kafka、Amazon Kinesis Streams、RabbitMQ、Twitter Streaming API、Apache NiFi 等,当然你也可以定义自己的 source。
- Transformation:数据转换的各种操作,有 Map / FlatMap / Filter / KeyBy / Reduce / Fold / Aggregations / Window / WindowAll / Union / Window join / Split / Select / Project 等,操作很多,可以将数据转换计算成你想要的数据。
- Sink:接收器,Flink 将转换计算后的数据发送的地点 ,你可能需要存储下来,Flink 常见的 Sink 大概有如下几类:写入文件、打印出来、写入 socket 、自定义的 sink 。自定义的 sink 常见的有 Apache kafka、RabbitMQ、MySQL、ElasticSearch、Apache Cassandra、Hadoop FileSystem 等,同理你也可以定义自己的 sink。
2.5、CheckPoint 设置机制&案例
-
checkPoint:是一种状态容错机制,包含两部分状态备份和状态恢复,可以定义chepoint实现,通过在Sink中实现CheckPointedFunction接口的两个方法,一个是snapshotState,一个是initializeState,它们俩英文直译过来就已经非常的通俗易懂了。一个是对state进行快照,一个是故障时恢复初始化state;实际中我们一般不会自定义,flink提供了状态备份、恢复各自的几种机制;
-
stateBackend:状态备份flink提供了3种。。
(1)、MemoryStateBackend:状态信息是存储在 TaskManager 的堆内存中的,checkpoint 的时候将状态保存到 JobManager 的堆内存中
(2)、FsStateBackend:对于上一个MemoryStateBackend来说进行了一些优化,它的TaskManager会定期地把state存到HDFS上。也就是checkpoint 的时候将状态保存到指定的文件中 (HDFS 等文件系统);
注意:状态大小受TaskManager内存限制(默认支持5M,可以配置),如果在存入HDFS之前,内存中的数据就已经超过这个值的大小,那数据也还是会丢失的。优点就是对内存操作,状态访问速度很快
(3)、RocksDBStateBackend:状态信息存储在 RocksDB 数据库 (key-value 的数据存储服务);注意:状态访问速度相比FsStateBackend有所下降。优点:可以存储超大量的状态信息,因为这个也是分布式的;
-
restart-strategy:状态数据恢复flink提供了3种策略。。
(1)、固定间隔策略 (Fixed delay):RestartStrategies.fixedDelayRestart(5,Time.of(10, TimeUnit.SECONDS),第一个参数-最大尝试重启次数,第二个参数-重启间隔
(2)、失败率策略 (Failure rate):Job失败后会重启,但是超过失败率后,Job会最终被认定失败;RestartStrategies.failureRateRestart(5,Time.of(5, TimeUnit.MINUTES),Time.of(10,TimeUnit.SECONDS));第一参数 一个时间段内的最大失败次数,第二参数 衡量失败次数的是时间段,第三参数 重启间隔;
(3)、无重启 (No restart):任务失败不会恢复重启;
//获取flink的运行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 每隔1000 ms进行启动一个检查点【设置checkpoint的周期】 env.enableCheckpointing(1000); // 高级选项: // 设置模式为exactly-once (这是默认值) env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); // 确保检查点之间有至少500 ms的间隔【checkpoint最小间隔】 env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500); // 检查点必须在一分钟内完成,或者被丢弃【checkpoint的超时时间】 env.getCheckpointConfig().setCheckpointTimeout(60000); // 同一时间只允许进行一个检查点 env.getCheckpointConfig().setMaxConcurrentCheckpoints(1); // 表示一旦Flink处理程序被cancel后,会保留Checkpoint数据,以便根据实际需要恢复到指定的Checkpoint【详细解释见备注】 // ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION:表示一旦Flink处理程序被cancel后,会保留Checkpoint数据,以便根据实际需要恢复到指定的Checkpoint // ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION: 表示一旦Flink处理程序被cancel后,会删除Checkpoint数据,只有job执行失败的时候才会保存checkpoint env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION); //设置statebackend env.setStateBackend(new MemoryStateBackend()); //env.setStateBackend(new FsStateBackend("hdfs://hadoop100:9000/flink/checkpoints")); //env.setStateBackend(new RocksDBStateBackend("hdfs://hadoop100:9000/flink/checkpoints",true));如果没有启用 checkpointing,则使用无重启 (no restart) 策略;如果启用了 checkpointing,但没有配置重启策略,则使用固定间隔 (fixed-delay) 策略;重启策略,可以在flink-conf.yaml中配置,表示全局的配置;也可以如下在应用代码中动态指定;
Flink 保证状态化计算强一致性。”状态化“意味着应用可以维护随着时间推移已经产生的数据聚合或者,并且 Filnk 的检查点机制在一次失败的事件中一个应用状态的强一致性。
2.6、Flink的分布式运行
flink 作业提交架构流程可见下图:
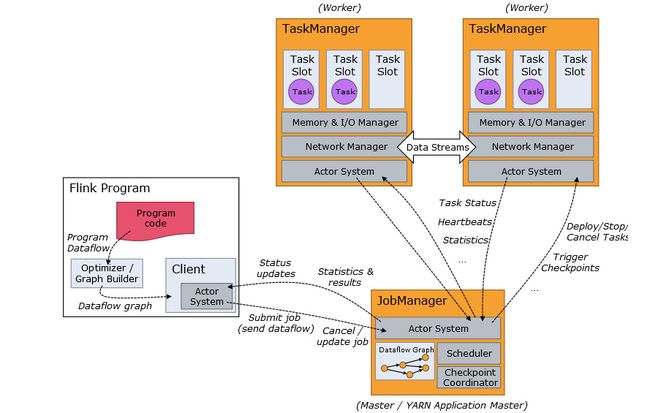
- Program Code:我们编写的 Flink 应用程序代码
- Job Client:Job Client 不是 Flink 程序执行的内部部分,但它是任务执行的起点。 Job Client 负责接受用户的程序代码,然后创建数据流,将数据流提交给 Job Manager 以便进一步执行。 执行完成后,Job Client 将结果返回给用户
- Job Manager:主进程(也称为作业管理器)协调和管理程序的执行。 它的主要职责包括安排任务,管理checkpoint ,故障恢复等。机器集群中至少要有一个 master,master 负责调度 task,协调 checkpoints 和容灾,高可用设置的话可以有多个 master,但要保证一个是 leader, 其他是 standby; Job Manager 包含 Actor system、Scheduler、Check pointing 三个重要的组件
- Task Manager:从 Job Manager 处接收需要部署的 Task。Task Manager 是在 JVM 中的一个或多个线程中执行任务的工作节点。 任务执行的并行性由每个 Task Manager 上可用的任务槽决定。 每个任务代表分配给任务槽的一组资源。 例如,如果 Task Manager 有四个插槽,那么它将为每个插槽分配 25% 的内存。 可以在任务槽中运行一个或多个线程。 同一插槽中的线程共享相同的 JVM。 同一 JVM 中的任务共享 TCP 连接和心跳消息。Task Manager 的一个 Slot 代表一个可用线程,该线程具有固定的内存,注意 Slot 只对内存隔离,没有对 CPU 隔离。默认情况下,Flink 允许子任务共享 Slot,即使它们是不同 task 的 subtask,只要它们来自相同的 job。这种共享可以有更好的资源利用率。
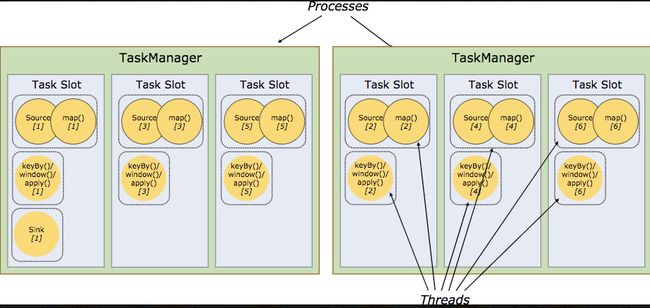
2.7、Flink的slot和parallelism
参考:flink的slot和parallelism- https://zhuanlan.zhihu.com/p/92721430
2.8、Flink的wartermark
参考:flink的wartermark-https://cloud.tencent.com/developer/article/1629585
3、那么我们为什么选择 Flink
Flink 作为一个开源的分布式流式处理框架:
①提供准确的结果,甚至在出现无序或者延迟加载的数据的情况下。
②它是状态化的容错的,同时在维护一次完整的的应用状态时,能无缝修复错误。
③大规模运行,在上千个节点运行时有很好的吞吐量和低延迟。
推荐几篇重要参考文档:
flink的序列化框架- https://juejin.im/post/6844903985309024270
flink的原理、实战、性能优化- https://zhuanlan.zhihu.com/p/147681677
flink的slot和parallelism- https://zhuanlan.zhihu.com/p/92721430
flink的stateBackend&checkpoint机制-https://juejin.im/post/6844904147494371342
flink的wartermark-https://cloud.tencent.com/developer/article/1629585